 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Predictive Control with Deep Koopman Operators for Autonomous Vehicle Motion Planning
Jun 06, 2026Model Predictive Control (MPC) is widely used for autonomous-vehicle (AV) motion planning, but its real-time applicability is often limited by the need for accurate models and online solution of nonlinear, nonconvex optimization problems in dynamic road environments. Actor-critic reinforcement learning offers a promising alternative for online policy generation, yet its policy-learning process often lacks explicit control-theoretic structure. This article proposes a learning predictive control (LPC) framework with deep Koopman operators for efficient real-time motion planning under nonconvex constraints. To address nonlinear and uncertain vehicle dynamics, a deep-Koopman-based predictor is used to lift the system into an interpretable linear observable space in a data-driven manner. Unlike traditional MPC, which computes open-loop control sequences, the proposed LPC framework yields a closed-loop state-feedback policy within each prediction interval through receding-horizon actor-critic learning. To ensure safety under nonconvex environmental constraints, LPC constructs convex local surrogate representations of obstacles and defines corresponding potential-field functions. These functions and their gradients are directly embedded into the actor-critic structure, enabling efficient, safety-aware policy learning. Extensive simulations and real-world experiments on the HongQi-EHS3 platform demonstrate favorable performance in diverse obstacle-avoidance scenarios in terms of safety, computational efficiency, and driving comfort, compared with benchmark methods such as CBF-MPC and LMPCC.
Diffusion Policies with Value-Conditional Optimization for Offline Reinforcement Learning
Nov 12, 2025
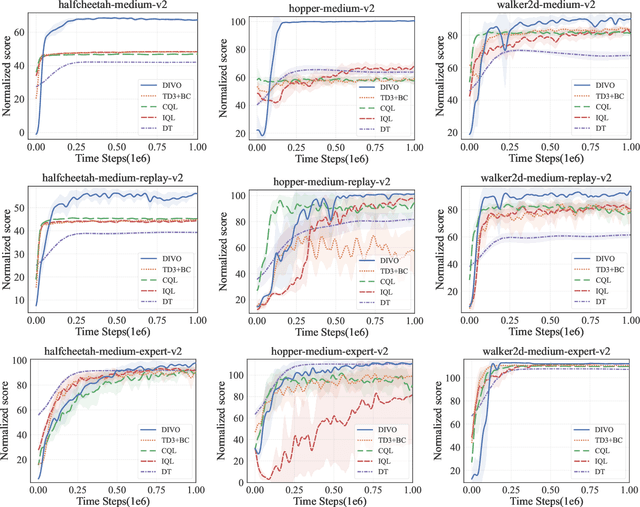

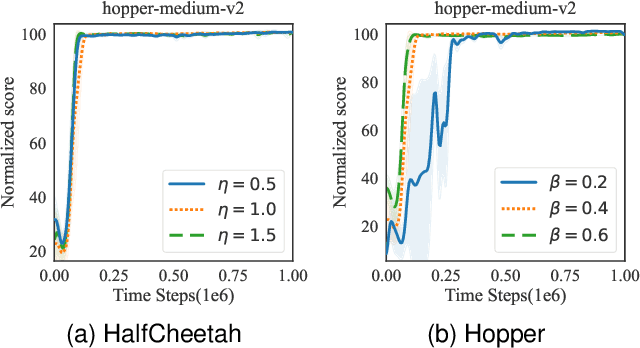
In offline reinforcement learning, value overestimation caused by out-of-distribution (OOD) actions significantly limits policy performance. Recently, diffusion models have been leveraged for their strong distribution-matching capabilities, enforcing conservatism through behavior policy constraints. However, existing methods often apply indiscriminate regularization to redundant actions in low-quality datasets, resulting in excessive conservatism and an imbalance between the expressiveness and efficiency of diffusion modeling. To address these issues, we propose DIffusion policies with Value-conditional Optimization (DIVO), a novel approach that leverages diffusion models to generate high-quality, broadly covered in-distribution state-action samples while facilitating efficient policy improvement. Specifically, DIVO introduces a binary-weighted mechanism that utilizes the advantage values of actions in the offline dataset to guide diffusion model training. This enables a more precise alignment with the dataset's distribution while selectively expanding the boundaries of high-advantage actions. During policy improvement, DIVO dynamically filters high-return-potential actions from the diffusion model, effectively guiding the learned policy toward better performance. This approach achieves a critical balance between conservatism and explorability in offline RL. We evaluate DIVO on the D4RL benchmark and compare it against state-of-the-art baselines. Empirical results demonstrate that DIVO achieves superior performance, delivering significant improvements in average returns across locomotion tasks and outperforming existing methods in the challenging AntMaze domain, where sparse rewards pose a major difficulty.
Learning to Align Human Code Preferences
Jul 27, 2025Large Language Models (LLMs) have demonstrated remarkable potential in automating software development tasks. While recent advances leverage Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to align models with human preferences, the optimal training strategy remains unclear across diverse code preference scenarios. This paper systematically investigates the roles of SFT and DPO in aligning LLMs with different code preferences. Through both theoretical analysis and empirical observation, we hypothesize that SFT excels in scenarios with objectively verifiable optimal solutions, while applying SFT followed by DPO (S&D) enables models to explore superior solutions in scenarios without objectively verifiable optimal solutions. Based on the analysis and experimental evidence, we propose Adaptive Preference Optimization (APO), a dynamic integration approach that adaptively amplifies preferred responses, suppresses dispreferred ones, and encourages exploration of potentially superior solutions during training. Extensive experiments across six representative code preference tasks validate our theoretical hypotheses and demonstrate that APO consistently matches or surpasses the performance of existing SFT and S&D strategies. Our work provides both theoretical foundations and practical guidance for selecting appropriate training strategies in different code preference alignment scenarios.
SepPrune: Structured Pruning for Efficient Deep Speech Separation
May 17, 2025Although deep learning has substantially advanced speech separation in recent years, most existing studies continue to prioritize separation quality while overlooking computational efficiency, an essential factor for low-latency speech processing in real-time applications. In this paper, we propose SepPrune, the first structured pruning framework specifically designed to compress deep speech separation models and reduce their computational cost. SepPrune begins by analyzing the computational structure of a given model to identify layers with the highest computational burden. It then introduces a differentiable masking strategy to enable gradient-driven channel selection. Based on the learned masks, SepPrune prunes redundant channels and fine-tunes the remaining parameters to recover performance. Extensive experiments demonstrate that this learnable pruning paradigm yields substantial advantages for channel pruning in speech separation models, outperforming existing methods. Notably, a model pruned with SepPrune can recover 85% of the performance of a pre-trained model (trained over hundreds of epochs) with only one epoch of fine-tuning, and achieves convergence 36$\times$ faster than training from scratch. Code is available at https://github.com/itsnotacie/SepPrune.
Reasoning to Attend: Try to Understand How <SEG> Token Works
Dec 23, 2024Current Large Multimodal Models (LMMs) empowered visual grounding typically rely on $\texttt{<SEG>}$ token as a text prompt to jointly optimize the vision-language model (e.g., LLaVA) and the downstream task-specified model (\eg, SAM). However, we observe that little research has looked into how it works.In this work, we first visualize the similarity maps, which are obtained by computing the semantic similarity between the $\texttt{<SEG>}$ token and the image token embeddings derived from the last hidden layer in both the LLaVA encoder and SAM decoder. Intriguingly, we have found that a striking consistency holds in terms of activation responses in the similarity map,which reveals that what $\texttt{<SEG>}$ token contributes to is the semantic similarity within image-text pairs. Specifically, $\texttt{<SEG>}$ token, a placeholder expanded in text vocabulary, extensively queries among individual tokenized image patches to match the semantics of an object from text to the paired image while the Large Language Models (LLMs) are being fine-tuned. Upon the above findings, we present READ, which facilitates LMMs' resilient $\textbf{REA}$soning capability of where to atten$\textbf{D}$ under the guidance of highly activated points borrowed from similarity maps. Remarkably, READ features an intuitive design, Similarity as Points module (SasP), which can be seamlessly applied to $\texttt{<SEG>}$-like paradigms in a plug-and-play fashion.Also, extensive experiments have been conducted on the ReasonSeg and RefCOCO(+/g) datasets. To validate whether READ suffers from catastrophic forgetting of previous skills after fine-tuning, we further assess its generation ability on an augmented FP-RefCOCO(+/g) dataset. All codes and models are publicly available at https://github.com/rui-qian/READ.
Learning-based Models for Vulnerability Detection: An Extensive Study
Aug 14, 2024Though many deep learning-based models have made great progress in vulnerability detection, we have no good understanding of these models, which limits the further advancement of model capability, understanding of the mechanism of model detection, and efficiency and safety of practical application of models. In this paper, we extensively and comprehensively investigate two types of state-of-the-art learning-based approaches (sequence-based and graph-based) by conducting experiments on a recently built large-scale dataset. We investigate seven research questions from five dimensions, namely model capabilities, model interpretation, model stability, ease of use of model, and model economy. We experimentally demonstrate the priority of sequence-based models and the limited abilities of both LLM (ChatGPT) and graph-based models. We explore the types of vulnerability that learning-based models skilled in and reveal the instability of the models though the input is subtlely semantical-equivalently changed. We empirically explain what the models have learned. We summarize the pre-processing as well as requirements for easily using the models. Finally, we initially induce the vital information for economically and safely practical usage of these models.
Rectifier: Code Translation with Corrector via LLMs
Jul 10, 2024Software migration is garnering increasing attention with the evolution of software and society. Early studies mainly relied on handcrafted translation rules to translate between two languages, the translation process is error-prone and time-consuming. In recent years, researchers have begun to explore the use of pre-trained large language models (LLMs) in code translation. However, code translation is a complex task that LLMs would generate mistakes during code translation, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). In this paper, we propose a general corrector, namely Rectifier, which is a micro and universal model for repairing translation errors. It learns from errors generated by existing LLMs and can be widely applied to correct errors generated by any LLM. The experimental results on translation tasks between C++, Java, and Python show that our model has effective repair ability, and cross experiments also demonstrate the robustness of our method.
Page-level Optimization of e-Commerce Item Recommendations
Aug 12, 2021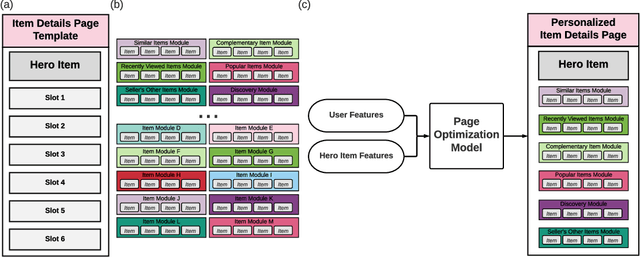

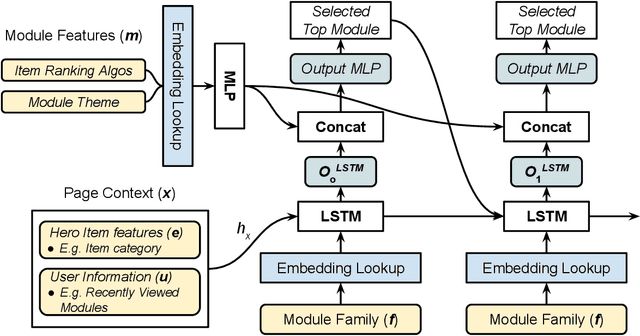

The item details page (IDP) is a web page on an e-commerce website that provides information on a specific product or item listing. Just below the details of the item on this page, the buyer can usually find recommendations for other relevant items. These are typically in the form of a series of modules or carousels, with each module containing a set of recommended items. The selection and ordering of these item recommendation modules are intended to increase discover-ability of relevant items and encourage greater user engagement, while simultaneously showcasing diversity of inventory and satisfying other business objectives. Item recommendation modules on the IDP are often curated and statically configured for all customers, ignoring opportunities for personalization. In this paper, we present a scalable end-to-end production system to optimize the personalized selection and ordering of item recommendation modules on the IDP in real-time by utilizing deep neural networks. Through extensive offline experimentation and online A/B testing, we show that our proposed system achieves significantly higher click-through and conversion rates compared to other existing methods. In our online A/B test, our framework improved click-through rate by 2.48% and purchase-through rate by 7.34% over a static configuration.
Filling the gap between GRACE- and GRACE-FO-derived terrestrial water storage anomalies with Bayesian convolutional neural networks
Jan 21, 2021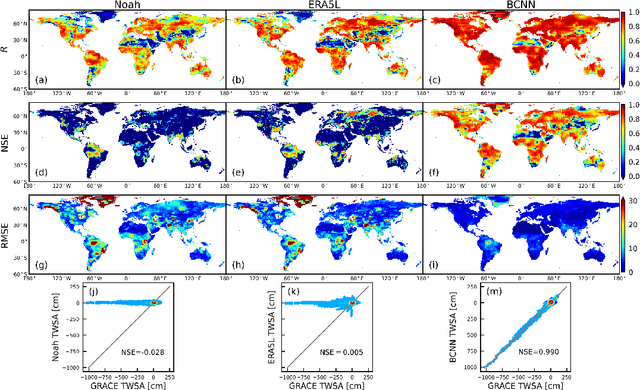
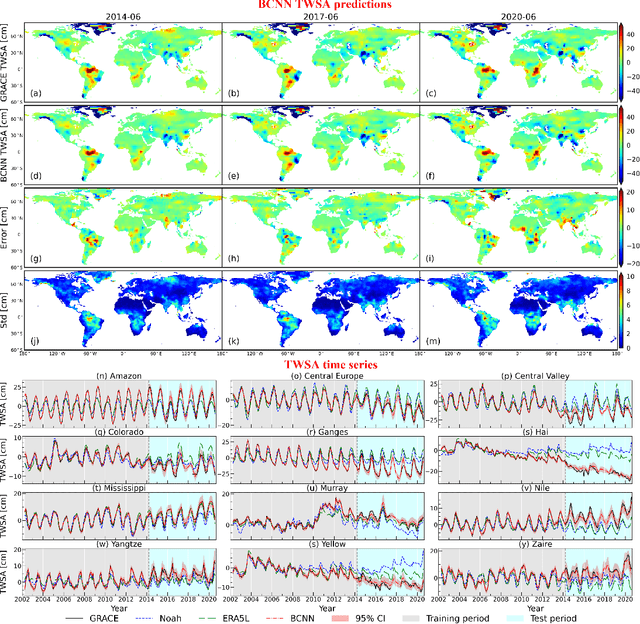
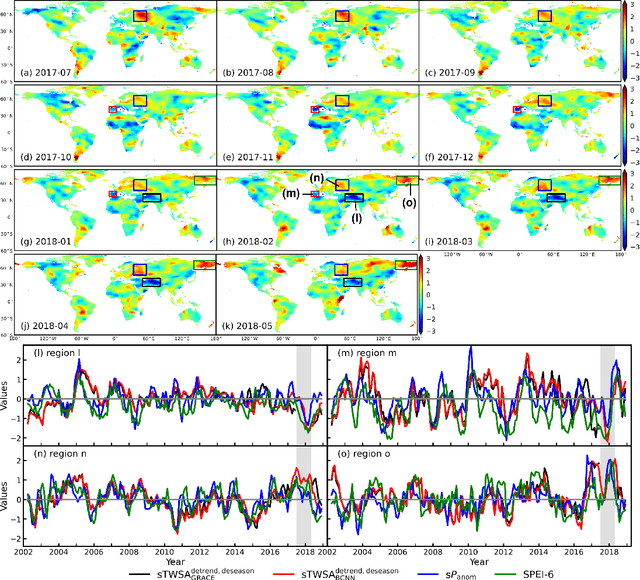
There is an approximately one-year observation gap of terrestrial water storage anomalies (TWSAs) between the Gravity Recovery and Climate Experiment (GRACE) satellite and its successor GRACE Follow-On (GRACE-FO). This poses a challenge for water resources management, as discontinuity in the TWSA observations may introduce significant biases and uncertainties in hydrological model predictions and consequently mislead decision making. To tackle this challenge, a Bayesian convolutional neural network (BCNN) is proposed in this study to bridge this gap using climatic data as inputs. Enhanced by integrating recent advances in deep learning, BCNN can efficiently extract important features for TWSA predictions from multi-source input data. The predicted TWSAs are compared to the hydrological model outputs and three recent TWSA prediction products. Results suggest the superior performance of BCNN in bridging the gap. The extreme dry and wet events during the gap period are also successfully identified by BCNN.