 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
MultiAnimate: Pose-Guided Image Animation Made Extensible
Feb 25, 2026Pose-guided human image animation aims to synthesize realistic videos of a reference character driven by a sequence of poses. While diffusion-based methods have achieved remarkable success, most existing approaches are limited to single-character animation. We observe that naively extending these methods to multi-character scenarios often leads to identity confusion and implausible occlusions between characters. To address these challenges, in this paper, we propose an extensible multi-character image animation framework built upon modern Diffusion Transformers (DiTs) for video generation. At its core, our framework introduces two novel components-Identifier Assigner and Identifier Adapter - which collaboratively capture per-person positional cues and inter-person spatial relationships. This mask-driven scheme, along with a scalable training strategy, not only enhances flexibility but also enables generalization to scenarios with more characters than those seen during training. Remarkably, trained on only a two-character dataset, our model generalizes to multi-character animation while maintaining compatibility with single-character cases. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in multi-character image animation, surpassing existing diffusion-based baselines.
Fast-SAM3D: 3Dfy Anything in Images but Faster
Feb 05, 2026SAM3D enables scalable, open-world 3D reconstruction from complex scenes, yet its deployment is hindered by prohibitive inference latency. In this work, we conduct the \textbf{first systematic investigation} into its inference dynamics, revealing that generic acceleration strategies are brittle in this context. We demonstrate that these failures stem from neglecting the pipeline's inherent multi-level \textbf{heterogeneity}: the kinematic distinctiveness between shape and layout, the intrinsic sparsity of texture refinement, and the spectral variance across geometries. To address this, we present \textbf{Fast-SAM3D}, a training-free framework that dynamically aligns computation with instantaneous generation complexity. Our approach integrates three heterogeneity-aware mechanisms: (1) \textit{Modality-Aware Step Caching} to decouple structural evolution from sensitive layout updates; (2) \textit{Joint Spatiotemporal Token Carving} to concentrate refinement on high-entropy regions; and (3) \textit{Spectral-Aware Token Aggregation} to adapt decoding resolution. Extensive experiments demonstrate that Fast-SAM3D delivers up to \textbf{2.67$\times$} end-to-end speedup with negligible fidelity loss, establishing a new Pareto frontier for efficient single-view 3D generation. Our code is released in https://github.com/wlfeng0509/Fast-SAM3D.
Teacher-Guided Student Self-Knowledge Distillation Using Diffusion Model
Feb 02, 2026Existing Knowledge Distillation (KD) methods often align feature information between teacher and student by exploring meaningful feature processing and loss functions. However, due to the difference in feature distributions between the teacher and student, the student model may learn incompatible information from the teacher. To address this problem, we propose teacher-guided student Diffusion Self-KD, dubbed as DSKD. Instead of the direct teacher-student alignment, we leverage the teacher classifier to guide the sampling process of denoising student features through a light-weight diffusion model. We then propose a novel locality-sensitive hashing (LSH)-guided feature distillation method between the original and denoised student features. The denoised student features encapsulate teacher knowledge and could be regarded as a teacher role. In this way, our DSKD method could eliminate discrepancies in mapping manners and feature distributions between the teacher and student, while learning meaningful knowledge from the teacher. Experiments on visual recognition tasks demonstrate that DSKD significantly outperforms existing KD methods across various models and datasets. Our code is attached in supplementary material.
Distilling Time Series Foundation Models for Efficient Forecasting
Jan 19, 2026Time Series foundation models (TSFMs) deliver strong forecasting performance through large-scale pretraining, but their large parameter sizes make deployment costly. While knowledge distillation offers a natural and effective approach for model compression, techniques developed for general machine learning tasks are not directly applicable to time series forecasting due to the unique characteristics. To address this, we present DistilTS, the first distillation framework specifically designed for TSFMs. DistilTS addresses two key challenges: (1) task difficulty discrepancy, specific to forecasting, where uniform weighting makes optimization dominated by easier short-term horizons, while long-term horizons receive weaker supervision; and (2) architecture discrepancy, a general challenge in distillation, for which we design an alignment mechanism in the time series forecasting. To overcome these issues, DistilTS introduces horizon-weighted objectives to balance learning across horizons, and a temporal alignment strategy that reduces architectural mismatch, enabling compact models. Experiments on multiple benchmarks demonstrate that DistilTS achieves forecasting performance comparable to full-sized TSFMs, while reducing parameters by up to 1/150 and accelerating inference by up to 6000x. Code is available at: https://github.com/itsnotacie/DistilTS-ICASSP2026.
Asymmetric Cross-Modal Knowledge Distillation: Bridging Modalities with Weak Semantic Consistency
Nov 12, 2025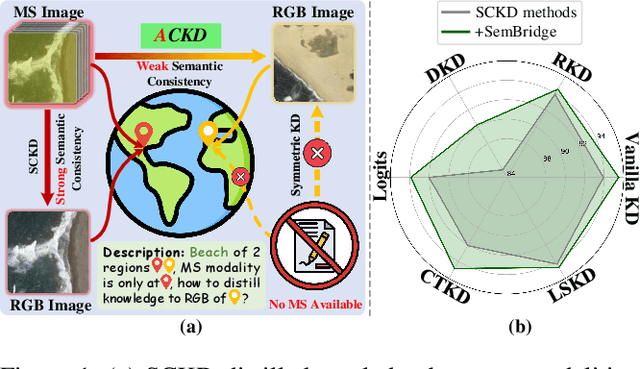



Cross-modal Knowledge Distillation has demonstrated promising performance on paired modalities with strong semantic connections, referred to as Symmetric Cross-modal Knowledge Distillation (SCKD). However, implementing SCKD becomes exceedingly constrained in real-world scenarios due to the limited availability of paired modalities. To this end, we investigate a general and effective knowledge learning concept under weak semantic consistency, dubbed Asymmetric Cross-modal Knowledge Distillation (ACKD), aiming to bridge modalities with limited semantic overlap. Nevertheless, the shift from strong to weak semantic consistency improves flexibility but exacerbates challenges in knowledge transmission costs, which we rigorously verified based on optimal transport theory. To mitigate the issue, we further propose a framework, namely SemBridge, integrating a Student-Friendly Matching module and a Semantic-aware Knowledge Alignment module. The former leverages self-supervised learning to acquire semantic-based knowledge and provide personalized instruction for each student sample by dynamically selecting the relevant teacher samples. The latter seeks the optimal transport path by employing Lagrangian optimization. To facilitate the research, we curate a benchmark dataset derived from two modalities, namely Multi-Spectral (MS) and asymmetric RGB images, tailored for remote sensing scene classification. Comprehensive experiments exhibit that our framework achieves state-of-the-art performance compared with 7 existing approaches on 6 different model architectures across various datasets.
Overcoming Prompts Pool Confusion via Parameterized Prompt for Incremental Object Detection
Oct 31, 2025Recent studies have demonstrated that incorporating trainable prompts into pretrained models enables effective incremental learning. However, the application of prompts in incremental object detection (IOD) remains underexplored. Existing prompts pool based approaches assume disjoint class sets across incremental tasks, which are unsuitable for IOD as they overlook the inherent co-occurrence phenomenon in detection images. In co-occurring scenarios, unlabeled objects from previous tasks may appear in current task images, leading to confusion in prompts pool. In this paper, we hold that prompt structures should exhibit adaptive consolidation properties across tasks, with constrained updates to prevent catastrophic forgetting. Motivated by this, we introduce Parameterized Prompts for Incremental Object Detection (P$^2$IOD). Leveraging neural networks global evolution properties, P$^2$IOD employs networks as the parameterized prompts to adaptively consolidate knowledge across tasks. To constrain prompts structure updates, P$^2$IOD further engages a parameterized prompts fusion strategy. Extensive experiments on PASCAL VOC2007 and MS COCO datasets demonstrate that P$^2$IOD's effectiveness in IOD and achieves the state-of-the-art performance among existing baselines.
$\text{S}^2$Q-VDiT: Accurate Quantized Video Diffusion Transformer with Salient Data and Sparse Token Distillation
Aug 06, 2025Diffusion transformers have emerged as the mainstream paradigm for video generation models. However, the use of up to billions of parameters incurs significant computational costs. Quantization offers a promising solution by reducing memory usage and accelerating inference. Nonetheless, we observe that the joint modeling of spatial and temporal information in video diffusion models (V-DMs) leads to extremely long token sequences, which introduces high calibration variance and learning challenges. To address these issues, we propose \textbf{$\text{S}^2$Q-VDiT}, a post-training quantization framework for V-DMs that leverages \textbf{S}alient data and \textbf{S}parse token distillation. During the calibration phase, we identify that quantization performance is highly sensitive to the choice of calibration data. To mitigate this, we introduce \textit{Hessian-aware Salient Data Selection}, which constructs high-quality calibration datasets by considering both diffusion and quantization characteristics unique to V-DMs. To tackle the learning challenges, we further analyze the sparse attention patterns inherent in V-DMs. Based on this observation, we propose \textit{Attention-guided Sparse Token Distillation}, which exploits token-wise attention distributions to emphasize tokens that are more influential to the model's output. Under W4A6 quantization, $\text{S}^2$Q-VDiT achieves lossless performance while delivering $3.9\times$ model compression and $1.3\times$ inference acceleration. Code will be available at \href{https://github.com/wlfeng0509/s2q-vdit}{https://github.com/wlfeng0509/s2q-vdit}.
Merlin: Multi-View Representation Learning for Robust Multivariate Time Series Forecasting with Unfixed Missing Rates
Jun 14, 2025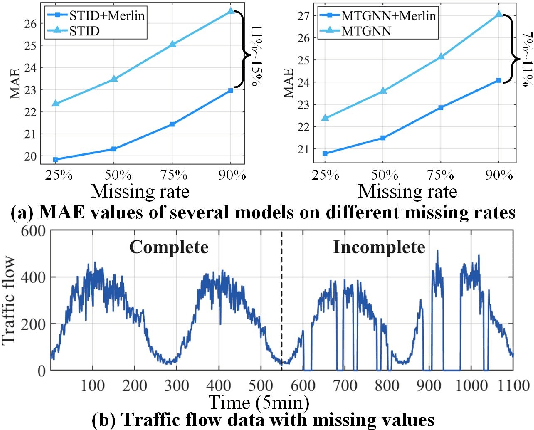
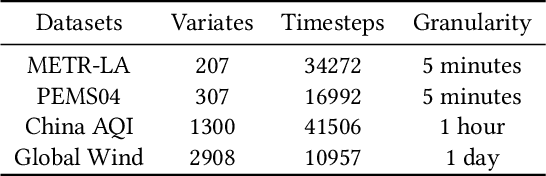
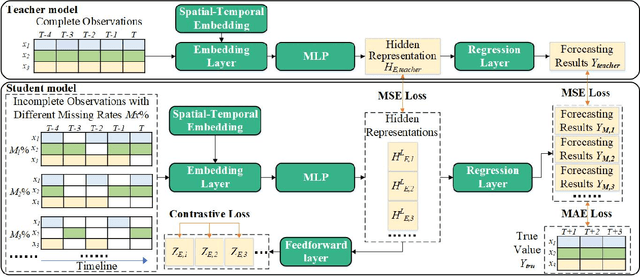
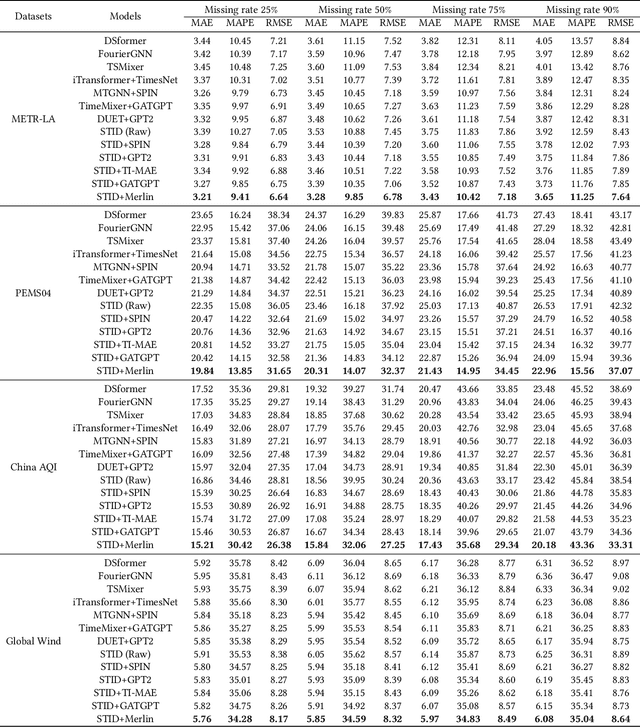
Multivariate Time Series Forecasting (MTSF) involves predicting future values of multiple interrelated time series. Recently, deep learning-based MTSF models have gained significant attention for their promising ability to mine semantics (global and local information) within MTS data. However, these models are pervasively susceptible to missing values caused by malfunctioning data collectors. These missing values not only disrupt the semantics of MTS, but their distribution also changes over time. Nevertheless, existing models lack robustness to such issues, leading to suboptimal forecasting performance. To this end, in this paper, we propose Multi-View Representation Learning (Merlin), which can help existing models achieve semantic alignment between incomplete observations with different missing rates and complete observations in MTS. Specifically, Merlin consists of two key modules: offline knowledge distillation and multi-view contrastive learning. The former utilizes a teacher model to guide a student model in mining semantics from incomplete observations, similar to those obtainable from complete observations. The latter improves the student model's robustness by learning from positive/negative data pairs constructed from incomplete observations with different missing rates, ensuring semantic alignment across different missing rates. Therefore, Merlin is capable of effectively enhancing the robustness of existing models against unfixed missing rates while preserving forecasting accuracy. Experiments on four real-world datasets demonstrate the superiority of Merlin.
Q-VDiT: Towards Accurate Quantization and Distillation of Video-Generation Diffusion Transformers
May 28, 2025Diffusion transformers (DiT) have demonstrated exceptional performance in video generation. However, their large number of parameters and high computational complexity limit their deployment on edge devices. Quantization can reduce storage requirements and accelerate inference by lowering the bit-width of model parameters. Yet, existing quantization methods for image generation models do not generalize well to video generation tasks. We identify two primary challenges: the loss of information during quantization and the misalignment between optimization objectives and the unique requirements of video generation. To address these challenges, we present Q-VDiT, a quantization framework specifically designed for video DiT models. From the quantization perspective, we propose the Token-aware Quantization Estimator (TQE), which compensates for quantization errors in both the token and feature dimensions. From the optimization perspective, we introduce Temporal Maintenance Distillation (TMD), which preserves the spatiotemporal correlations between frames and enables the optimization of each frame with respect to the overall video context. Our W3A6 Q-VDiT achieves a scene consistency of 23.40, setting a new benchmark and outperforming current state-of-the-art quantization methods by 1.9$\times$. Code will be available at https://github.com/cantbebetter2/Q-VDiT.