 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedKD-hybrid: Federated Hybrid Knowledge Distillation for Lithography Hotspot Detection
Jan 07, 2025



Federated Learning (FL) provides novel solutions for machine learning (ML)-based lithography hotspot detection (LHD) under distributed privacy-preserving settings. Currently, two research pipelines have been investigated to aggregate local models and achieve global consensus, including parameter/nonparameter based (also known as knowledge distillation, namely KD). While these two kinds of methods show effectiveness in specific scenarios, we note they have not fully utilized and transferred the information learned, leaving the potential of FL-based LDH remains unexplored. Thus, we propose FedKDhybrid in this study to mitigate the research gap. Specifically, FedKD-hybrid clients agree on several identical layers across all participants and a public dataset for achieving global consensus. During training, the trained local model will be evaluated on the public dataset, and the generated logits will be uploaded along with the identical layer parameters. The aggregated information is consequently used to update local models via the public dataset as a medium. We compare our proposed FedKD-hybrid with several state-of-the-art (SOTA) FL methods under ICCAD-2012 and FAB (real-world collected) datasets with different settings; the experimental results demonstrate the superior performance of the FedKD-hybrid algorithm. Our code is available at https://github.com/itsnotacie/NN-FedKD-hybrid
SGLP: A Similarity Guided Fast Layer Partition Pruning for Compressing Large Deep Models
Oct 14, 2024



The deployment of Deep Neural Network (DNN)-based networks on resource-constrained devices remains a significant challenge due to their high computational and parameter requirements. To solve this problem, layer pruning has emerged as a potent approach to reduce network size and improve computational efficiency. However, existing layer pruning methods mostly overlook the intrinsic connections and inter-dependencies between different layers within complicated deep neural networks. This oversight can result in pruned models that do not preserve the essential characteristics of the pre-trained network as effectively as desired. To address this limitations, we propose a Similarity Guided fast Layer Partition pruning for compressing large deep models (SGLP), which focuses on pruning layers from network segments partitioned via representation similarity. Specifically, our presented method first leverages Centered Kernel Alignment (CKA) to indicate the internal representations among the layers of the pre-trained network, which provides us with a potent basis for layer pruning. Based on similarity matrix derived from CKA, we employ Fisher Optimal Segmentation to partition the network into multiple segments, which provides a basis for removing the layers in a segment-wise manner. In addition, our method innovatively adopts GradNorm for segment-wise layer importance evaluation, eliminating the need for extensive fine-tuning, and finally prunes the unimportant layers to obtain a compact network. Experimental results in image classification and for large language models (LLMs) demonstrate that our proposed SGLP outperforms the state-of-the-art methods in both accuracy and computational efficiency, presenting a more effective solution for deploying DNNs on resource-limited platforms. Our codes are available at https://github.com/itsnotacie/information-fusion-SGLP.
Federated Distillation: A Survey
Apr 02, 2024



Federated Learning (FL) seeks to train a model collaboratively without sharing private training data from individual clients. Despite its promise, FL encounters challenges such as high communication costs for large-scale models and the necessity for uniform model architectures across all clients and the server. These challenges severely restrict the practical applications of FL. To address these limitations, the integration of knowledge distillation (KD) into FL has been proposed, forming what is known as Federated Distillation (FD). FD enables more flexible knowledge transfer between clients and the server, surpassing the mere sharing of model parameters. By eliminating the need for identical model architectures across clients and the server, FD mitigates the communication costs associated with training large-scale models. This paper aims to offer a comprehensive overview of FD, highlighting its latest advancements. It delves into the fundamental principles underlying the design of FD frameworks, delineates FD approaches for tackling various challenges, and provides insights into the diverse applications of FD across different scenarios.
Deep Dictionary Learning with An Intra-class Constraint
Jul 14, 2022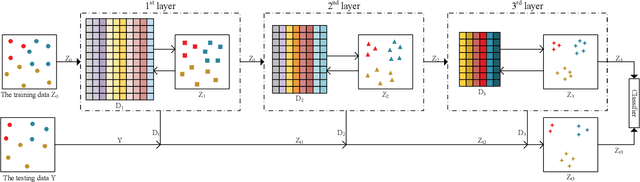
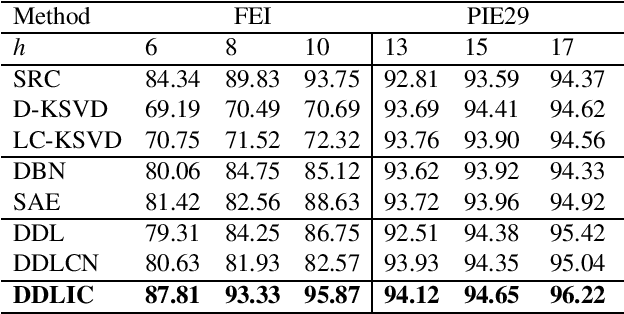
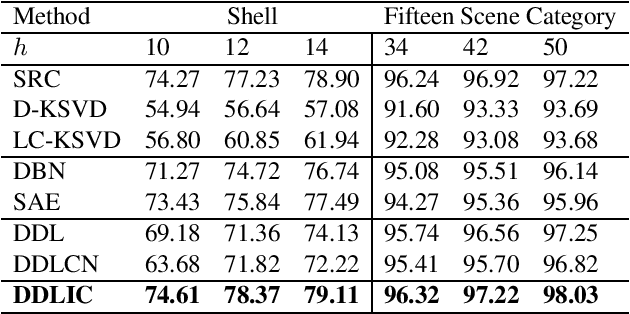
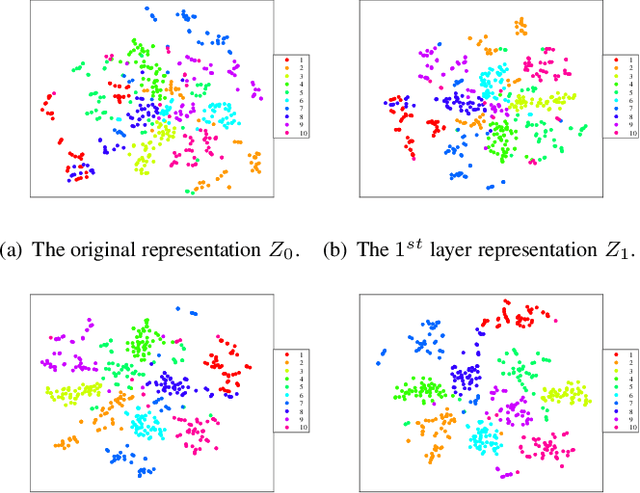
In recent years, deep dictionary learning (DDL)has attracted a great amount of attention due to its effectiveness for representation learning and visual recognition.~However, most existing methods focus on unsupervised deep dictionary learning, failing to further explore the category information.~To make full use of the category information of different samples, we propose a novel deep dictionary learning model with an intra-class constraint (DDLIC) for visual classification. Specifically, we design the intra-class compactness constraint on the intermediate representation at different levels to encourage the intra-class representations to be closer to each other, and eventually the learned representation becomes more discriminative.~Unlike the traditional DDL methods, during the classification stage, our DDLIC performs a layer-wise greedy optimization in a similar way to the training stage. Experimental results on four image datasets show that our method is superior to the state-of-the-art methods.
Collaborative Teacher-Student Learning via Multiple Knowledge Transfer
Jan 27, 2021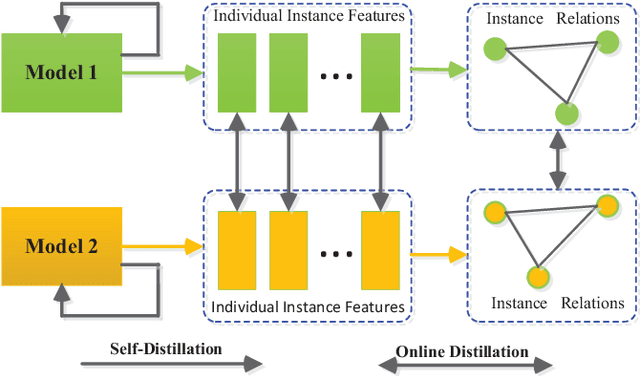

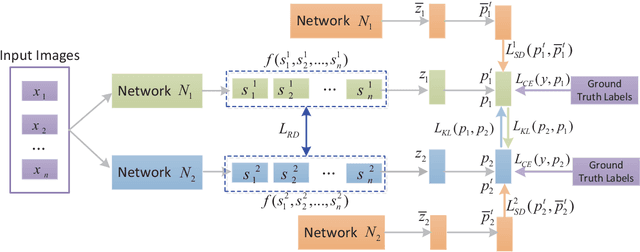
Knowledge distillation (KD), as an efficient and effective model compression technique, has been receiving considerable attention in deep learning. The key to its success is to transfer knowledge from a large teacher network to a small student one. However, most of the existing knowledge distillation methods consider only one type of knowledge learned from either instance features or instance relations via a specific distillation strategy in teacher-student learning. There are few works that explore the idea of transferring different types of knowledge with different distillation strategies in a unified framework. Moreover, the frequently used offline distillation suffers from a limited learning capacity due to the fixed teacher-student architecture. In this paper we propose a collaborative teacher-student learning via multiple knowledge transfer (CTSL-MKT) that prompts both self-learning and collaborative learning. It allows multiple students learn knowledge from both individual instances and instance relations in a collaborative way. While learning from themselves with self-distillation, they can also guide each other via online distillation. The experiments and ablation studies on four image datasets demonstrate that the proposed CTSL-MKT significantly outperforms the state-of-the-art KD methods.
Knowledge Distillation: A Survey
Jun 30, 2020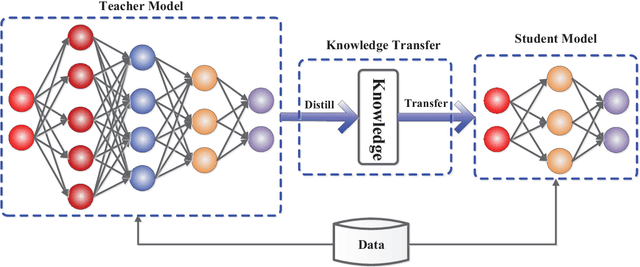
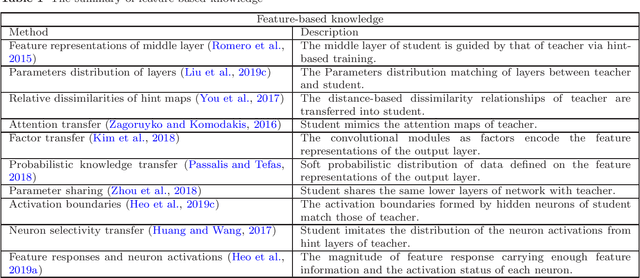
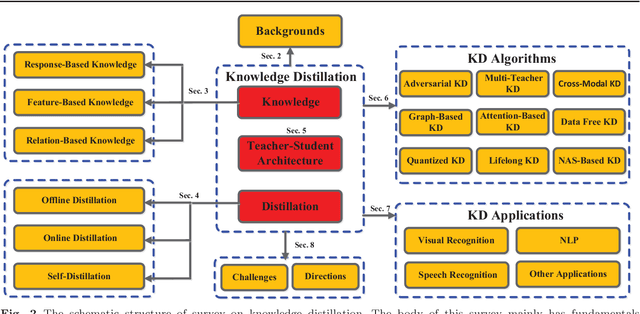
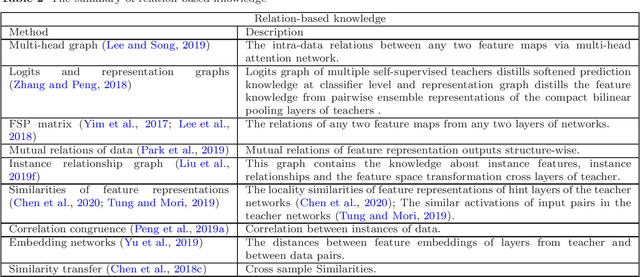
In recent years, deep neural networks have been successful in both industry and academia, especially for computer vision tasks. The great success of deep learning is mainly due to its scalability to encode large-scale data and to maneuver billions of model parameters. However, it is a challenge to deploy these cumbersome deep models on devices with limited resources, e.g., mobile phones and embedded devices, not only because of the high computational complexity but also the large storage requirements. To this end, a variety of model compression and acceleration techniques have been developed. As a representative type of model compression and acceleration, knowledge distillation effectively learns a small student model from a large teacher model. It has received rapid increasing attention from the community. This paper provides a comprehensive survey of knowledge distillation from the perspectives of knowledge categories, training schemes, distillation algorithms and applications. Furthermore, challenges in knowledge distillation are briefly reviewed and comments on future research are discussed and forwarded.
Deep Collaborative Weight-based Classification
Feb 21, 2018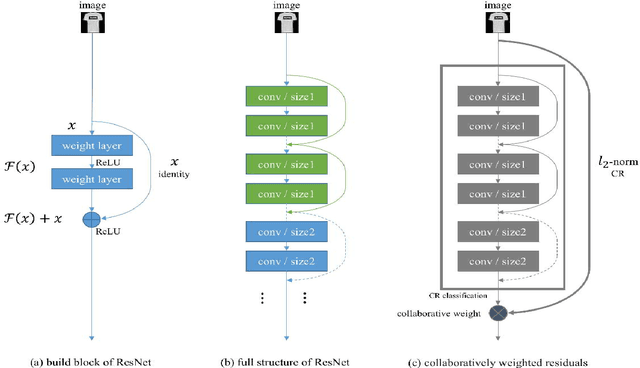
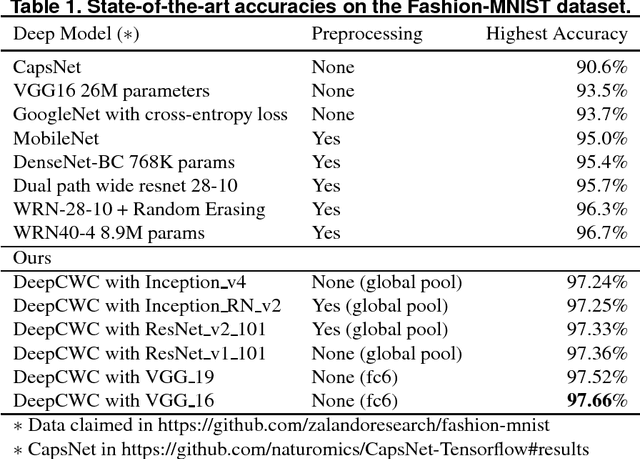
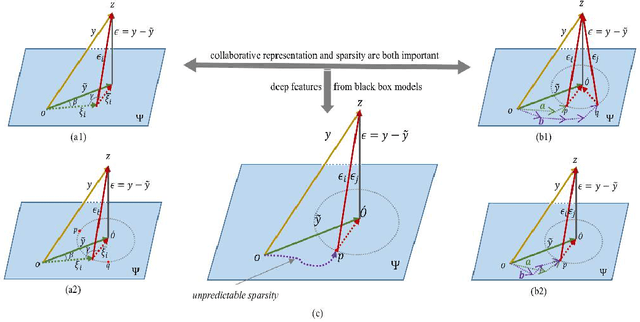
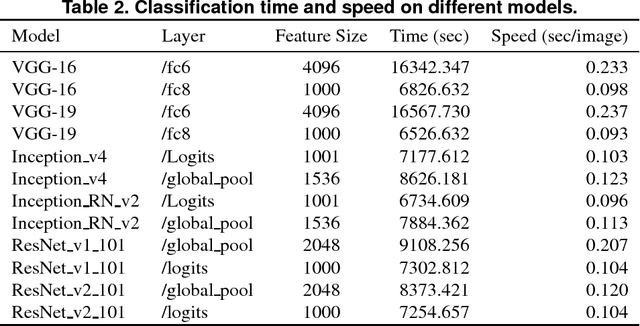
One of the biggest problems in deep learning is its difficulty to retain consistent robustness when transferring the model trained on one dataset to another dataset. To conquer the problem, deep transfer learning was implemented to execute various vision tasks by using a pre-trained deep model in a diverse dataset. However, the robustness was often far from state-of-the-art. We propose a collaborative weight-based classification method for deep transfer learning (DeepCWC). The method performs the L2-norm based collaborative representation on the original images, as well as the deep features extracted by pre-trained deep models. Two distance vectors will be obtained based on the two representation coefficients, and then fused together via the collaborative weight. The two feature sets show a complementary character, and the original images provide information compensating the missed part in the transferred deep model. A series of experiments conducted on both small and large vision datasets demonstrated the robustness of the proposed DeepCWC in both face recognition and object recognition tasks.