 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseCompass: Intelligent Synthetic Pose Selection for Visual Localization
May 12, 2026In visual localization, Absolute Pose Regression (APR) enables real-time 6-DoF camera pose inference from single images, yet critically depends on fine-tuning data quality and coverage. While recent methods leverage 3D Gaussian Splatting (3DGS) for novel view synthesis-based data augmentation, random sampling generates redundant views and noisy samples from poorly reconstructed regions. To mitigate this research gap, we propose PoseCompass, an intelligent pose selection pipeline for 3DGS-based APR. PoseCompass formulates synthetic pose selection and derives a value-based pose ranking mechanism to identify informative poses. The ranking integrates three dimensions: Localization Difficulty, favoring challenging regions; Coverage Novelty, exploring under-sampled areas; and Rendering Observability, filtering artifacts and noise. PoseCompass then generates trajectory-constrained candidates, selects the top-K ranked poses, and synthesizes views using 3DGS with lightweight diffusion-based alignment. Finally, the pose regressor is fine-tuned on mixed real and synthetic data. We evaluate PoseCompass on 7-Scenes, where it reduces adaptation time from 15.2 to 5.1 minutes, a 3x speedup, while cutting median pose errors by 53.8 percent and significantly outperforming random baselines.
Optimal Look-back Horizon for Time Series Forecasting in Federated Learning
Nov 18, 2025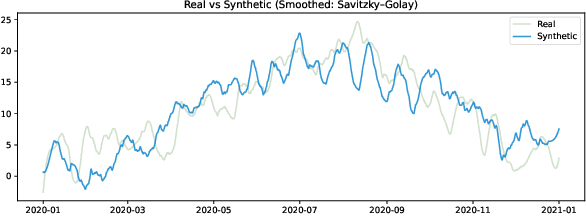
Selecting an appropriate look-back horizon remains a fundamental challenge in time series forecasting (TSF), particularly in the federated learning scenarios where data is decentralized, heterogeneous, and often non-independent. While recent work has explored horizon selection by preserving forecasting-relevant information in an intrinsic space, these approaches are primarily restricted to centralized and independently distributed settings. This paper presents a principled framework for adaptive horizon selection in federated time series forecasting through an intrinsic space formulation. We introduce a synthetic data generator (SDG) that captures essential temporal structures in client data, including autoregressive dependencies, seasonality, and trend, while incorporating client-specific heterogeneity. Building on this model, we define a transformation that maps time series windows into an intrinsic representation space with well-defined geometric and statistical properties. We then derive a decomposition of the forecasting loss into a Bayesian term, which reflects irreducible uncertainty, and an approximation term, which accounts for finite-sample effects and limited model capacity. Our analysis shows that while increasing the look-back horizon improves the identifiability of deterministic patterns, it also increases approximation error due to higher model complexity and reduced sample efficiency. We prove that the total forecasting loss is minimized at the smallest horizon where the irreducible loss starts to saturate, while the approximation loss continues to rise. This work provides a rigorous theoretical foundation for adaptive horizon selection for time series forecasting in federated learning.
GuardFed: A Trustworthy Federated Learning Framework Against Dual-Facet Attacks
Nov 12, 2025Federated learning (FL) enables privacy-preserving collaborative model training but remains vulnerable to adversarial behaviors that compromise model utility or fairness across sensitive groups. While extensive studies have examined attacks targeting either objective, strategies that simultaneously degrade both utility and fairness remain largely unexplored. To bridge this gap, we introduce the Dual-Facet Attack (DFA), a novel threat model that concurrently undermines predictive accuracy and group fairness. Two variants, Synchronous DFA (S-DFA) and Split DFA (Sp-DFA), are further proposed to capture distinct real-world collusion scenarios. Experimental results show that existing robust FL defenses, including hybrid aggregation schemes, fail to resist DFAs effectively. To counter these threats, we propose GuardFed, a self-adaptive defense framework that maintains a fairness-aware reference model using a small amount of clean server data augmented with synthetic samples. In each training round, GuardFed computes a dual-perspective trust score for every client by jointly evaluating its utility deviation and fairness degradation, thereby enabling selective aggregation of trustworthy updates. Extensive experiments on real-world datasets demonstrate that GuardFed consistently preserves both accuracy and fairness under diverse non-IID and adversarial conditions, achieving state-of-the-art performance compared with existing robust FL methods.
FedKD-hybrid: Federated Hybrid Knowledge Distillation for Lithography Hotspot Detection
Jan 07, 2025



Federated Learning (FL) provides novel solutions for machine learning (ML)-based lithography hotspot detection (LHD) under distributed privacy-preserving settings. Currently, two research pipelines have been investigated to aggregate local models and achieve global consensus, including parameter/nonparameter based (also known as knowledge distillation, namely KD). While these two kinds of methods show effectiveness in specific scenarios, we note they have not fully utilized and transferred the information learned, leaving the potential of FL-based LDH remains unexplored. Thus, we propose FedKDhybrid in this study to mitigate the research gap. Specifically, FedKD-hybrid clients agree on several identical layers across all participants and a public dataset for achieving global consensus. During training, the trained local model will be evaluated on the public dataset, and the generated logits will be uploaded along with the identical layer parameters. The aggregated information is consequently used to update local models via the public dataset as a medium. We compare our proposed FedKD-hybrid with several state-of-the-art (SOTA) FL methods under ICCAD-2012 and FAB (real-world collected) datasets with different settings; the experimental results demonstrate the superior performance of the FedKD-hybrid algorithm. Our code is available at https://github.com/itsnotacie/NN-FedKD-hybrid
Threats and Defenses in Federated Learning Life Cycle: A Comprehensive Survey and Challenges
Jul 11, 2024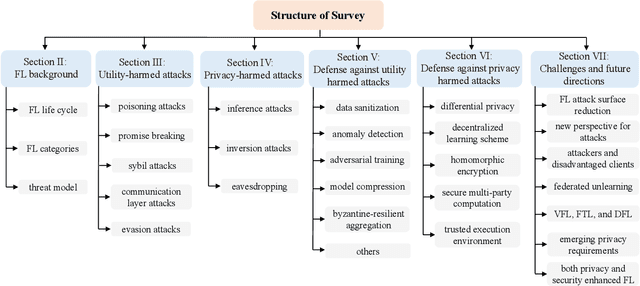
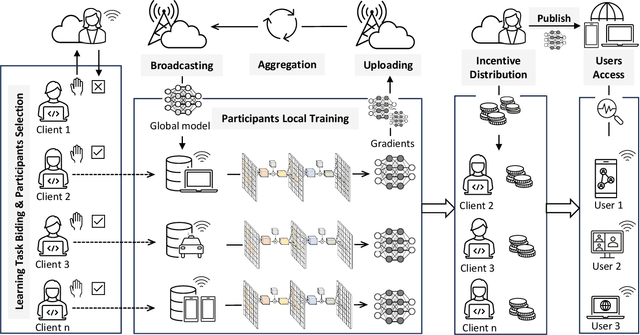
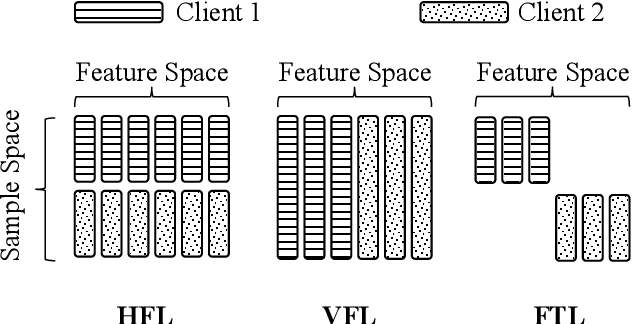
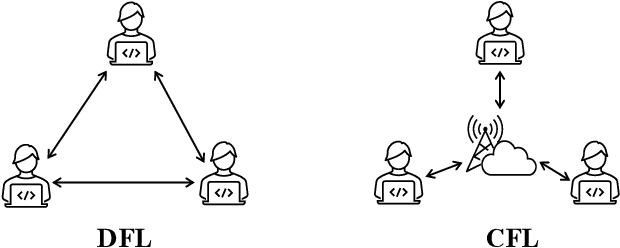
Federated Learning (FL) offers innovative solutions for privacy-preserving collaborative machine learning (ML). Despite its promising potential, FL is vulnerable to various attacks due to its distributed nature, affecting the entire life cycle of FL services. These threats can harm the model's utility or compromise participants' privacy, either directly or indirectly. In response, numerous defense frameworks have been proposed, demonstrating effectiveness in specific settings and scenarios. To provide a clear understanding of the current research landscape, this paper reviews the most representative and state-of-the-art threats and defense frameworks throughout the FL service life cycle. We start by identifying FL threats that harm utility and privacy, including those with potential or direct impacts. Then, we dive into the defense frameworks, analyze the relationship between threats and defenses, and compare the trade-offs among different defense strategies. Finally, we summarize current research bottlenecks and offer insights into future research directions to conclude this survey. We hope this survey sheds light on trustworthy FL research and contributes to the FL community.
Integrated feature analysis for deep learning interpretation and class activation maps
Jul 01, 2024Understanding the decisions of deep learning (DL) models is essential for the acceptance of DL to risk-sensitive applications. Although methods, like class activation maps (CAMs), give a glimpse into the black box, they do miss some crucial information, thereby limiting its interpretability and merely providing the considered locations of objects. To provide more insight into the models and the influence of datasets, we propose an integrated feature analysis method, which consists of feature distribution analysis and feature decomposition, to look closer into the intermediate features extracted by DL models. This integrated feature analysis could provide information on overfitting, confounders, outliers in datasets, model redundancies and principal features extracted by the models, and provide distribution information to form a common intensity scale, which are missing in current CAM algorithms. The integrated feature analysis was applied to eight different datasets for general validation: photographs of handwritten digits, two datasets of natural images and five medical datasets, including skin photography, ultrasound, CT, X-rays and MRIs. The method was evaluated by calculating the consistency between the CAMs average class activation levels and the logits of the model. Based on the eight datasets, the correlation coefficients through our method were all very close to 100%, and based on the feature decomposition, 5%-25% of features could generate equally informative saliency maps and obtain the same model performances as using all features. This proves the reliability of the integrated feature analysis. As the proposed methods rely on very few assumptions, this is a step towards better model interpretation and a useful extension to existing CAM algorithms. Codes: https://github.com/YanliLi27/IFA
Holistic Evaluation Metrics: Use Case Sensitive Evaluation Metrics for Federated Learning
May 03, 2024A large number of federated learning (FL) algorithms have been proposed for different applications and from varying perspectives. However, the evaluation of such approaches often relies on a single metric (e.g., accuracy). Such a practice fails to account for the unique demands and diverse requirements of different use cases. Thus, how to comprehensively evaluate an FL algorithm and determine the most suitable candidate for a designated use case remains an open question. To mitigate this research gap, we introduce the Holistic Evaluation Metrics (HEM) for FL in this work. Specifically, we collectively focus on three primary use cases, which are Internet of Things (IoT), smart devices, and institutions. The evaluation metric encompasses various aspects including accuracy, convergence, computational efficiency, fairness, and personalization. We then assign a respective importance vector for each use case, reflecting their distinct performance requirements and priorities. The HEM index is finally generated by integrating these metric components with their respective importance vectors. Through evaluating different FL algorithms in these three prevalent use cases, our experimental results demonstrate that HEM can effectively assess and identify the FL algorithms best suited to particular scenarios. We anticipate this work sheds light on the evaluation process for pragmatic FL algorithms in real-world applications.