 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated feature analysis for deep learning interpretation and class activation maps
Jul 01, 2024Understanding the decisions of deep learning (DL) models is essential for the acceptance of DL to risk-sensitive applications. Although methods, like class activation maps (CAMs), give a glimpse into the black box, they do miss some crucial information, thereby limiting its interpretability and merely providing the considered locations of objects. To provide more insight into the models and the influence of datasets, we propose an integrated feature analysis method, which consists of feature distribution analysis and feature decomposition, to look closer into the intermediate features extracted by DL models. This integrated feature analysis could provide information on overfitting, confounders, outliers in datasets, model redundancies and principal features extracted by the models, and provide distribution information to form a common intensity scale, which are missing in current CAM algorithms. The integrated feature analysis was applied to eight different datasets for general validation: photographs of handwritten digits, two datasets of natural images and five medical datasets, including skin photography, ultrasound, CT, X-rays and MRIs. The method was evaluated by calculating the consistency between the CAMs average class activation levels and the logits of the model. Based on the eight datasets, the correlation coefficients through our method were all very close to 100%, and based on the feature decomposition, 5%-25% of features could generate equally informative saliency maps and obtain the same model performances as using all features. This proves the reliability of the integrated feature analysis. As the proposed methods rely on very few assumptions, this is a step towards better model interpretation and a useful extension to existing CAM algorithms. Codes: https://github.com/YanliLi27/IFA
Prediction of Lung CT Scores of Systemic Sclerosis by Cascaded Regression Neural Networks
Oct 15, 2021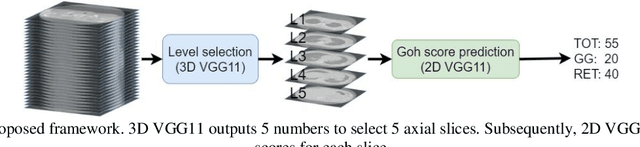

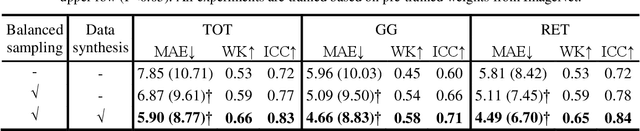
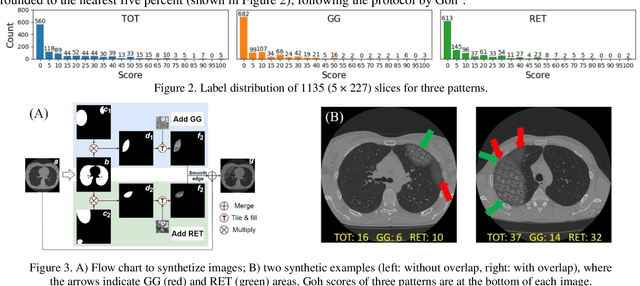
Visually scoring lung involvement in systemic sclerosis from CT scans plays an important role in monitoring progression, but its labor intensiveness hinders practical application. We proposed, therefore, an automatic scoring framework that consists of two cascaded deep regression neural networks. The first (3D) network aims to predict the craniocaudal position of five anatomically defined scoring levels on the 3D CT scans. The second (2D) network receives the resulting 2D axial slices and predicts the scores. We used 227 3D CT scans to train and validate the first network, and the resulting 1135 axial slices were used in the second network. Two experts scored independently a subset of data to obtain intra- and interobserver variabilities and the ground truth for all data was obtained in consensus. To alleviate the unbalance in training labels in the second network, we introduced a sampling technique and to increase the diversity of the training samples synthetic data was generated, mimicking ground glass and reticulation patterns. The 4-fold cross validation showed that our proposed network achieved an average MAE of 5.90, 4.66 and 4.49, weighted kappa of 0.66, 0.58 and 0.65 for total score (TOT), ground glass (GG) and reticular pattern (RET), respectively. Our network performed slightly worse than the best experts on TOT and GG prediction but it has competitive performance on RET prediction and has the potential to be an objective alternative for the visual scoring of SSc in CT thorax studies.
Multi-task Semi-supervised Learning for Pulmonary Lobe Segmentation
Apr 22, 2021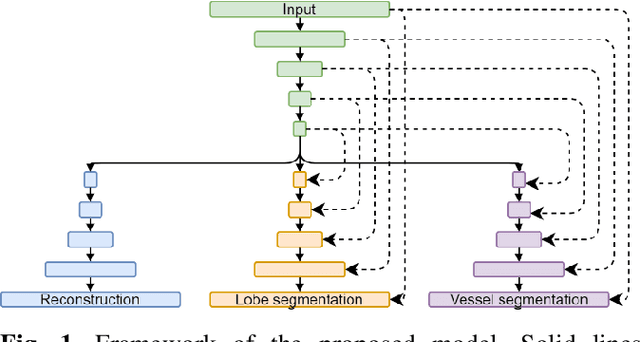
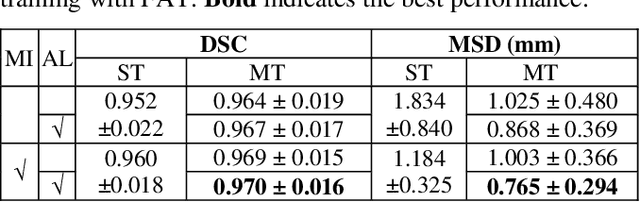
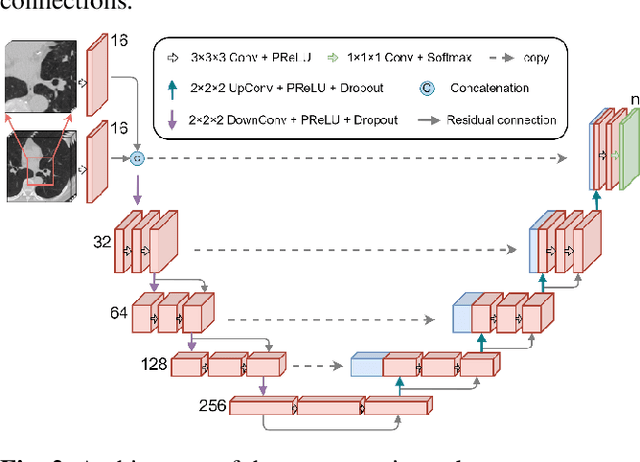
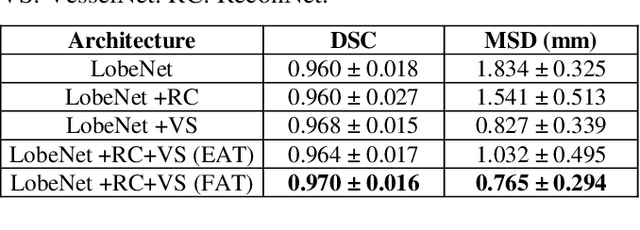
Pulmonary lobe segmentation is an important preprocessing task for the analysis of lung diseases. Traditional methods relying on fissure detection or other anatomical features, such as the distribution of pulmonary vessels and airways, could provide reasonably accurate lobe segmentations. Deep learning based methods can outperform these traditional approaches, but require large datasets. Deep multi-task learning is expected to utilize labels of multiple different structures. However, commonly such labels are distributed over multiple datasets. In this paper, we proposed a multi-task semi-supervised model that can leverage information of multiple structures from unannotated datasets and datasets annotated with different structures. A focused alternating training strategy is presented to balance the different tasks. We evaluated the trained model on an external independent CT dataset. The results show that our model significantly outperforms single-task alternatives, improving the mean surface distance from 7.174 mm to 4.196 mm. We also demonstrated that our approach is successful for different network architectures as backbones.