 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Aware and Dynamically Adaptive Federated Defense Framework for SAR Image Target Recognition
Dec 31, 2025As a critical application of computational intelligence in remote sensing, deep learning-based synthetic aperture radar (SAR) image target recognition facilitates intelligent perception but typically relies on centralized training, where multi-source SAR data are uploaded to a single server, raising privacy and security concerns. Federated learning (FL) provides an emerging computational intelligence paradigm for SAR image target recognition, enabling cross-site collaboration while preserving local data privacy. However, FL confronts critical security risks, where malicious clients can exploit SAR's multiplicative speckle noise to conceal backdoor triggers, severely challenging the robustness of the computational intelligence model. To address this challenge, we propose NADAFD, a noise-aware and dynamically adaptive federated defense framework that integrates frequency-domain, spatial-domain, and client-behavior analyses to counter SAR-specific backdoor threats. Specifically, we introduce a frequency-domain collaborative inversion mechanism to expose cross-client spectral inconsistencies indicative of hidden backdoor triggers. We further design a noise-aware adversarial training strategy that embeds $Γ$-distributed speckle characteristics into mask-guided adversarial sample generation to enhance robustness against both backdoor attacks and SAR speckle noise. In addition, we present a dynamic health assessment module that tracks client update behaviors across training rounds and adaptively adjusts aggregation weights to mitigate evolving malicious contributions. Experiments on MSTAR and OpenSARShip datasets demonstrate that NADAFD achieves higher accuracy on clean test samples and a lower backdoor attack success rate on triggered inputs than existing federated backdoor defenses for SAR target recognition.
GuardFed: A Trustworthy Federated Learning Framework Against Dual-Facet Attacks
Nov 12, 2025Federated learning (FL) enables privacy-preserving collaborative model training but remains vulnerable to adversarial behaviors that compromise model utility or fairness across sensitive groups. While extensive studies have examined attacks targeting either objective, strategies that simultaneously degrade both utility and fairness remain largely unexplored. To bridge this gap, we introduce the Dual-Facet Attack (DFA), a novel threat model that concurrently undermines predictive accuracy and group fairness. Two variants, Synchronous DFA (S-DFA) and Split DFA (Sp-DFA), are further proposed to capture distinct real-world collusion scenarios. Experimental results show that existing robust FL defenses, including hybrid aggregation schemes, fail to resist DFAs effectively. To counter these threats, we propose GuardFed, a self-adaptive defense framework that maintains a fairness-aware reference model using a small amount of clean server data augmented with synthetic samples. In each training round, GuardFed computes a dual-perspective trust score for every client by jointly evaluating its utility deviation and fairness degradation, thereby enabling selective aggregation of trustworthy updates. Extensive experiments on real-world datasets demonstrate that GuardFed consistently preserves both accuracy and fairness under diverse non-IID and adversarial conditions, achieving state-of-the-art performance compared with existing robust FL methods.
P2P: A Poison-to-Poison Remedy for Reliable Backdoor Defense in LLMs
Oct 06, 2025During fine-tuning, large language models (LLMs) are increasingly vulnerable to data-poisoning backdoor attacks, which compromise their reliability and trustworthiness. However, existing defense strategies suffer from limited generalization: they only work on specific attack types or task settings. In this study, we propose Poison-to-Poison (P2P), a general and effective backdoor defense algorithm. P2P injects benign triggers with safe alternative labels into a subset of training samples and fine-tunes the model on this re-poisoned dataset by leveraging prompt-based learning. This enforces the model to associate trigger-induced representations with safe outputs, thereby overriding the effects of original malicious triggers. Thanks to this robust and generalizable trigger-based fine-tuning, P2P is effective across task settings and attack types. Theoretically and empirically, we show that P2P can neutralize malicious backdoors while preserving task performance. We conduct extensive experiments on classification, mathematical reasoning, and summary generation tasks, involving multiple state-of-the-art LLMs. The results demonstrate that our P2P algorithm significantly reduces the attack success rate compared with baseline models. We hope that the P2P can serve as a guideline for defending against backdoor attacks and foster the development of a secure and trustworthy LLM community.
HRIPBench: Benchmarking LLMs in Harm Reduction Information Provision to Support People Who Use Drugs
Jul 29, 2025Millions of individuals' well-being are challenged by the harms of substance use. Harm reduction as a public health strategy is designed to improve their health outcomes and reduce safety risks. Some large language models (LLMs) have demonstrated a decent level of medical knowledge, promising to address the information needs of people who use drugs (PWUD). However, their performance in relevant tasks remains largely unexplored. We introduce HRIPBench, a benchmark designed to evaluate LLM's accuracy and safety risks in harm reduction information provision. The benchmark dataset HRIP-Basic has 2,160 question-answer-evidence pairs. The scope covers three tasks: checking safety boundaries, providing quantitative values, and inferring polysubstance use risks. We build the Instruction and RAG schemes to evaluate model behaviours based on their inherent knowledge and the integration of domain knowledge. Our results indicate that state-of-the-art LLMs still struggle to provide accurate harm reduction information, and sometimes, carry out severe safety risks to PWUD. The use of LLMs in harm reduction contexts should be cautiously constrained to avoid inducing negative health outcomes. WARNING: This paper contains illicit content that potentially induces harms.
Towards more transferable adversarial attack in black-box manner
May 23, 2025Adversarial attacks have become a well-explored domain, frequently serving as evaluation baselines for model robustness. Among these, black-box attacks based on transferability have received significant attention due to their practical applicability in real-world scenarios. Traditional black-box methods have generally focused on improving the optimization framework (e.g., utilizing momentum in MI-FGSM) to enhance transferability, rather than examining the dependency on surrogate white-box model architectures. Recent state-of-the-art approach DiffPGD has demonstrated enhanced transferability by employing diffusion-based adversarial purification models for adaptive attacks. The inductive bias of diffusion-based adversarial purification aligns naturally with the adversarial attack process, where both involving noise addition, reducing dependency on surrogate white-box model selection. However, the denoising process of diffusion models incurs substantial computational costs through chain rule derivation, manifested in excessive VRAM consumption and extended runtime. This progression prompts us to question whether introducing diffusion models is necessary. We hypothesize that a model sharing similar inductive bias to diffusion-based adversarial purification, combined with an appropriate loss function, could achieve comparable or superior transferability while dramatically reducing computational overhead. In this paper, we propose a novel loss function coupled with a unique surrogate model to validate our hypothesis. Our approach leverages the score of the time-dependent classifier from classifier-guided diffusion models, effectively incorporating natural data distribution knowledge into the adversarial optimization process. Experimental results demonstrate significantly improved transferability across diverse model architectures while maintaining robustness against diffusion-based defenses.
My Face Is Mine, Not Yours: Facial Protection Against Diffusion Model Face Swapping
May 21, 2025The proliferation of diffusion-based deepfake technologies poses significant risks for unauthorized and unethical facial image manipulation. While traditional countermeasures have primarily focused on passive detection methods, this paper introduces a novel proactive defense strategy through adversarial attacks that preemptively protect facial images from being exploited by diffusion-based deepfake systems. Existing adversarial protection methods predominantly target conventional generative architectures (GANs, AEs, VAEs) and fail to address the unique challenges presented by diffusion models, which have become the predominant framework for high-quality facial deepfakes. Current diffusion-specific adversarial approaches are limited by their reliance on specific model architectures and weights, rendering them ineffective against the diverse landscape of diffusion-based deepfake implementations. Additionally, they typically employ global perturbation strategies that inadequately address the region-specific nature of facial manipulation in deepfakes.
T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting
Feb 28, 2025



Zero-shot object counting aims to count instances of arbitrary object categories specified by text descriptions. Existing methods typically rely on vision-language models like CLIP, but often exhibit limited sensitivity to text prompts. We present T2ICount, a diffusion-based framework that leverages rich prior knowledge and fine-grained visual understanding from pretrained diffusion models. While one-step denoising ensures efficiency, it leads to weakened text sensitivity. To address this challenge, we propose a Hierarchical Semantic Correction Module that progressively refines text-image feature alignment, and a Representational Regional Coherence Loss that provides reliable supervision signals by leveraging the cross-attention maps extracted from the denosing U-Net. Furthermore, we observe that current benchmarks mainly focus on majority objects in images, potentially masking models' text sensitivity. To address this, we contribute a challenging re-annotated subset of FSC147 for better evaluation of text-guided counting ability. Extensive experiments demonstrate that our method achieves superior performance across different benchmarks. Code is available at https://github.com/cha15yq/T2ICount.
FedKD-hybrid: Federated Hybrid Knowledge Distillation for Lithography Hotspot Detection
Jan 07, 2025



Federated Learning (FL) provides novel solutions for machine learning (ML)-based lithography hotspot detection (LHD) under distributed privacy-preserving settings. Currently, two research pipelines have been investigated to aggregate local models and achieve global consensus, including parameter/nonparameter based (also known as knowledge distillation, namely KD). While these two kinds of methods show effectiveness in specific scenarios, we note they have not fully utilized and transferred the information learned, leaving the potential of FL-based LDH remains unexplored. Thus, we propose FedKDhybrid in this study to mitigate the research gap. Specifically, FedKD-hybrid clients agree on several identical layers across all participants and a public dataset for achieving global consensus. During training, the trained local model will be evaluated on the public dataset, and the generated logits will be uploaded along with the identical layer parameters. The aggregated information is consequently used to update local models via the public dataset as a medium. We compare our proposed FedKD-hybrid with several state-of-the-art (SOTA) FL methods under ICCAD-2012 and FAB (real-world collected) datasets with different settings; the experimental results demonstrate the superior performance of the FedKD-hybrid algorithm. Our code is available at https://github.com/itsnotacie/NN-FedKD-hybrid
MMAD-Purify: A Precision-Optimized Framework for Efficient and Scalable Multi-Modal Attacks
Oct 17, 2024

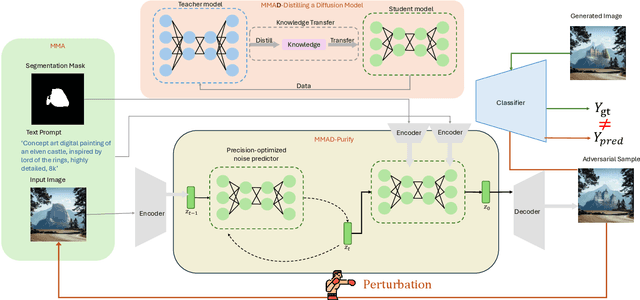
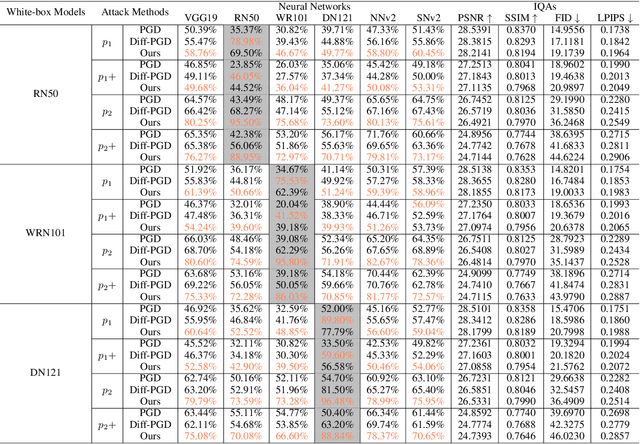
Neural networks have achieved remarkable performance across a wide range of tasks, yet they remain susceptible to adversarial perturbations, which pose significant risks in safety-critical applications. With the rise of multimodality, diffusion models have emerged as powerful tools not only for generative tasks but also for various applications such as image editing, inpainting, and super-resolution. However, these models still lack robustness due to limited research on attacking them to enhance their resilience. Traditional attack techniques, such as gradient-based adversarial attacks and diffusion model-based methods, are hindered by computational inefficiencies and scalability issues due to their iterative nature. To address these challenges, we introduce an innovative framework that leverages the distilled backbone of diffusion models and incorporates a precision-optimized noise predictor to enhance the effectiveness of our attack framework. This approach not only enhances the attack's potency but also significantly reduces computational costs. Our framework provides a cutting-edge solution for multi-modal adversarial attacks, ensuring reduced latency and the generation of high-fidelity adversarial examples with superior success rates. Furthermore, we demonstrate that our framework achieves outstanding transferability and robustness against purification defenses, outperforming existing gradient-based attack models in both effectiveness and efficiency.
Weak-To-Strong Backdoor Attacks for LLMs with Contrastive Knowledge Distillation
Sep 26, 2024Despite being widely applied due to their exceptional capabilities, Large Language Models (LLMs) have been proven to be vulnerable to backdoor attacks. These attacks introduce targeted vulnerabilities into LLMs by poisoning training samples and full-parameter fine-tuning. However, this kind of backdoor attack is limited since they require significant computational resources, especially as the size of LLMs increases. Besides, parameter-efficient fine-tuning (PEFT) offers an alternative but the restricted parameter updating may impede the alignment of triggers with target labels. In this study, we first verify that backdoor attacks with PEFT may encounter challenges in achieving feasible performance. To address these issues and improve the effectiveness of backdoor attacks with PEFT, we propose a novel backdoor attack algorithm from weak to strong based on contrastive knowledge distillation (W2SAttack). Specifically, we poison small-scale language models through full-parameter fine-tuning to serve as the teacher model. The teacher model then covertly transfers the backdoor to the large-scale student model through contrastive knowledge distillation, which employs PEFT. Theoretical analysis reveals that W2SAttack has the potential to augment the effectiveness of backdoor attacks. We demonstrate the superior performance of W2SAttack on classification tasks across four language models, four backdoor attack algorithms, and two different architectures of teacher models. Experimental results indicate success rates close to 100% for backdoor attacks targeting PEFT.