 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
FDP: A Frequency-Decomposition Preprocessing Pipeline for Unsupervised Anomaly Detection in Brain MRI
Nov 17, 2025Due to the diversity of brain anatomy and the scarcity of annotated data, supervised anomaly detection for brain MRI remains challenging, driving the development of unsupervised anomaly detection (UAD) approaches. Current UAD methods typically utilize artificially generated noise perturbations on healthy MRIs to train generative models for normal anatomy reconstruction, enabling anomaly detection via residual mapping. However, such simulated anomalies lack the biophysical fidelity and morphological complexity characteristic of true clinical lesions. To advance UAD in brain MRI, we conduct the first systematic frequency-domain analysis of pathological signatures, revealing two key properties: (1) anomalies exhibit unique frequency patterns distinguishable from normal anatomy, and (2) low-frequency signals maintain consistent representations across healthy scans. These insights motivate our Frequency-Decomposition Preprocessing (FDP) framework, the first UAD method to leverage frequency-domain reconstruction for simultaneous pathology suppression and anatomical preservation. FDP can integrate seamlessly with existing anomaly simulation techniques, consistently enhancing detection performance across diverse architectures while maintaining diagnostic fidelity. Experimental results demonstrate that FDP consistently improves anomaly detection performance when integrated with existing methods. Notably, FDP achieves a 17.63% increase in DICE score with LDM while maintaining robust improvements across multiple baselines. The code is available at https://github.com/ls1rius/MRI_FDP.
SceneDecorator: Towards Scene-Oriented Story Generation with Scene Planning and Scene Consistency
Oct 27, 2025Recent text-to-image models have revolutionized image generation, but they still struggle with maintaining concept consistency across generated images. While existing works focus on character consistency, they often overlook the crucial role of scenes in storytelling, which restricts their creativity in practice. This paper introduces scene-oriented story generation, addressing two key challenges: (i) scene planning, where current methods fail to ensure scene-level narrative coherence by relying solely on text descriptions, and (ii) scene consistency, which remains largely unexplored in terms of maintaining scene consistency across multiple stories. We propose SceneDecorator, a training-free framework that employs VLM-Guided Scene Planning to ensure narrative coherence across different scenes in a ``global-to-local'' manner, and Long-Term Scene-Sharing Attention to maintain long-term scene consistency and subject diversity across generated stories. Extensive experiments demonstrate the superior performance of SceneDecorator, highlighting its potential to unleash creativity in the fields of arts, films, and games.
HERO: Hierarchical Extrapolation and Refresh for Efficient World Models
Aug 25, 2025
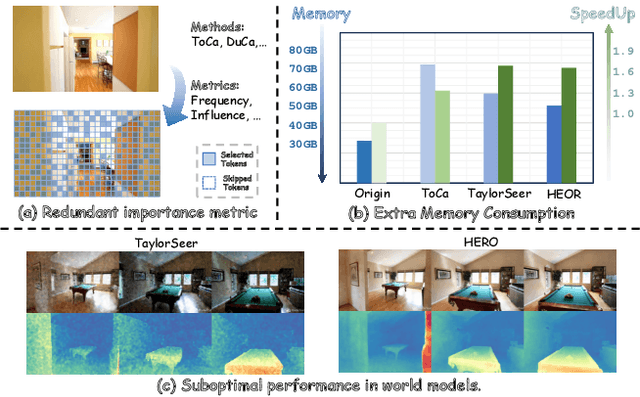
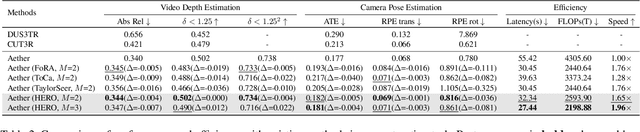

Generation-driven world models create immersive virtual environments but suffer slow inference due to the iterative nature of diffusion models. While recent advances have improved diffusion model efficiency, directly applying these techniques to world models introduces limitations such as quality degradation. In this paper, we present HERO, a training-free hierarchical acceleration framework tailored for efficient world models. Owing to the multi-modal nature of world models, we identify a feature coupling phenomenon, wherein shallow layers exhibit high temporal variability, while deeper layers yield more stable feature representations. Motivated by this, HERO adopts hierarchical strategies to accelerate inference: (i) In shallow layers, a patch-wise refresh mechanism efficiently selects tokens for recomputation. With patch-wise sampling and frequency-aware tracking, it avoids extra metric computation and remain compatible with FlashAttention. (ii) In deeper layers, a linear extrapolation scheme directly estimates intermediate features. This completely bypasses the computations in attention modules and feed-forward networks. Our experiments show that HERO achieves a 1.73$\times$ speedup with minimal quality degradation, significantly outperforming existing diffusion acceleration methods.
HybridGS: Decoupling Transients and Statics with 2D and 3D Gaussian Splatting
Dec 05, 2024



Generating high-quality novel view renderings of 3D Gaussian Splatting (3DGS) in scenes featuring transient objects is challenging. We propose a novel hybrid representation, termed as HybridGS, using 2D Gaussians for transient objects per image and maintaining traditional 3D Gaussians for the whole static scenes. Note that, the 3DGS itself is better suited for modeling static scenes that assume multi-view consistency, but the transient objects appear occasionally and do not adhere to the assumption, thus we model them as planar objects from a single view, represented with 2D Gaussians. Our novel representation decomposes the scene from the perspective of fundamental viewpoint consistency, making it more reasonable. Additionally, we present a novel multi-view regulated supervision method for 3DGS that leverages information from co-visible regions, further enhancing the distinctions between the transients and statics. Then, we propose a straightforward yet effective multi-stage training strategy to ensure robust training and high-quality view synthesis across various settings. Experiments on benchmark datasets show our state-of-the-art performance of novel view synthesis in both indoor and outdoor scenes, even in the presence of distracting elements.
A Grey-box Attack against Latent Diffusion Model-based Image Editing by Posterior Collapse
Aug 20, 2024
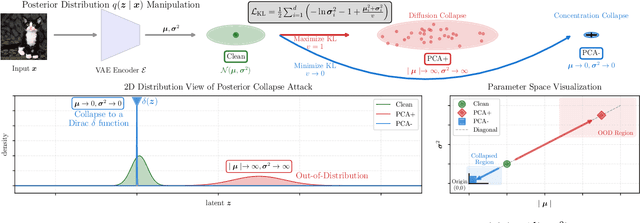


Recent advancements in generative AI, particularly Latent Diffusion Models (LDMs), have revolutionized image synthesis and manipulation. However, these generative techniques raises concerns about data misappropriation and intellectual property infringement. Adversarial attacks on machine learning models have been extensively studied, and a well-established body of research has extended these techniques as a benign metric to prevent the underlying misuse of generative AI. Current approaches to safeguarding images from manipulation by LDMs are limited by their reliance on model-specific knowledge and their inability to significantly degrade semantic quality of generated images. In response to these shortcomings, we propose the Posterior Collapse Attack (PCA) based on the observation that VAEs suffer from posterior collapse during training. Our method minimizes dependence on the white-box information of target models to get rid of the implicit reliance on model-specific knowledge. By accessing merely a small amount of LDM parameters, in specific merely the VAE encoder of LDMs, our method causes a substantial semantic collapse in generation quality, particularly in perceptual consistency, and demonstrates strong transferability across various model architectures. Experimental results show that PCA achieves superior perturbation effects on image generation of LDMs with lower runtime and VRAM. Our method outperforms existing techniques, offering a more robust and generalizable solution that is helpful in alleviating the socio-technical challenges posed by the rapidly evolving landscape of generative AI.
DiffX: Guide Your Layout to Cross-Modal Generative Modeling
Jul 28, 2024


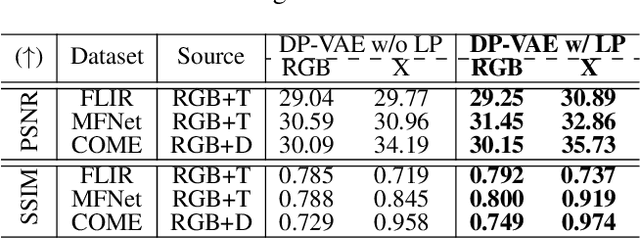
Diffusion models have made significant strides in language-driven and layout-driven image generation. However, most diffusion models are limited to visible RGB image generation. In fact, human perception of the world is enriched by diverse viewpoints, including chromatic contrast, thermal illumination, and depth information. In this paper, we introduce a novel diffusion model for general layout-guided cross-modal ``RGB+X'' generation, called DiffX. Firstly, we construct the cross-modal image datasets with text description by using LLaVA for image captioning, supplemented by manual corrections. Notably, DiffX presents a simple yet effective cross-modal generative modeling pipeline, which conducts diffusion and denoising processes in the modality-shared latent space, facilitated by our Dual Path Variational AutoEncoder (DP-VAE). Moreover, we introduce the joint-modality embedder, which incorporates a gated cross-attention mechanism to link layout and text conditions. Meanwhile, the advanced Long-CLIP is employed for long caption embedding to improve user guidance. Through extensive experiments, DiffX demonstrates robustness and flexibility in cross-modal generation across three RGB+X datasets: FLIR, MFNet, and COME15K, guided by various layout types. It also shows the potential for adaptive generation of ``RGB+X+Y'' or more diverse modalities. Our code and constructed cross-modal image datasets are available at https://github.com/zeyuwang-zju/DiffX.
UP-Diff: Latent Diffusion Model for Remote Sensing Urban Prediction
Jul 16, 2024This study introduces a novel Remote Sensing (RS) Urban Prediction (UP) task focused on future urban planning, which aims to forecast urban layouts by utilizing information from existing urban layouts and planned change maps. To address the proposed RS UP task, we propose UP-Diff, which leverages a Latent Diffusion Model (LDM) to capture positionaware embeddings of pre-change urban layouts and planned change maps. In specific, the trainable cross-attention layers within UP-Diff's iterative diffusion modules enable the model to dynamically highlight crucial regions for targeted modifications. By utilizing our UP-Diff, designers can effectively refine and adjust future urban city plans by making modifications to the change maps in a dynamic and adaptive manner. Compared with conventional RS Change Detection (CD) methods, the proposed UP-Diff for the RS UP task avoids the requirement of paired prechange and post-change images, which enhances the practical usage in city development. Experimental results on LEVIRCD and SYSU-CD datasets show UP-Diff's ability to accurately predict future urban layouts with high fidelity, demonstrating its potential for urban planning. Code and model weights will be available upon the acceptance of the work.
Action-OOD: An End-to-End Skeleton-Based Model for Robust Out-of-Distribution Human Action Detection
May 31, 2024



Human action recognition is a crucial task in computer vision systems. However, in real-world scenarios, human actions often fall outside the distribution of training data, requiring a model to both recognize in-distribution (ID) actions and reject out-of-distribution (OOD) ones. Despite its importance, there has been limited research on OOD detection in human actions. Existing works on OOD detection mainly focus on image data with RGB structure, and many methods are post-hoc in nature. While these methods are convenient and computationally efficient, they often lack sufficient accuracy and fail to consider the presence of OOD samples. To address these challenges, we propose a novel end-to-end skeleton-based model called Action-OOD, specifically designed for OOD human action detection. Unlike some existing approaches that may require prior knowledge of existing OOD data distribution, our model solely utilizes in-distribution (ID) data during the training stage, effectively mitigating the overconfidence issue prevalent in OOD detection. We introduce an attention-based feature fusion block, which enhances the model's capability to recognize unknown classes while preserving classification accuracy for known classes. Further, we present a novel energy-based loss function and successfully integrate it with the traditional cross-entropy loss to maximize the separation of data distributions between ID and OOD. Through extensive experiments conducted on NTU-RGB+D 60, NTU-RGB+D 120, and Kinetics-400 datasets, we demonstrate the superior performance of our proposed approach compared to state-of-the-art methods. Our findings underscore the effectiveness of classic OOD detection techniques in the context of skeleton-based action recognition tasks, offering promising avenues for future research in this field. Code will be available at: https://github.com/YilliaJing/Action-OOD.git.
Amplitude-Phase Fusion for Enhanced Electrocardiogram Morphological Analysis
Apr 15, 2024Considering the variability of amplitude and phase patterns in electrocardiogram (ECG) signals due to cardiac activity and individual differences, existing entropy-based studies have not fully utilized these two patterns and lack integration. To address this gap, this paper proposes a novel fusion entropy metric, morphological ECG entropy (MEE) for the first time, specifically designed for ECG morphology, to comprehensively describe the fusion of amplitude and phase patterns. MEE is computed based on beat-level samples, enabling detailed analysis of each cardiac cycle. Experimental results demonstrate that MEE achieves rapid, accurate, and label-free localization of abnormal ECG arrhythmia regions. Furthermore, MEE provides a method for assessing sample diversity, facilitating compression of imbalanced training sets (via representative sample selection), and outperforms random pruning. Additionally, MEE exhibits the ability to describe areas of poor quality. By discussing, it proves the robustness of MEE value calculation to noise interference and its low computational complexity. Finally, we integrate this method into a clinical interactive interface to provide a more convenient and intuitive user experience. These findings indicate that MEE serves as a valuable clinical descriptor for ECG characterization. The implementation code can be referenced at the following link: https://github.com/fdu-harry/ECG-MEE-metric.