 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-VQA: Conflict- and Correlation-Aware Method for Mitigating Knowledge Conflict in Knowledge-Based Visual Question Answering
Feb 27, 2026Knowledge-based visual question answering (KB-VQA) demonstrates significant potential for handling knowledge-intensive tasks. However, conflicts arise between static parametric knowledge in vision language models (VLMs) and dynamically retrieved information due to the static model knowledge from pre-training. The outputs either ignore retrieved contexts or exhibit inconsistent integration with parametric knowledge, posing substantial challenges for KB-VQA. Current knowledge conflict mitigation methods primarily adapted from language-based approaches, focusing on context-level conflicts through engineered prompting strategies or context-aware decoding mechanisms. However, these methods neglect the critical role of visual information in conflicts and suffer from redundant retrieved contexts, which impair accurate conflict identification and effective mitigation. To address these limitations, we propose \textbf{CC-VQA}: a novel training-free, conflict- and correlation-aware method for KB-VQA. Our method comprises two core components: (1) Vision-Centric Contextual Conflict Reasoning, which performs visual-semantic conflict analysis across internal and external knowledge contexts; and (2) Correlation-Guided Encoding and Decoding, featuring positional encoding compression for low-correlation statements and adaptive decoding using correlation-weighted conflict scoring. Extensive evaluations on E-VQA, InfoSeek, and OK-VQA benchmarks demonstrate that CC-VQA achieves state-of-the-art performance, yielding absolute accuracy improvements of 3.3\% to 6.4\% compared to existing methods. Code is available at https://github.com/cqu-student/CC-VQA.
Sketch-in-Latents: Eliciting Unified Reasoning in MLLMs
Dec 18, 2025While Multimodal Large Language Models (MLLMs) excel at visual understanding tasks through text reasoning, they often fall short in scenarios requiring visual imagination. Unlike current works that take predefined external toolkits or generate images during thinking, however, humans can form flexible visual-text imagination and interactions during thinking without predefined toolkits, where one important reason is that humans construct the visual-text thinking process in a unified space inside the brain. Inspired by this capability, given that current MLLMs already encode visual and text information in the same feature space, we hold that visual tokens can be seamlessly inserted into the reasoning process carried by text tokens, where ideally, all visual imagination processes can be encoded by the latent features. To achieve this goal, we propose Sketch-in-Latents (SkiLa), a novel paradigm for unified multi-modal reasoning that expands the auto-regressive capabilities of MLLMs to natively generate continuous visual embeddings, termed latent sketch tokens, as visual thoughts. During multi-step reasoning, the model dynamically alternates between textual thinking mode for generating textual think tokens and visual sketching mode for generating latent sketch tokens. A latent visual semantics reconstruction mechanism is proposed to ensure these latent sketch tokens are semantically grounded. Extensive experiments demonstrate that SkiLa achieves superior performance on vision-centric tasks while exhibiting strong generalization to diverse general multi-modal benchmarks. Codes will be released at https://github.com/TungChintao/SkiLa.
Re-ranking Reasoning Context with Tree Search Makes Large Vision-Language Models Stronger
Jun 09, 2025Recent advancements in Large Vision Language Models (LVLMs) have significantly improved performance in Visual Question Answering (VQA) tasks through multimodal Retrieval-Augmented Generation (RAG). However, existing methods still face challenges, such as the scarcity of knowledge with reasoning examples and erratic responses from retrieved knowledge. To address these issues, in this study, we propose a multimodal RAG framework, termed RCTS, which enhances LVLMs by constructing a Reasoning Context-enriched knowledge base and a Tree Search re-ranking method. Specifically, we introduce a self-consistent evaluation mechanism to enrich the knowledge base with intrinsic reasoning patterns. We further propose a Monte Carlo Tree Search with Heuristic Rewards (MCTS-HR) to prioritize the most relevant examples. This ensures that LVLMs can leverage high-quality contextual reasoning for better and more consistent responses. Extensive experiments demonstrate that our framework achieves state-of-the-art performance on multiple VQA datasets, significantly outperforming In-Context Learning (ICL) and Vanilla-RAG methods. It highlights the effectiveness of our knowledge base and re-ranking method in improving LVLMs. Our code is available at https://github.com/yannqi/RCTS-RAG.
No Parameters, No Problem: 3D Gaussian Splatting without Camera Intrinsics and Extrinsics
Feb 27, 2025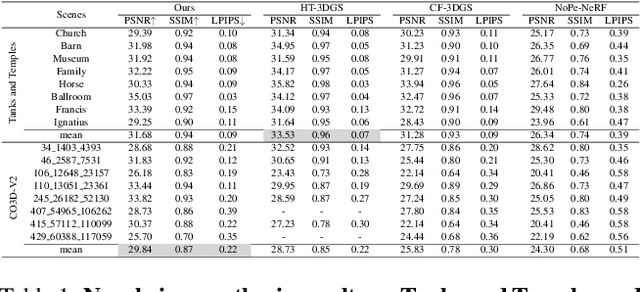
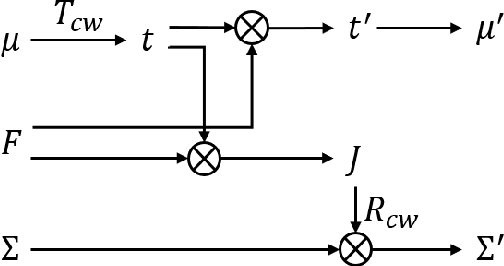
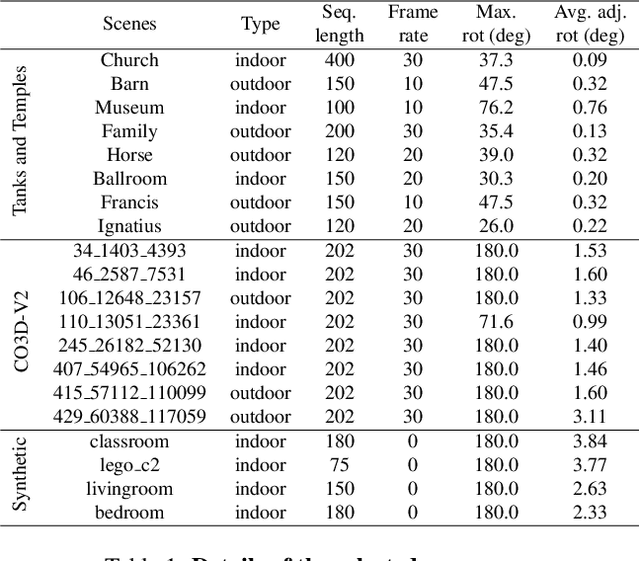
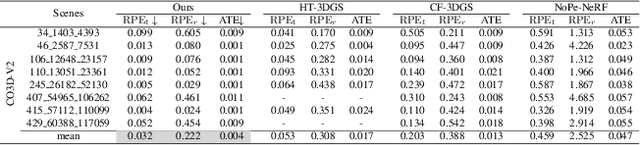
While 3D Gaussian Splatting (3DGS) has made significant progress in scene reconstruction and novel view synthesis, it still heavily relies on accurately pre-computed camera intrinsics and extrinsics, such as focal length and camera poses. In order to mitigate this dependency, the previous efforts have focused on optimizing 3DGS without the need for camera poses, yet camera intrinsics remain necessary. To further loose the requirement, we propose a joint optimization method to train 3DGS from an image collection without requiring either camera intrinsics or extrinsics. To achieve this goal, we introduce several key improvements during the joint training of 3DGS. We theoretically derive the gradient of the camera intrinsics, allowing the camera intrinsics to be optimized simultaneously during training. Moreover, we integrate global track information and select the Gaussian kernels associated with each track, which will be trained and automatically rescaled to an infinitesimally small size, closely approximating surface points, and focusing on enforcing multi-view consistency and minimizing reprojection errors, while the remaining kernels continue to serve their original roles. This hybrid training strategy nicely unifies the camera parameters estimation and 3DGS training. Extensive evaluations demonstrate that the proposed method achieves state-of-the-art (SOTA) performance on both public and synthetic datasets.
CoL3D: Collaborative Learning of Single-view Depth and Camera Intrinsics for Metric 3D Shape Recovery
Feb 13, 2025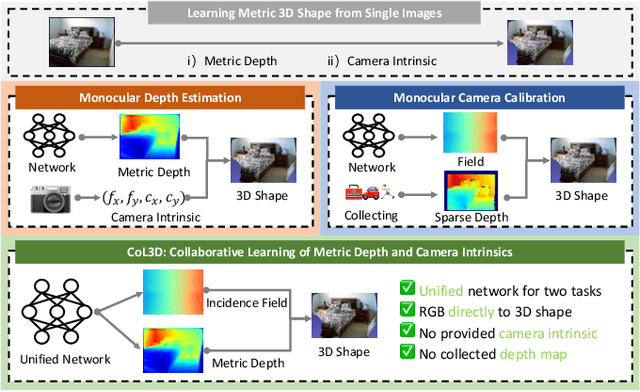
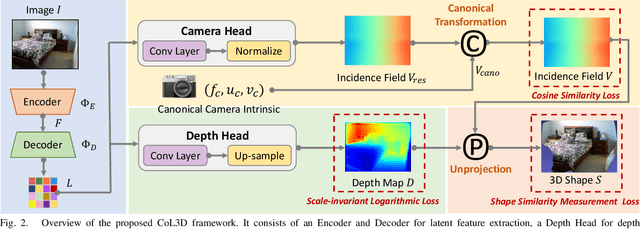


Recovering the metric 3D shape from a single image is particularly relevant for robotics and embodied intelligence applications, where accurate spatial understanding is crucial for navigation and interaction with environments. Usually, the mainstream approaches achieve it through monocular depth estimation. However, without camera intrinsics, the 3D metric shape can not be recovered from depth alone. In this study, we theoretically demonstrate that depth serves as a 3D prior constraint for estimating camera intrinsics and uncover the reciprocal relations between these two elements. Motivated by this, we propose a collaborative learning framework for jointly estimating depth and camera intrinsics, named CoL3D, to learn metric 3D shapes from single images. Specifically, CoL3D adopts a unified network and performs collaborative optimization at three levels: depth, camera intrinsics, and 3D point clouds. For camera intrinsics, we design a canonical incidence field mechanism as a prior that enables the model to learn the residual incident field for enhanced calibration. Additionally, we incorporate a shape similarity measurement loss in the point cloud space, which improves the quality of 3D shapes essential for robotic applications. As a result, when training and testing on a single dataset with in-domain settings, CoL3D delivers outstanding performance in both depth estimation and camera calibration across several indoor and outdoor benchmark datasets, which leads to remarkable 3D shape quality for the perception capabilities of robots.
PTZ-Calib: Robust Pan-Tilt-Zoom Camera Calibration
Feb 13, 2025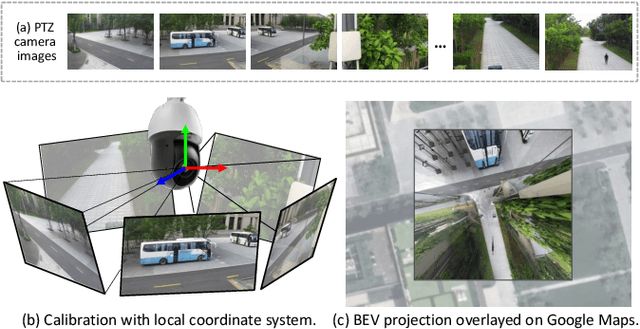
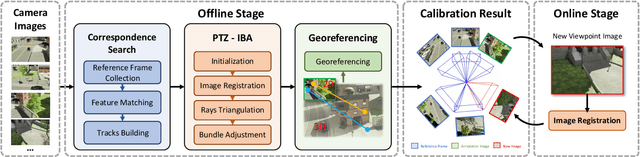
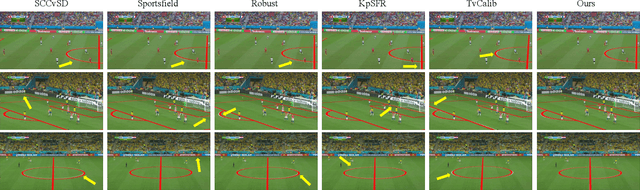
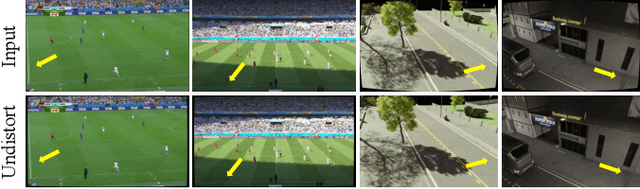
In this paper, we present PTZ-Calib, a robust two-stage PTZ camera calibration method, that efficiently and accurately estimates camera parameters for arbitrary viewpoints. Our method includes an offline and an online stage. In the offline stage, we first uniformly select a set of reference images that sufficiently overlap to encompass a complete 360{\deg} view. We then utilize the novel PTZ-IBA (PTZ Incremental Bundle Adjustment) algorithm to automatically calibrate the cameras within a local coordinate system. Additionally, for practical application, we can further optimize camera parameters and align them with the geographic coordinate system using extra global reference 3D information. In the online stage, we formulate the calibration of any new viewpoints as a relocalization problem. Our approach balances the accuracy and computational efficiency to meet real-world demands. Extensive evaluations demonstrate our robustness and superior performance over state-of-the-art methods on various real and synthetic datasets. Datasets and source code can be accessed online at https://github.com/gjgjh/PTZ-Calib
HybridGS: Decoupling Transients and Statics with 2D and 3D Gaussian Splatting
Dec 05, 2024



Generating high-quality novel view renderings of 3D Gaussian Splatting (3DGS) in scenes featuring transient objects is challenging. We propose a novel hybrid representation, termed as HybridGS, using 2D Gaussians for transient objects per image and maintaining traditional 3D Gaussians for the whole static scenes. Note that, the 3DGS itself is better suited for modeling static scenes that assume multi-view consistency, but the transient objects appear occasionally and do not adhere to the assumption, thus we model them as planar objects from a single view, represented with 2D Gaussians. Our novel representation decomposes the scene from the perspective of fundamental viewpoint consistency, making it more reasonable. Additionally, we present a novel multi-view regulated supervision method for 3DGS that leverages information from co-visible regions, further enhancing the distinctions between the transients and statics. Then, we propose a straightforward yet effective multi-stage training strategy to ensure robust training and high-quality view synthesis across various settings. Experiments on benchmark datasets show our state-of-the-art performance of novel view synthesis in both indoor and outdoor scenes, even in the presence of distracting elements.
AddressCLIP: Empowering Vision-Language Models for City-wide Image Address Localization
Jul 11, 2024



In this study, we introduce a new problem raised by social media and photojournalism, named Image Address Localization (IAL), which aims to predict the readable textual address where an image was taken. Existing two-stage approaches involve predicting geographical coordinates and converting them into human-readable addresses, which can lead to ambiguity and be resource-intensive. In contrast, we propose an end-to-end framework named AddressCLIP to solve the problem with more semantics, consisting of two key ingredients: i) image-text alignment to align images with addresses and scene captions by contrastive learning, and ii) image-geography matching to constrain image features with the spatial distance in terms of manifold learning. Additionally, we have built three datasets from Pittsburgh and San Francisco on different scales specifically for the IAL problem. Experiments demonstrate that our approach achieves compelling performance on the proposed datasets and outperforms representative transfer learning methods for vision-language models. Furthermore, extensive ablations and visualizations exhibit the effectiveness of the proposed method. The datasets and source code are available at https://github.com/xsx1001/AddressCLIP.
Learning Neural Volumetric Pose Features for Camera Localization
Mar 19, 2024



We introduce a novel neural volumetric pose feature, termed PoseMap, designed to enhance camera localization by encapsulating the information between images and the associated camera poses. Our framework leverages an Absolute Pose Regression (APR) architecture, together with an augmented NeRF module. This integration not only facilitates the generation of novel views to enrich the training dataset but also enables the learning of effective pose features. Additionally, we extend our architecture for self-supervised online alignment, allowing our method to be used and fine-tuned for unlabelled images within a unified framework. Experiments demonstrate that our method achieves 14.28% and 20.51% performance gain on average in indoor and outdoor benchmark scenes, outperforming existing APR methods with state-of-the-art accuracy.
Homography Loss for Monocular 3D Object Detection
Apr 02, 2022
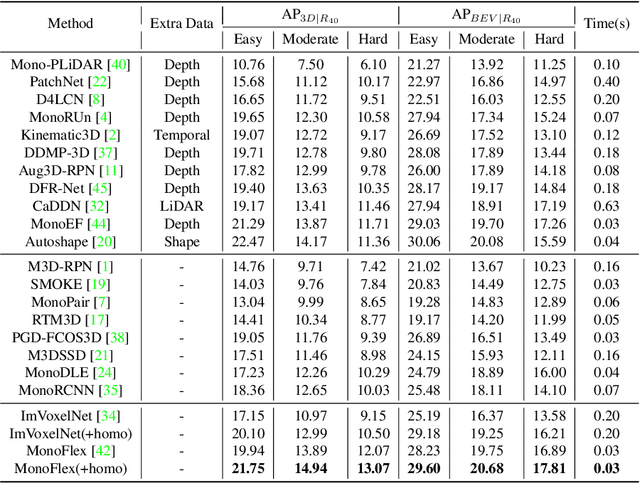
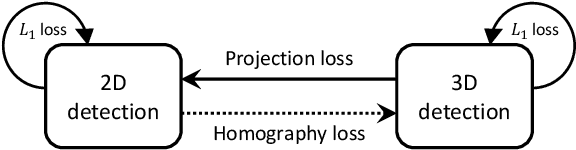
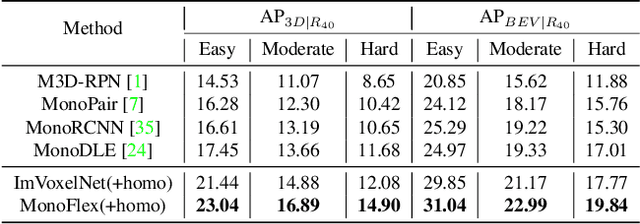
Monocular 3D object detection is an essential task in autonomous driving. However, most current methods consider each 3D object in the scene as an independent training sample, while ignoring their inherent geometric relations, thus inevitably resulting in a lack of leveraging spatial constraints. In this paper, we propose a novel method that takes all the objects into consideration and explores their mutual relationships to help better estimate the 3D boxes. Moreover, since 2D detection is more reliable currently, we also investigate how to use the detected 2D boxes as guidance to globally constrain the optimization of the corresponding predicted 3D boxes. To this end, a differentiable loss function, termed as Homography Loss, is proposed to achieve the goal, which exploits both 2D and 3D information, aiming at balancing the positional relationships between different objects by global constraints, so as to obtain more accurately predicted 3D boxes. Thanks to the concise design, our loss function is universal and can be plugged into any mature monocular 3D detector, while significantly boosting the performance over their baseline. Experiments demonstrate that our method yields the best performance (Nov. 2021) compared with the other state-of-the-arts by a large margin on KITTI 3D datasets.