 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Perspective Subimage CLIP with Keyword Guidance for Remote Sensing Image-Text Retrieval
Jan 26, 2026Vision-Language Pre-training (VLP) models like CLIP have significantly advanced Remote Sensing Image-Text Retrieval (RSITR). However, existing methods predominantly rely on coarse-grained global alignment, which often overlooks the dense, multi-scale semantics inherent in overhead imagery. Moreover, adapting these heavy models via full fine-tuning incurs prohibitive computational costs and risks catastrophic forgetting. To address these challenges, we propose MPS-CLIP, a parameter-efficient framework designed to shift the retrieval paradigm from global matching to keyword-guided fine-grained alignment. Specifically, we leverage a Large Language Model (LLM) to extract core semantic keywords, guiding the Segment Anything Model (SamGeo) to generate semantically relevant sub-perspectives. To efficiently adapt the frozen backbone, we introduce a Gated Global Attention (G^2A) adapter, which captures global context and long-range dependencies with minimal overhead. Furthermore, a Multi-Perspective Representation (MPR) module aggregates these local cues into robust multi-perspective embeddings. The framework is optimized via a hybrid objective combining multi-perspective contrastive and weighted triplet losses, which dynamically selects maximum-response perspectives to suppress noise and enforce precise semantic matching. Extensive experiments on the RSICD and RSITMD benchmarks demonstrate that MPS-CLIP achieves state-of-the-art performance with 35.18% and 48.40% mean Recall (mR), respectively, significantly outperforming full fine-tuning baselines and recent competitive methods. Code is available at https://github.com/Lcrucial1f/MPS-CLIP.
Gene Incremental Learning for Single-Cell Transcriptomics
Nov 14, 2025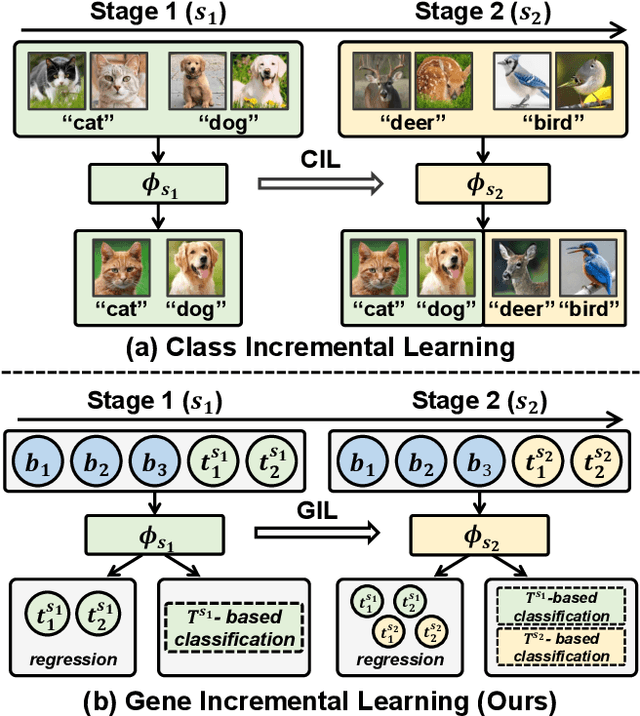
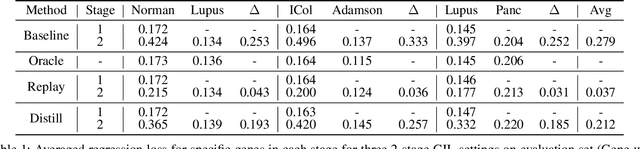
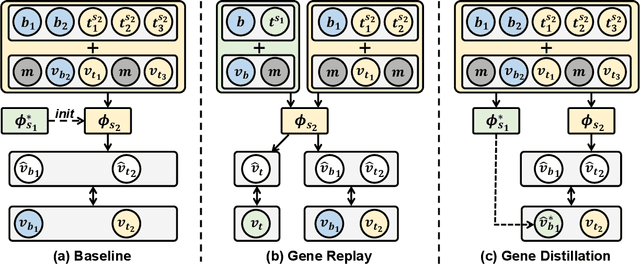
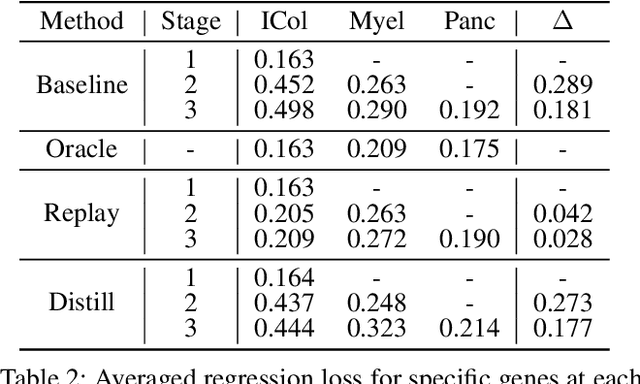
Classes, as fundamental elements of Computer Vision, have been extensively studied within incremental learning frameworks. In contrast, tokens, which play essential roles in many research fields, exhibit similar characteristics of growth, yet investigations into their incremental learning remain significantly scarce. This research gap primarily stems from the holistic nature of tokens in language, which imposes significant challenges on the design of incremental learning frameworks for them. To overcome this obstacle, in this work, we turn to a type of token, gene, for a large-scale biological dataset--single-cell transcriptomics--to formulate a pipeline for gene incremental learning and establish corresponding evaluations. We found that the forgetting problem also exists in gene incremental learning, thus we adapted existing class incremental learning methods to mitigate the forgetting of genes. Through extensive experiments, we demonstrated the soundness of our framework design and evaluations, as well as the effectiveness of our method adaptations. Finally, we provide a complete benchmark for gene incremental learning in single-cell transcriptomics.
AFM-Net: Advanced Fusing Hierarchical CNN Visual Priors with Global Sequence Modeling for Remote Sensing Image Scene Classification
Oct 31, 2025



Remote sensing image scene classification remains a challenging task, primarily due to the complex spatial structures and multi-scale characteristics of ground objects. Existing approaches see CNNs excel at modeling local textures, while Transformers excel at capturing global context. However, efficiently integrating them remains a bottleneck due to the high computational cost of Transformers. To tackle this, we propose AFM-Net, a novel Advanced Hierarchical Fusing framework that achieves effective local and global co-representation through two pathways: a CNN branch for extracting hierarchical visual priors, and a Mamba branch for efficient global sequence modeling. The core innovation of AFM-Net lies in its Hierarchical Fusion Mechanism, which progressively aggregates multi-scale features from both pathways, enabling dynamic cross-level feature interaction and contextual reconstruction to produce highly discriminative representations. These fused features are then adaptively routed through a Mixture-of-Experts classifier module, which dispatches them to the most suitable experts for fine-grained scene recognition. Experiments on AID, NWPU-RESISC45, and UC Merced show that AFM-Net obtains 93.72, 95.54, and 96.92 percent accuracy, surpassing state-of-the-art methods with balanced performance and efficiency. Code is available at https://github.com/tangyuanhao-qhu/AFM-Net.
A Fast and Lightweight Model for Causal Audio-Visual Speech Separation
Jun 07, 2025Audio-visual speech separation (AVSS) aims to extract a target speech signal from a mixed signal by leveraging both auditory and visual (lip movement) cues. However, most existing AVSS methods exhibit complex architectures and rely on future context, operating offline, which renders them unsuitable for real-time applications. Inspired by the pipeline of RTFSNet, we propose a novel streaming AVSS model, named Swift-Net, which enhances the causal processing capabilities required for real-time applications. Swift-Net adopts a lightweight visual feature extraction module and an efficient fusion module for audio-visual integration. Additionally, Swift-Net employs Grouped SRUs to integrate historical information across different feature spaces, thereby improving the utilization efficiency of historical information. We further propose a causal transformation template to facilitate the conversion of non-causal AVSS models into causal counterparts. Experiments on three standard benchmark datasets (LRS2, LRS3, and VoxCeleb2) demonstrated that under causal conditions, our proposed Swift-Net exhibited outstanding performance, highlighting the potential of this method for processing speech in complex environments.
GDSR: Global-Detail Integration through Dual-Branch Network with Wavelet Losses for Remote Sensing Image Super-Resolution
Jan 07, 2025In recent years, deep neural networks, including Convolutional Neural Networks, Transformers, and State Space Models, have achieved significant progress in Remote Sensing Image (RSI) Super-Resolution (SR). However, existing SR methods typically overlook the complementary relationship between global and local dependencies. These methods either focus on capturing local information or prioritize global information, which results in models that are unable to effectively capture both global and local features simultaneously. Moreover, their computational cost becomes prohibitive when applied to large-scale RSIs. To address these challenges, we introduce the novel application of Receptance Weighted Key Value (RWKV) to RSI-SR, which captures long-range dependencies with linear complexity. To simultaneously model global and local features, we propose the Global-Detail dual-branch structure, GDSR, which performs SR reconstruction by paralleling RWKV and convolutional operations to handle large-scale RSIs. Furthermore, we introduce the Global-Detail Reconstruction Module (GDRM) as an intermediary between the two branches to bridge their complementary roles. In addition, we propose Wavelet Loss, a loss function that effectively captures high-frequency detail information in images, thereby enhancing the visual quality of SR, particularly in terms of detail reconstruction. Extensive experiments on several benchmarks, including AID, AID_CDM, RSSRD-QH, and RSSRD-QH_CDM, demonstrate that GSDR outperforms the state-of-the-art Transformer-based method HAT by an average of 0.05 dB in PSNR, while using only 63% of its parameters and 51% of its FLOPs, achieving an inference speed 2.9 times faster. Furthermore, the Wavelet Loss shows excellent generalization across various architectures, providing a novel perspective for RSI-SR enhancement.
HES-UNet: A U-Net for Hepatic Echinococcosis Lesion Segmentation
Dec 09, 2024Hepatic echinococcosis (HE) is a prevalent disease in economically underdeveloped pastoral areas, where adequate medical resources are usually lacking. Existing methods often ignore multi-scale feature fusion or focus only on feature fusion between adjacent levels, which may lead to insufficient feature fusion. To address these issues, we propose HES-UNet, an efficient and accurate model for HE lesion segmentation. This model combines convolutional layers and attention modules to capture local and global features. During downsampling, the multi-directional downsampling block (MDB) is employed to integrate high-frequency and low-frequency features, effectively extracting image details. The multi-scale aggregation block (MAB) aggregates multi-scale feature information. In contrast, the multi-scale upsampling Block (MUB) learns highly abstract features and supplies this information to the skip connection module to fuse multi-scale features. Due to the distinct regional characteristics of HE, there is currently no publicly available high-quality dataset for training our model. We collected CT slice data from 268 patients at a certain hospital to train and evaluate the model. The experimental results show that HES-UNet achieves state-of-the-art performance on our dataset, achieving an overall Dice Similarity Coefficient (DSC) of 89.21%, which is 1.09% higher than that of TransUNet. The project page is available at https://chenjiayan-qhu.github.io/HES-UNet-page.
Efficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction
Aug 29, 2024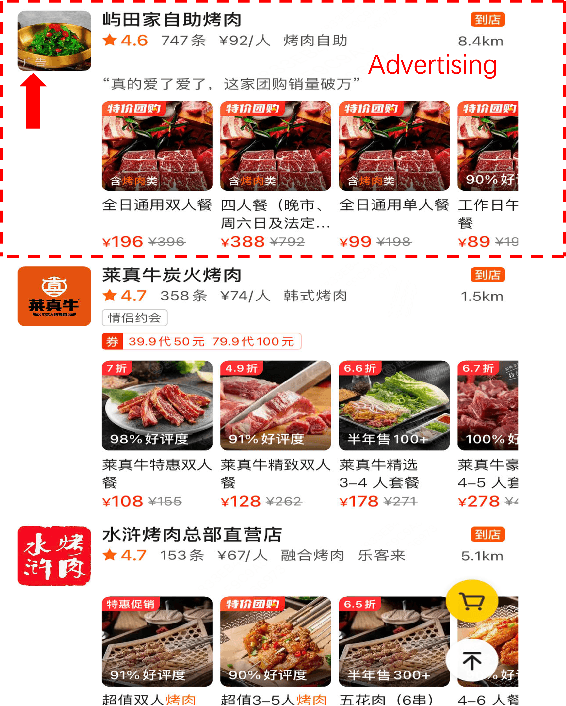
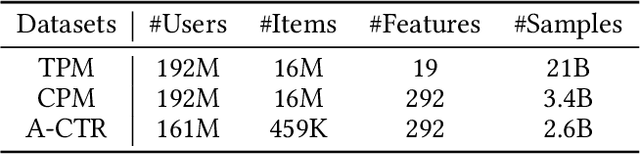
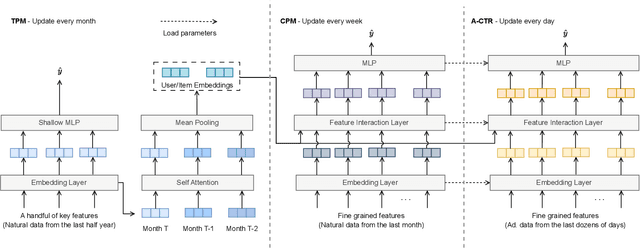
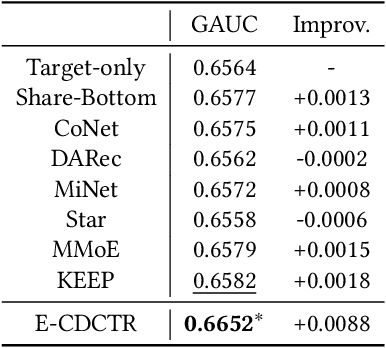
Natural content and advertisement coexist in industrial recommendation systems but differ in data distribution. Concretely, traffic related to the advertisement is considerably sparser compared to that of natural content, which motivates the development of transferring knowledge from the richer source natural content domain to the sparser advertising domain. The challenges include the inefficiencies arising from the management of extensive source data and the problem of 'catastrophic forgetting' that results from the CTR model's daily updating. To this end, we propose a novel tri-level asynchronous framework, i.e., Efficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction (E-CDCTR), to transfer comprehensive knowledge of natural content to advertisement CTR models. This framework consists of three key components: Tiny Pre-training Model ((TPM), which trains a tiny CTR model with several basic features on long-term natural data; Complete Pre-training Model (CPM), which trains a CTR model holding network structure and input features the same as target advertisement on short-term natural data; Advertisement CTR model (A-CTR), which derives its parameter initialization from CPM together with multiple historical embeddings from TPM as extra feature and then fine-tunes on advertisement data. TPM provides richer representations of user and item for both the CPM and A-CTR, effectively alleviating the forgetting problem inherent in the daily updates. CPM further enhances the advertisement model by providing knowledgeable initialization, thereby alleviating the data sparsity challenges typically encountered by advertising CTR models. Such a tri-level cross-domain transfer learning framework offers an efficient solution to address both data sparsity and `catastrophic forgetting', yielding remarkable improvements.
BERP: A Blind Estimator of Room Acoustic and Physical Parameters for Single-Channel Noisy Speech Signals
May 07, 2024



Room acoustic parameters (RAPs) and room physical parameters ( RPPs) are essential metrics for parameterizing the room acoustical characteristics (RAC) of a sound field around a listener's local environment, offering comprehensive indications for various applications. The current RAPs and RPPs estimation methods either fall short of covering broad real-world acoustic environments in the context of real background noise or lack universal frameworks for blindly estimating RAPs and RPPs from noisy single-channel speech signals, particularly sound source distances, direction-of-arrival (DOA) of sound sources, and occupancy levels. On the other hand, in this paper, we propose a novel universal blind estimation framework called the blind estimator of room acoustical and physical parameters (BERP), by introducing a new stochastic room impulse response (RIR) model, namely, the sparse stochastic impulse response (SSIR) model, and endowing the BERP with a unified encoder and multiple separate predictors to estimate RPPs and SSIR parameters in parallel. This estimation framework enables the computationally efficient and universal estimation of room parameters by solely using noisy single-channel speech signals. Finally, all the RAPs can be simultaneously derived from the RIRs synthesized from SSIR model with the estimated parameters. To evaluate the effectiveness of the proposed BERP and SSIR models, we compile a task-specific dataset from several publicly available datasets. The results reveal that the BERP achieves state-of-the-art (SOTA) performance. Moreover, the evaluation results pertaining to the SSIR RIR model also demonstrated its efficacy. The code is available on GitHub.
ARFA: An Asymmetric Receptive Field Autoencoder Model for Spatiotemporal Prediction
Sep 01, 2023Spatiotemporal prediction aims to generate future sequences by paradigms learned from historical contexts. It holds significant importance in numerous domains, including traffic flow prediction and weather forecasting. However, existing methods face challenges in handling spatiotemporal correlations, as they commonly adopt encoder and decoder architectures with identical receptive fields, which adversely affects prediction accuracy. This paper proposes an Asymmetric Receptive Field Autoencoder (ARFA) model to address this issue. Specifically, we design corresponding sizes of receptive field modules tailored to the distinct functionalities of the encoder and decoder. In the encoder, we introduce a large kernel module for global spatiotemporal feature extraction. In the decoder, we develop a small kernel module for local spatiotemporal information reconstruction. To address the scarcity of meteorological prediction data, we constructed the RainBench, a large-scale radar echo dataset specific to the unique precipitation characteristics of inland regions in China for precipitation prediction. Experimental results demonstrate that ARFA achieves consistent state-of-the-art performance on two mainstream spatiotemporal prediction datasets and our RainBench dataset, affirming the effectiveness of our approach. This work not only explores a novel method from the perspective of receptive fields but also provides data support for precipitation prediction, thereby advancing future research in spatiotemporal prediction.
Structural and Statistical Texture Knowledge Distillation for Semantic Segmentation
May 06, 2023Existing knowledge distillation works for semantic segmentation mainly focus on transferring high-level contextual knowledge from teacher to student. However, low-level texture knowledge is also of vital importance for characterizing the local structural pattern and global statistical property, such as boundary, smoothness, regularity and color contrast, which may not be well addressed by high-level deep features. In this paper, we are intended to take full advantage of both structural and statistical texture knowledge and propose a novel Structural and Statistical Texture Knowledge Distillation (SSTKD) framework for semantic segmentation. Specifically, for structural texture knowledge, we introduce a Contourlet Decomposition Module (CDM) that decomposes low-level features with iterative Laplacian pyramid and directional filter bank to mine the structural texture knowledge. For statistical knowledge, we propose a Denoised Texture Intensity Equalization Module (DTIEM) to adaptively extract and enhance statistical texture knowledge through heuristics iterative quantization and denoised operation. Finally, each knowledge learning is supervised by an individual loss function, forcing the student network to mimic the teacher better from a broader perspective. Experiments show that the proposed method achieves state-of-the-art performance on Cityscapes, Pascal VOC 2012 and ADE20K datasets.