 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitating Video Story Interaction with Multi-Agent Collaborative System
May 02, 2025



Video story interaction enables viewers to engage with and explore narrative content for personalized experiences. However, existing methods are limited to user selection, specially designed narratives, and lack customization. To address this, we propose an interactive system based on user intent. Our system uses a Vision Language Model (VLM) to enable machines to understand video stories, combining Retrieval-Augmented Generation (RAG) and a Multi-Agent System (MAS) to create evolving characters and scene experiences. It includes three stages: 1) Video story processing, utilizing VLM and prior knowledge to simulate human understanding of stories across three modalities. 2) Multi-space chat, creating growth-oriented characters through MAS interactions based on user queries and story stages. 3) Scene customization, expanding and visualizing various story scenes mentioned in dialogue. Applied to the Harry Potter series, our study shows the system effectively portrays emergent character social behavior and growth, enhancing the interactive experience in the video story world.
HES-UNet: A U-Net for Hepatic Echinococcosis Lesion Segmentation
Dec 09, 2024Hepatic echinococcosis (HE) is a prevalent disease in economically underdeveloped pastoral areas, where adequate medical resources are usually lacking. Existing methods often ignore multi-scale feature fusion or focus only on feature fusion between adjacent levels, which may lead to insufficient feature fusion. To address these issues, we propose HES-UNet, an efficient and accurate model for HE lesion segmentation. This model combines convolutional layers and attention modules to capture local and global features. During downsampling, the multi-directional downsampling block (MDB) is employed to integrate high-frequency and low-frequency features, effectively extracting image details. The multi-scale aggregation block (MAB) aggregates multi-scale feature information. In contrast, the multi-scale upsampling Block (MUB) learns highly abstract features and supplies this information to the skip connection module to fuse multi-scale features. Due to the distinct regional characteristics of HE, there is currently no publicly available high-quality dataset for training our model. We collected CT slice data from 268 patients at a certain hospital to train and evaluate the model. The experimental results show that HES-UNet achieves state-of-the-art performance on our dataset, achieving an overall Dice Similarity Coefficient (DSC) of 89.21%, which is 1.09% higher than that of TransUNet. The project page is available at https://chenjiayan-qhu.github.io/HES-UNet-page.
Learning High-Quality Navigation and Zooming on Omnidirectional Images in Virtual Reality
May 01, 2024

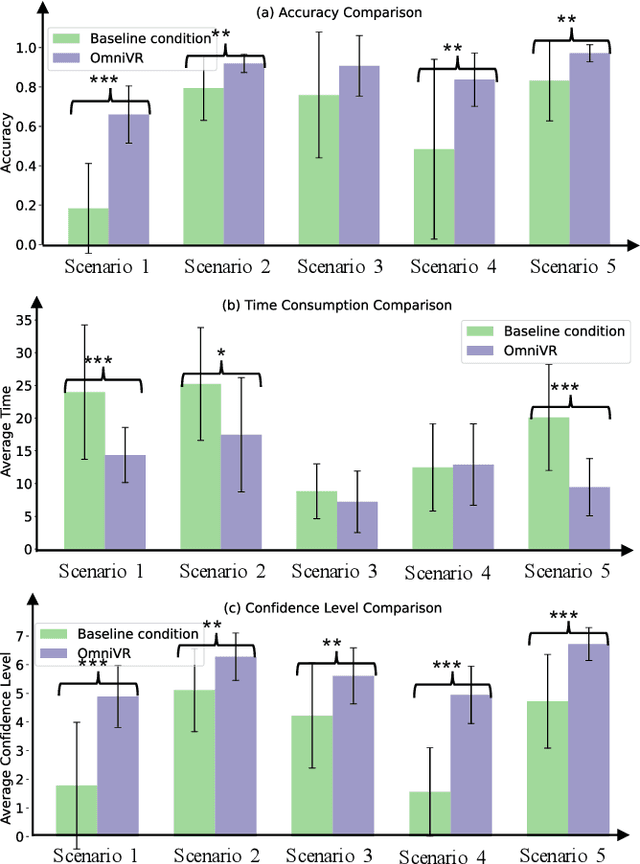

Viewing omnidirectional images (ODIs) in virtual reality (VR) represents a novel form of media that provides immersive experiences for users to navigate and interact with digital content. Nonetheless, this sense of immersion can be greatly compromised by a blur effect that masks details and hampers the user's ability to engage with objects of interest. In this paper, we present a novel system, called OmniVR, designed to enhance visual clarity during VR navigation. Our system enables users to effortlessly locate and zoom in on the objects of interest in VR. It captures user commands for navigation and zoom, converting these inputs into parameters for the Mobius transformation matrix. Leveraging these parameters, the ODI is refined using a learning-based algorithm. The resultant ODI is presented within the VR media, effectively reducing blur and increasing user engagement. To verify the effectiveness of our system, we first evaluate our algorithm with state-of-the-art methods on public datasets, which achieves the best performance. Furthermore, we undertake a comprehensive user study to evaluate viewer experiences across diverse scenarios and to gather their qualitative feedback from multiple perspectives. The outcomes reveal that our system enhances user engagement by improving the viewers' recognition, reducing discomfort, and improving the overall immersive experience. Our system makes the navigation and zoom more user-friendly.
Generative AI for Visualization: State of the Art and Future Directions
Apr 28, 2024



Generative AI (GenAI) has witnessed remarkable progress in recent years and demonstrated impressive performance in various generation tasks in different domains such as computer vision and computational design. Many researchers have attempted to integrate GenAI into visualization framework, leveraging the superior generative capacity for different operations. Concurrently, recent major breakthroughs in GenAI like diffusion model and large language model have also drastically increase the potential of GenAI4VIS. From a technical perspective, this paper looks back on previous visualization studies leveraging GenAI and discusses the challenges and opportunities for future research. Specifically, we cover the applications of different types of GenAI methods including sequence, tabular, spatial and graph generation techniques for different tasks of visualization which we summarize into four major stages: data enhancement, visual mapping generation, stylization and interaction. For each specific visualization sub-task, we illustrate the typical data and concrete GenAI algorithms, aiming to provide in-depth understanding of the state-of-the-art GenAI4VIS techniques and their limitations. Furthermore, based on the survey, we discuss three major aspects of challenges and research opportunities including evaluation, dataset, and the gap between end-to-end GenAI and generative algorithms. By summarizing different generation algorithms, their current applications and limitations, this paper endeavors to provide useful insights for future GenAI4VIS research.
Boost AI Power: Data Augmentation Strategies with unlabelled Data and Conformal Prediction, a Case in Alternative Herbal Medicine Discrimination with Electronic Nose
Feb 05, 2021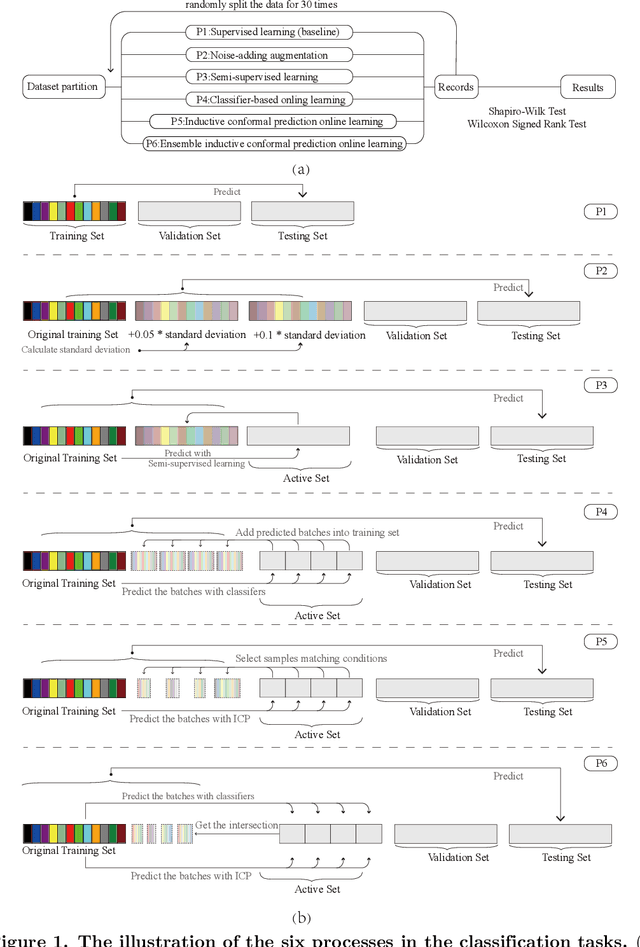
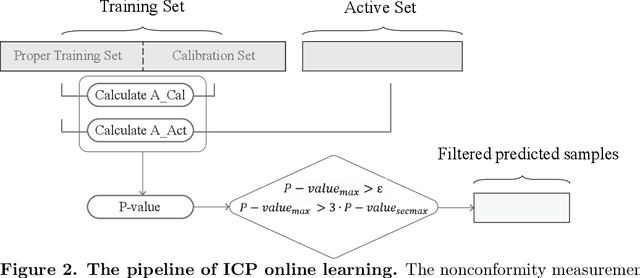
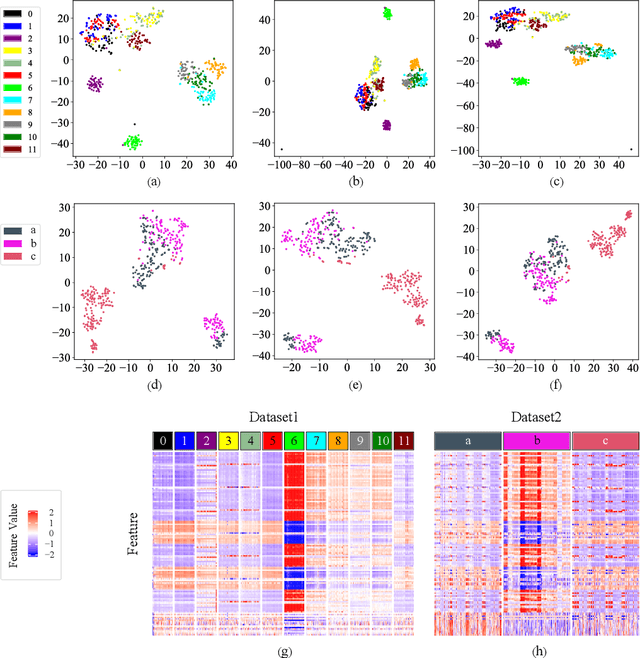
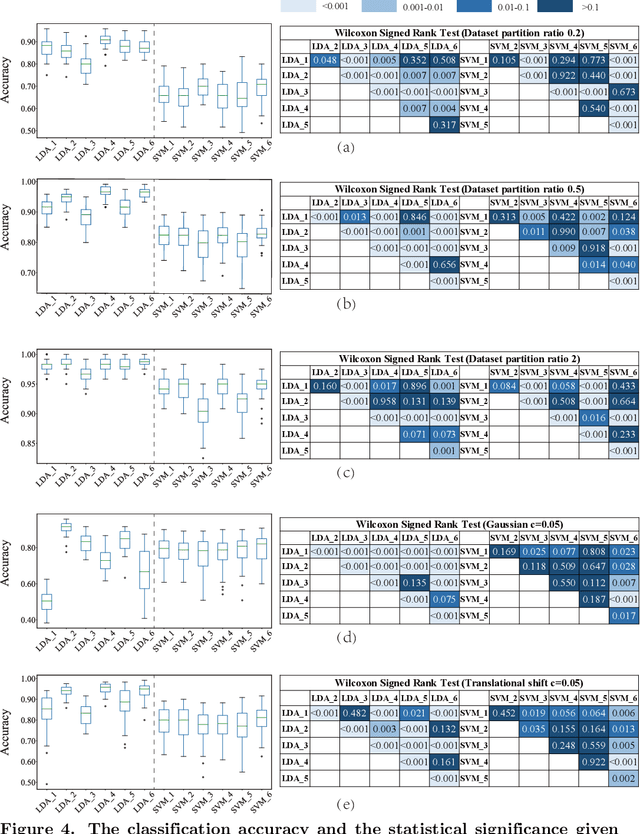
Electronic nose proves its effectiveness in alternativeherbal medicine classification, but due to the supervised learn-ing nature, previous research relies on the labelled training data,which are time-costly and labor-intensive to collect. Consideringthe training data inadequacy in real-world applications, this studyaims to improve classification accuracy via data augmentationstrategies. We stimulated two scenarios to investigate the effective-ness of five data augmentation strategies under different trainingdata inadequacy: in the noise-free scenario, different availability ofunlabelled data were simulated, and in the noisy scenario, differentlevels of Gaussian noises and translational shifts were added tosimulate sensor drifts. The augmentation strategies: noise-addingdata augmentation, semi-supervised learning, classifier-based online learning, inductive conformal prediction (ICP) onlinelearning and the novel ensemble ICP online learning proposed in this study, were compared against supervised learningbaseline, with Linear Discriminant Analysis (LDA) and Support Vector Machine (SVM) as the classifiers. We found thatat least one strategies significantly improved the classification accuracy with LDA(p<=0.05) and showed non-decreasingclassification accuracy with SVM in each tasks. Moreover, our novel strategy: ensemble ICP online learning outperformedthe others by showing non-decreasing classification accuracy on all tasks and significant improvement on most tasks(25/36 tasks,p<=0.05). This study provides a systematic analysis over augmentation strategies, and we provided userswith recommended strategies under specific circumstances. Furthermore, our newly proposed strategy showed botheffectiveness and robustness in boosting the classification model generalizability, which can also be further employed inother machine learning applications.
AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results
Nov 04, 2019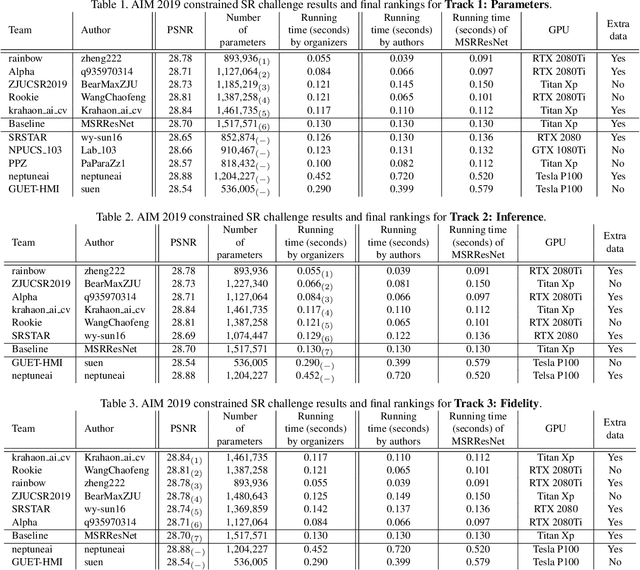
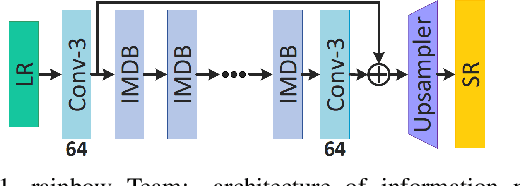
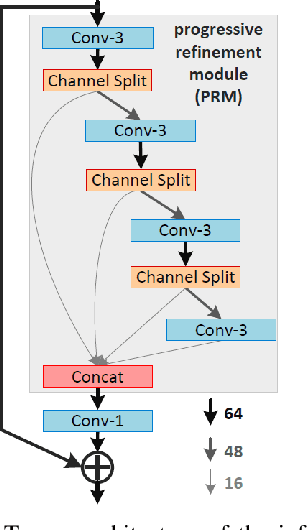
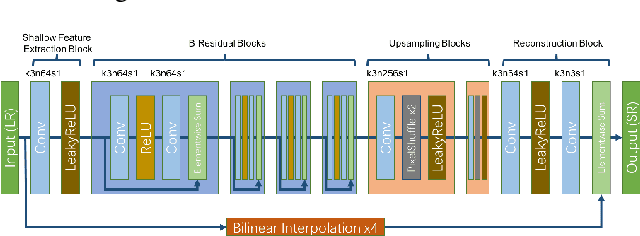
This paper reviews the AIM 2019 challenge on constrained example-based single image super-resolution with focus on proposed solutions and results. The challenge had 3 tracks. Taking the three main aspects (i.e., number of parameters, inference/running time, fidelity (PSNR)) of MSRResNet as the baseline, Track 1 aims to reduce the amount of parameters while being constrained to maintain or improve the running time and the PSNR result, Tracks 2 and 3 aim to optimize running time and PSNR result with constrain of the other two aspects, respectively. Each track had an average of 64 registered participants, and 12 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
An Amendment of Fast Subspace Tracking Methods
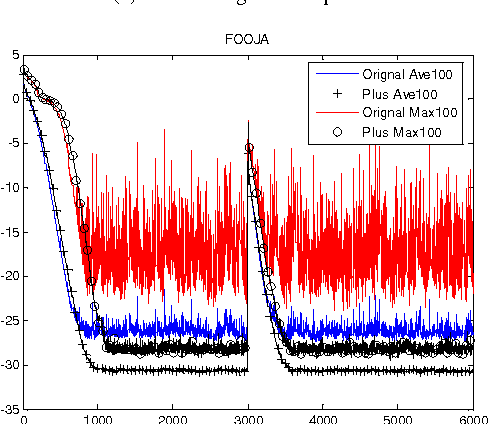
Feb 24, 2012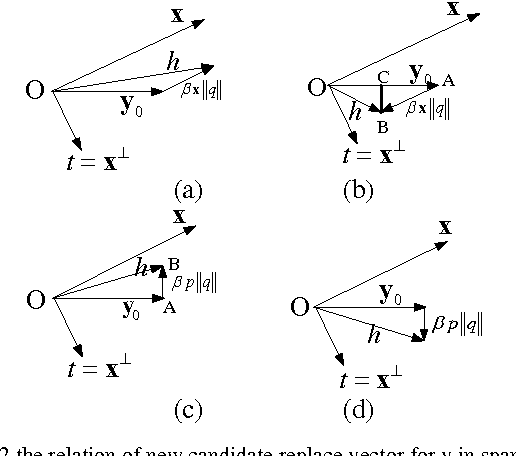
Tuning stepsize between convergence rate and steady state error level or stability is a problem in some subspace tracking schemes. Methods in DPM and OJA class may show sparks in their steady state error sometimes, even with a rather small stepsize. By a study on the schemes' updating formula, it is found that the update only happens in a specific plane but not all the subspace basis. Through an analysis on relationship between the vectors in that plane, an amendment as needed is made on the algorithm routine to fix the problem by constricting the stepsize at every update step. The simulation confirms elimination of the sparks.