 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Data Mixing from the Perspective of Large Language Models
Apr 09, 2026Data mixing strategy is essential for large language model (LLM) training. Empirical evidence shows that inappropriate strategies can significantly reduce generalization. Although recent methods have improved empirical performance, several fundamental questions remain open: what constitutes a domain, whether human and model perceptions of domains are aligned, and how domain weighting influences generalization. We address these questions by establishing formal connections between gradient dynamics and domain distributions, offering a theoretical framework that clarifies the role of domains in training dynamics. Building on this analysis, we introduce DoGraph, a reweighting framework that formulates data scheduling as a graph-constrained optimization problem. Extensive experiments on GPT-2 models of varying scales demonstrate that DoGraph consistently achieves competitive performance.
HGAN-SDEs: Learning Neural Stochastic Differential Equations with Hermite-Guided Adversarial Training
Dec 23, 2025Neural Stochastic Differential Equations (Neural SDEs) provide a principled framework for modeling continuous-time stochastic processes and have been widely adopted in fields ranging from physics to finance. Recent advances suggest that Generative Adversarial Networks (GANs) offer a promising solution to learning the complex path distributions induced by SDEs. However, a critical bottleneck lies in designing a discriminator that faithfully captures temporal dependencies while remaining computationally efficient. Prior works have explored Neural Controlled Differential Equations (CDEs) as discriminators due to their ability to model continuous-time dynamics, but such architectures suffer from high computational costs and exacerbate the instability of adversarial training. To address these limitations, we introduce HGAN-SDEs, a novel GAN-based framework that leverages Neural Hermite functions to construct a structured and efficient discriminator. Hermite functions provide an expressive yet lightweight basis for approximating path-level dynamics, enabling both reduced runtime complexity and improved training stability. We establish the universal approximation property of our framework for a broad class of SDE-driven distributions and theoretically characterize its convergence behavior. Extensive empirical evaluations on synthetic and real-world systems demonstrate that HGAN-SDEs achieve superior sample quality and learning efficiency compared to existing generative models for SDEs
Facilitating Video Story Interaction with Multi-Agent Collaborative System
May 02, 2025



Video story interaction enables viewers to engage with and explore narrative content for personalized experiences. However, existing methods are limited to user selection, specially designed narratives, and lack customization. To address this, we propose an interactive system based on user intent. Our system uses a Vision Language Model (VLM) to enable machines to understand video stories, combining Retrieval-Augmented Generation (RAG) and a Multi-Agent System (MAS) to create evolving characters and scene experiences. It includes three stages: 1) Video story processing, utilizing VLM and prior knowledge to simulate human understanding of stories across three modalities. 2) Multi-space chat, creating growth-oriented characters through MAS interactions based on user queries and story stages. 3) Scene customization, expanding and visualizing various story scenes mentioned in dialogue. Applied to the Harry Potter series, our study shows the system effectively portrays emergent character social behavior and growth, enhancing the interactive experience in the video story world.
PLUTUS: A Well Pre-trained Large Unified Transformer can Unveil Financial Time Series Regularities
Aug 20, 2024
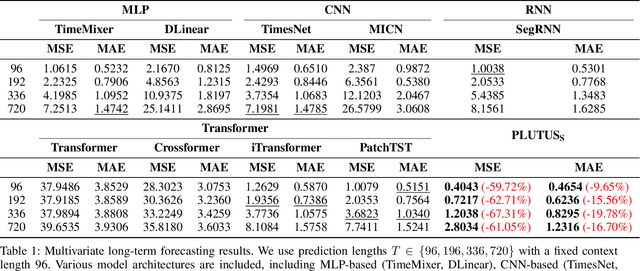
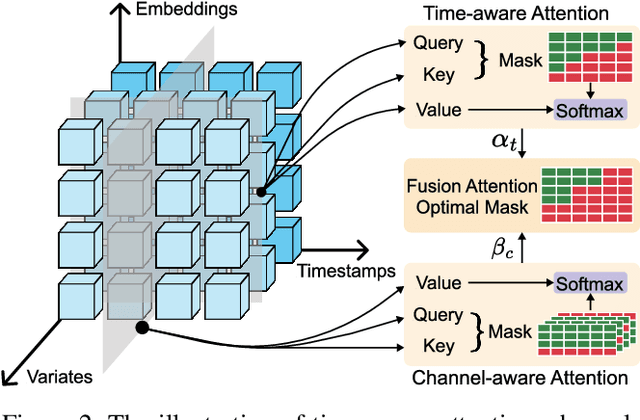

Financial time series modeling is crucial for understanding and predicting market behaviors but faces challenges such as non-linearity, non-stationarity, and high noise levels. Traditional models struggle to capture complex patterns due to these issues, compounded by limitations in computational resources and model capacity. Inspired by the success of large language models in NLP, we introduce $\textbf{PLUTUS}$, a $\textbf{P}$re-trained $\textbf{L}$arge $\textbf{U}$nified $\textbf{T}$ransformer-based model that $\textbf{U}$nveils regularities in financial time $\textbf{S}$eries. PLUTUS uses an invertible embedding module with contrastive learning and autoencoder techniques to create an approximate one-to-one mapping between raw data and patch embeddings. TimeFormer, an attention based architecture, forms the core of PLUTUS, effectively modeling high-noise time series. We incorporate a novel attention mechanisms to capture features across both variable and temporal dimensions. PLUTUS is pre-trained on an unprecedented dataset of 100 billion observations, designed to thrive in noisy financial environments. To our knowledge, PLUTUS is the first open-source, large-scale, pre-trained financial time series model with over one billion parameters. It achieves state-of-the-art performance in various tasks, demonstrating strong transferability and establishing a robust foundational model for finance. Our research provides technical guidance for pre-training financial time series data, setting a new standard in the field.
Generative AI for Visualization: State of the Art and Future Directions
Apr 28, 2024



Generative AI (GenAI) has witnessed remarkable progress in recent years and demonstrated impressive performance in various generation tasks in different domains such as computer vision and computational design. Many researchers have attempted to integrate GenAI into visualization framework, leveraging the superior generative capacity for different operations. Concurrently, recent major breakthroughs in GenAI like diffusion model and large language model have also drastically increase the potential of GenAI4VIS. From a technical perspective, this paper looks back on previous visualization studies leveraging GenAI and discusses the challenges and opportunities for future research. Specifically, we cover the applications of different types of GenAI methods including sequence, tabular, spatial and graph generation techniques for different tasks of visualization which we summarize into four major stages: data enhancement, visual mapping generation, stylization and interaction. For each specific visualization sub-task, we illustrate the typical data and concrete GenAI algorithms, aiming to provide in-depth understanding of the state-of-the-art GenAI4VIS techniques and their limitations. Furthermore, based on the survey, we discuss three major aspects of challenges and research opportunities including evaluation, dataset, and the gap between end-to-end GenAI and generative algorithms. By summarizing different generation algorithms, their current applications and limitations, this paper endeavors to provide useful insights for future GenAI4VIS research.
TimeTuner: Diagnosing Time Representations for Time-Series Forecasting with Counterfactual Explanations
Jul 27, 2023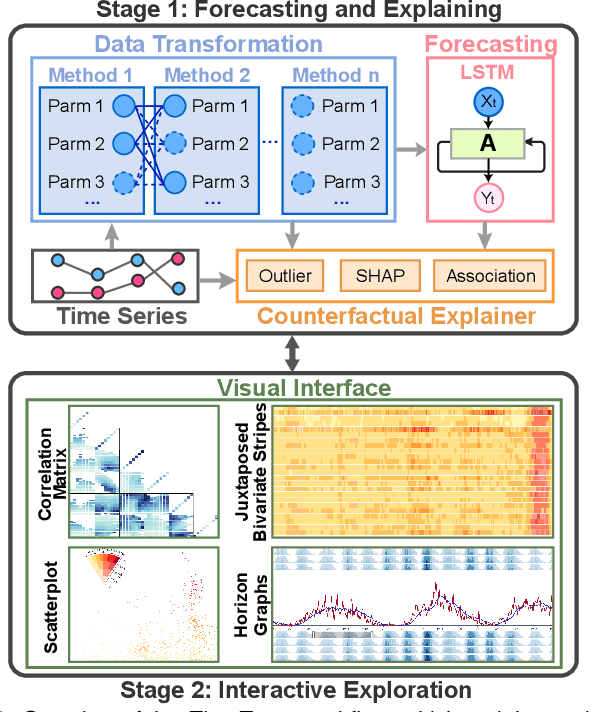
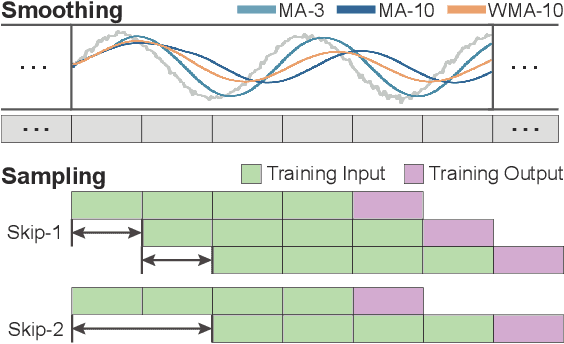
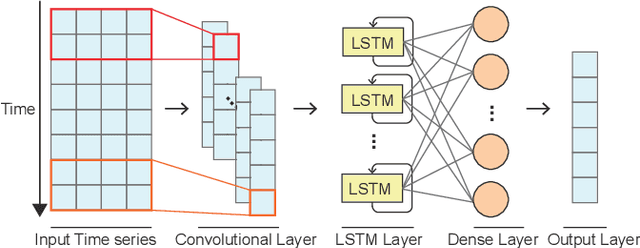
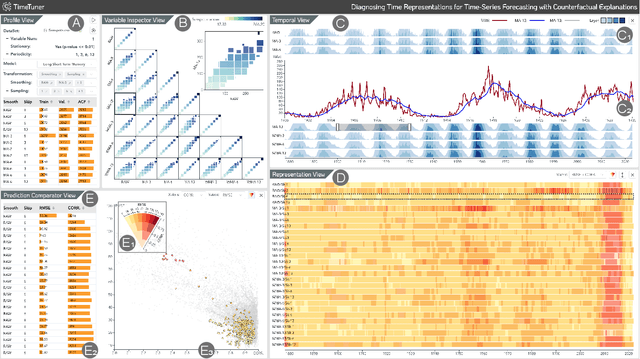
Deep learning (DL) approaches are being increasingly used for time-series forecasting, with many efforts devoted to designing complex DL models. Recent studies have shown that the DL success is often attributed to effective data representations, fostering the fields of feature engineering and representation learning. However, automated approaches for feature learning are typically limited with respect to incorporating prior knowledge, identifying interactions among variables, and choosing evaluation metrics to ensure that the models are reliable. To improve on these limitations, this paper contributes a novel visual analytics framework, namely TimeTuner, designed to help analysts understand how model behaviors are associated with localized correlations, stationarity, and granularity of time-series representations. The system mainly consists of the following two-stage technique: We first leverage counterfactual explanations to connect the relationships among time-series representations, multivariate features and model predictions. Next, we design multiple coordinated views including a partition-based correlation matrix and juxtaposed bivariate stripes, and provide a set of interactions that allow users to step into the transformation selection process, navigate through the feature space, and reason the model performance. We instantiate TimeTuner with two transformation methods of smoothing and sampling, and demonstrate its applicability on real-world time-series forecasting of univariate sunspots and multivariate air pollutants. Feedback from domain experts indicates that our system can help characterize time-series representations and guide the feature engineering processes.