 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoChartQA: A Benchmark for Multimodal Question Answering on Infographic Charts
May 25, 2025Understanding infographic charts with design-driven visual elements (e.g., pictograms, icons) requires both visual recognition and reasoning, posing challenges for multimodal large language models (MLLMs). However, existing visual-question answering benchmarks fall short in evaluating these capabilities of MLLMs due to the lack of paired plain charts and visual-element-based questions. To bridge this gap, we introduce InfoChartQA, a benchmark for evaluating MLLMs on infographic chart understanding. It includes 5,642 pairs of infographic and plain charts, each sharing the same underlying data but differing in visual presentations. We further design visual-element-based questions to capture their unique visual designs and communicative intent. Evaluation of 20 MLLMs reveals a substantial performance decline on infographic charts, particularly for visual-element-based questions related to metaphors. The paired infographic and plain charts enable fine-grained error analysis and ablation studies, which highlight new opportunities for advancing MLLMs in infographic chart understanding. We release InfoChartQA at https://github.com/CoolDawnAnt/InfoChartQA.
AKRMap: Adaptive Kernel Regression for Trustworthy Visualization of Cross-Modal Embeddings
May 20, 2025Cross-modal embeddings form the foundation for multi-modal models. However, visualization methods for interpreting cross-modal embeddings have been primarily confined to traditional dimensionality reduction (DR) techniques like PCA and t-SNE. These DR methods primarily focus on feature distributions within a single modality, whilst failing to incorporate metrics (e.g., CLIPScore) across multiple modalities.This paper introduces AKRMap, a new DR technique designed to visualize cross-modal embeddings metric with enhanced accuracy by learning kernel regression of the metric landscape in the projection space. Specifically, AKRMap constructs a supervised projection network guided by a post-projection kernel regression loss, and employs adaptive generalized kernels that can be jointly optimized with the projection. This approach enables AKRMap to efficiently generate visualizations that capture complex metric distributions, while also supporting interactive features such as zoom and overlay for deeper exploration. Quantitative experiments demonstrate that AKRMap outperforms existing DR methods in generating more accurate and trustworthy visualizations. We further showcase the effectiveness of AKRMap in visualizing and comparing cross-modal embeddings for text-to-image models. Code and demo are available at https://github.com/yilinye/AKRMap.
SketchFlex: Facilitating Spatial-Semantic Coherence in Text-to-Image Generation with Region-Based Sketches
Feb 11, 2025Text-to-image models can generate visually appealing images from text descriptions. Efforts have been devoted to improving model controls with prompt tuning and spatial conditioning. However, our formative study highlights the challenges for non-expert users in crafting appropriate prompts and specifying fine-grained spatial conditions (e.g., depth or canny references) to generate semantically cohesive images, especially when multiple objects are involved. In response, we introduce SketchFlex, an interactive system designed to improve the flexibility of spatially conditioned image generation using rough region sketches. The system automatically infers user prompts with rational descriptions within a semantic space enriched by crowd-sourced object attributes and relationships. Additionally, SketchFlex refines users' rough sketches into canny-based shape anchors, ensuring the generation quality and alignment of user intentions. Experimental results demonstrate that SketchFlex achieves more cohesive image generations than end-to-end models, meanwhile significantly reducing cognitive load and better matching user intentions compared to region-based generation baseline.
Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning
Jul 29, 2024



Emerging multimodal large language models (MLLMs) exhibit great potential for chart question answering (CQA). Recent efforts primarily focus on scaling up training datasets (i.e., charts, data tables, and question-answer (QA) pairs) through data collection and synthesis. However, our empirical study on existing MLLMs and CQA datasets reveals notable gaps. First, current data collection and synthesis focus on data volume and lack consideration of fine-grained visual encodings and QA tasks, resulting in unbalanced data distribution divergent from practical CQA scenarios. Second, existing work follows the training recipe of the base MLLMs initially designed for natural images, under-exploring the adaptation to unique chart characteristics, such as rich text elements. To fill the gap, we propose a visualization-referenced instruction tuning approach to guide the training dataset enhancement and model development. Specifically, we propose a novel data engine to effectively filter diverse and high-quality data from existing datasets and subsequently refine and augment the data using LLM-based generation techniques to better align with practical QA tasks and visual encodings. Then, to facilitate the adaptation to chart characteristics, we utilize the enriched data to train an MLLM by unfreezing the vision encoder and incorporating a mixture-of-resolution adaptation strategy for enhanced fine-grained recognition. Experimental results validate the effectiveness of our approach. Even with fewer training examples, our model consistently outperforms state-of-the-art CQA models on established benchmarks. We also contribute a dataset split as a benchmark for future research. Source codes and datasets of this paper are available at https://github.com/zengxingchen/ChartQA-MLLM.
ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map
Jul 17, 2024Multi-modal embeddings form the foundation for vision-language models, such as CLIP embeddings, the most widely used text-image embeddings. However, these embeddings are vulnerable to subtle misalignment of cross-modal features, resulting in decreased model performance and diminished generalization. To address this problem, we design ModalChorus, an interactive system for visual probing and alignment of multi-modal embeddings. ModalChorus primarily offers a two-stage process: 1) embedding probing with Modal Fusion Map (MFM), a novel parametric dimensionality reduction method that integrates both metric and nonmetric objectives to enhance modality fusion; and 2) embedding alignment that allows users to interactively articulate intentions for both point-set and set-set alignments. Quantitative and qualitative comparisons for CLIP embeddings with existing dimensionality reduction (e.g., t-SNE and MDS) and data fusion (e.g., data context map) methods demonstrate the advantages of MFM in showcasing cross-modal features over common vision-language datasets. Case studies reveal that ModalChorus can facilitate intuitive discovery of misalignment and efficient re-alignment in scenarios ranging from zero-shot classification to cross-modal retrieval and generation.
Generative AI for Visualization: State of the Art and Future Directions
Apr 28, 2024



Generative AI (GenAI) has witnessed remarkable progress in recent years and demonstrated impressive performance in various generation tasks in different domains such as computer vision and computational design. Many researchers have attempted to integrate GenAI into visualization framework, leveraging the superior generative capacity for different operations. Concurrently, recent major breakthroughs in GenAI like diffusion model and large language model have also drastically increase the potential of GenAI4VIS. From a technical perspective, this paper looks back on previous visualization studies leveraging GenAI and discusses the challenges and opportunities for future research. Specifically, we cover the applications of different types of GenAI methods including sequence, tabular, spatial and graph generation techniques for different tasks of visualization which we summarize into four major stages: data enhancement, visual mapping generation, stylization and interaction. For each specific visualization sub-task, we illustrate the typical data and concrete GenAI algorithms, aiming to provide in-depth understanding of the state-of-the-art GenAI4VIS techniques and their limitations. Furthermore, based on the survey, we discuss three major aspects of challenges and research opportunities including evaluation, dataset, and the gap between end-to-end GenAI and generative algorithms. By summarizing different generation algorithms, their current applications and limitations, this paper endeavors to provide useful insights for future GenAI4VIS research.
The Contemporary Art of Image Search: Iterative User Intent Expansion via Vision-Language Model
Dec 05, 2023



Image search is an essential and user-friendly method to explore vast galleries of digital images. However, existing image search methods heavily rely on proximity measurements like tag matching or image similarity, requiring precise user inputs for satisfactory results. To meet the growing demand for a contemporary image search engine that enables accurate comprehension of users' search intentions, we introduce an innovative user intent expansion framework. Our framework leverages visual-language models to parse and compose multi-modal user inputs to provide more accurate and satisfying results. It comprises two-stage processes: 1) a parsing stage that incorporates a language parsing module with large language models to enhance the comprehension of textual inputs, along with a visual parsing module that integrates an interactive segmentation module to swiftly identify detailed visual elements within images; and 2) a logic composition stage that combines multiple user search intents into a unified logic expression for more sophisticated operations in complex searching scenarios. Moreover, the intent expansion framework enables users to perform flexible contextualized interactions with the search results to further specify or adjust their detailed search intents iteratively. We implemented the framework into an image search system for NFT (non-fungible token) search and conducted a user study to evaluate its usability and novel properties. The results indicate that the proposed framework significantly improves users' image search experience. Particularly the parsing and contextualized interactions prove useful in allowing users to express their search intents more accurately and engage in a more enjoyable iterative search experience.
TimeTuner: Diagnosing Time Representations for Time-Series Forecasting with Counterfactual Explanations
Jul 27, 2023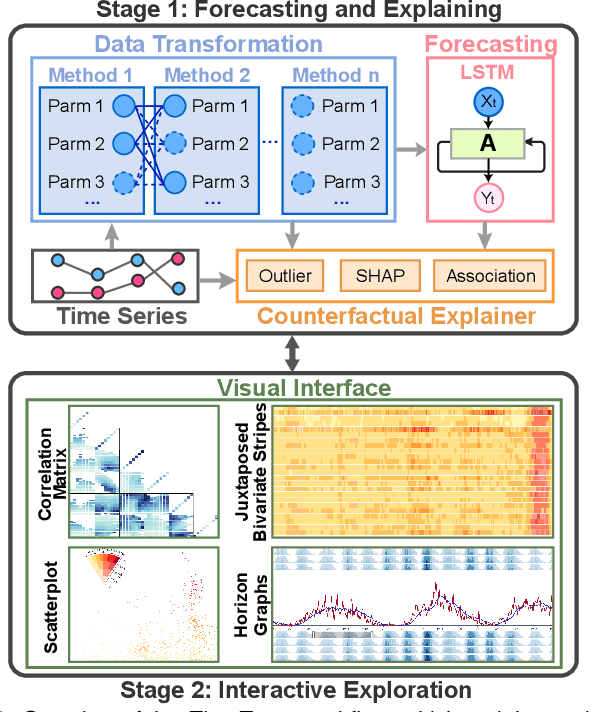
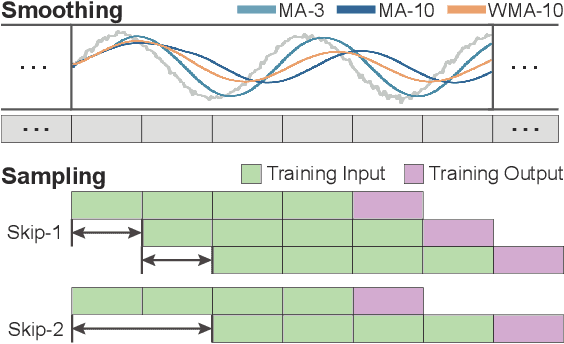
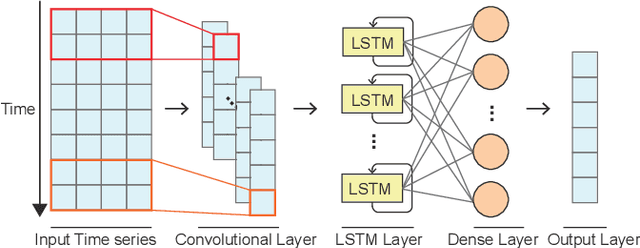
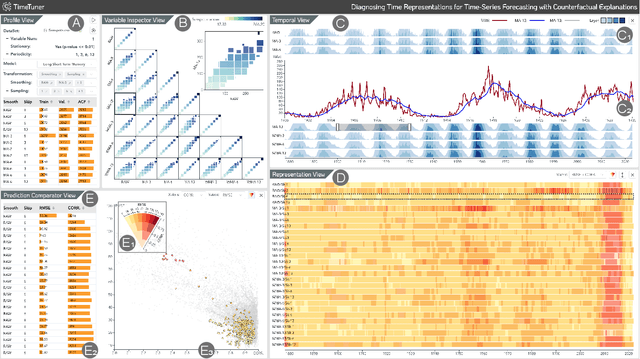
Deep learning (DL) approaches are being increasingly used for time-series forecasting, with many efforts devoted to designing complex DL models. Recent studies have shown that the DL success is often attributed to effective data representations, fostering the fields of feature engineering and representation learning. However, automated approaches for feature learning are typically limited with respect to incorporating prior knowledge, identifying interactions among variables, and choosing evaluation metrics to ensure that the models are reliable. To improve on these limitations, this paper contributes a novel visual analytics framework, namely TimeTuner, designed to help analysts understand how model behaviors are associated with localized correlations, stationarity, and granularity of time-series representations. The system mainly consists of the following two-stage technique: We first leverage counterfactual explanations to connect the relationships among time-series representations, multivariate features and model predictions. Next, we design multiple coordinated views including a partition-based correlation matrix and juxtaposed bivariate stripes, and provide a set of interactions that allow users to step into the transformation selection process, navigate through the feature space, and reason the model performance. We instantiate TimeTuner with two transformation methods of smoothing and sampling, and demonstrate its applicability on real-world time-series forecasting of univariate sunspots and multivariate air pollutants. Feedback from domain experts indicates that our system can help characterize time-series representations and guide the feature engineering processes.
Let the Chart Spark: Embedding Semantic Context into Chart with Text-to-Image Generative Model
Apr 28, 2023



Pictorial visualization seamlessly integrates data and semantic context into visual representation, conveying complex information in a manner that is both engaging and informative. Extensive studies have been devoted to developing authoring tools to simplify the creation of pictorial visualizations. However, mainstream works mostly follow a retrieving-and-editing pipeline that heavily relies on retrieved visual elements from a dedicated corpus, which often compromise the data integrity. Text-guided generation methods are emerging, but may have limited applicability due to its predefined recognized entities. In this work, we propose ChartSpark, a novel system that embeds semantic context into chart based on text-to-image generative model. ChartSpark generates pictorial visualizations conditioned on both semantic context conveyed in textual inputs and data information embedded in plain charts. The method is generic for both foreground and background pictorial generation, satisfying the design practices identified from an empirical research into existing pictorial visualizations. We further develop an interactive visual interface that integrates a text analyzer, editing module, and evaluation module to enable users to generate, modify, and assess pictorial visualizations. We experimentally demonstrate the usability of our tool, and conclude with a discussion of the potential of using text-to-image generative model combined with interactive interface for visualization design.
Everyone Can Be Picasso? A Computational Framework into the Myth of Human versus AI Painting
Apr 17, 2023



The recent advances of AI technology, particularly in AI-Generated Content (AIGC), have enabled everyone to easily generate beautiful paintings with simple text description. With the stunning quality of AI paintings, it is widely questioned whether there still exists difference between human and AI paintings and whether human artists will be replaced by AI. To answer these questions, we develop a computational framework combining neural latent space and aesthetics features with visual analytics to investigate the difference between human and AI paintings. First, with categorical comparison of human and AI painting collections, we find that AI artworks show distributional difference from human artworks in both latent space and some aesthetic features like strokes and sharpness, while in other aesthetic features like color and composition there is less difference. Second, with individual artist analysis of Picasso, we show human artists' strength in evolving new styles compared to AI. Our findings provide concrete evidence for the existing discrepancies between human and AI paintings and further suggest improvements of AI art with more consideration of aesthetics and human artists' involvement.