 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalTAD: Injecting Causal Knowledge into Large Language Models for Tabular Anomaly Detection
Feb 08, 2026Detecting anomalies in tabular data is critical for many real-world applications, such as credit card fraud detection. With the rapid advancements in large language models (LLMs), state-of-the-art performance in tabular anomaly detection has been achieved by converting tabular data into text and fine-tuning LLMs. However, these methods randomly order columns during conversion, without considering the causal relationships between them, which is crucial for accurately detecting anomalies. In this paper, we present CausalTaD, a method that injects causal knowledge into LLMs for tabular anomaly detection. We first identify the causal relationships between columns and reorder them to align with these causal relationships. This reordering can be modeled as a linear ordering problem. Since each column contributes differently to the causal relationships, we further propose a reweighting strategy to assign different weights to different columns to enhance this effect. Experiments across more than 30 datasets demonstrate that our method consistently outperforms the current state-of-the-art methods. The code for CausalTAD is available at https://github.com/350234/CausalTAD.
Invisible Clean-Label Backdoor Attacks for Generative Data Augmentation
Feb 03, 2026With the rapid advancement of image generative models, generative data augmentation has become an effective way to enrich training images, especially when only small-scale datasets are available. At the same time, in practical applications, generative data augmentation can be vulnerable to clean-label backdoor attacks, which aim to bypass human inspection. However, based on theoretical analysis and preliminary experiments, we observe that directly applying existing pixel-level clean-label backdoor attack methods (e.g., COMBAT) to generated images results in low attack success rates. This motivates us to move beyond pixel-level triggers and focus instead on the latent feature level. To this end, we propose InvLBA, an invisible clean-label backdoor attack method for generative data augmentation by latent perturbation. We theoretically prove that the generalization of the clean accuracy and attack success rates of InvLBA can be guaranteed. Experiments on multiple datasets show that our method improves the attack success rate by 46.43% on average, with almost no reduction in clean accuracy and high robustness against SOTA defense methods.
Enhancing Small-Scale Dataset Expansion with Triplet-Connection-based Sample Re-Weighting
Aug 11, 2025The performance of computer vision models in certain real-world applications, such as medical diagnosis, is often limited by the scarcity of available images. Expanding datasets using pre-trained generative models is an effective solution. However, due to the uncontrollable generation process and the ambiguity of natural language, noisy images may be generated. Re-weighting is an effective way to address this issue by assigning low weights to such noisy images. We first theoretically analyze three types of supervision for the generated images. Based on the theoretical analysis, we develop TriReWeight, a triplet-connection-based sample re-weighting method to enhance generative data augmentation. Theoretically, TriReWeight can be integrated with any generative data augmentation methods and never downgrade their performance. Moreover, its generalization approaches the optimal in the order $O(\sqrt{d\ln (n)/n})$. Our experiments validate the correctness of the theoretical analysis and demonstrate that our method outperforms the existing SOTA methods by $7.9\%$ on average over six natural image datasets and by $3.4\%$ on average over three medical datasets. We also experimentally validate that our method can enhance the performance of different generative data augmentation methods.
Interactive Hybrid Rice Breeding with Parametric Dual Projection
Jul 16, 2025



Hybrid rice breeding crossbreeds different rice lines and cultivates the resulting hybrids in fields to select those with desirable agronomic traits, such as higher yields. Recently, genomic selection has emerged as an efficient way for hybrid rice breeding. It predicts the traits of hybrids based on their genes, which helps exclude many undesired hybrids, largely reducing the workload of field cultivation. However, due to the limited accuracy of genomic prediction models, breeders still need to combine their experience with the models to identify regulatory genes that control traits and select hybrids, which remains a time-consuming process. To ease this process, in this paper, we proposed a visual analysis method to facilitate interactive hybrid rice breeding. Regulatory gene identification and hybrid selection naturally ensemble a dual-analysis task. Therefore, we developed a parametric dual projection method with theoretical guarantees to facilitate interactive dual analysis. Based on this dual projection method, we further developed a gene visualization and a hybrid visualization to verify the identified regulatory genes and hybrids. The effectiveness of our method is demonstrated through the quantitative evaluation of the parametric dual projection method, identified regulatory genes and desired hybrids in the case study, and positive feedback from breeders.
InfoChartQA: A Benchmark for Multimodal Question Answering on Infographic Charts
May 25, 2025Understanding infographic charts with design-driven visual elements (e.g., pictograms, icons) requires both visual recognition and reasoning, posing challenges for multimodal large language models (MLLMs). However, existing visual-question answering benchmarks fall short in evaluating these capabilities of MLLMs due to the lack of paired plain charts and visual-element-based questions. To bridge this gap, we introduce InfoChartQA, a benchmark for evaluating MLLMs on infographic chart understanding. It includes 5,642 pairs of infographic and plain charts, each sharing the same underlying data but differing in visual presentations. We further design visual-element-based questions to capture their unique visual designs and communicative intent. Evaluation of 20 MLLMs reveals a substantial performance decline on infographic charts, particularly for visual-element-based questions related to metaphors. The paired infographic and plain charts enable fine-grained error analysis and ablation studies, which highlight new opportunities for advancing MLLMs in infographic chart understanding. We release InfoChartQA at https://github.com/CoolDawnAnt/InfoChartQA.
Human-Guided Image Generation for Expanding Small-Scale Training Image Datasets
Dec 24, 2024



The performance of computer vision models in certain real-world applications (e.g., rare wildlife observation) is limited by the small number of available images. Expanding datasets using pre-trained generative models is an effective way to address this limitation. However, since the automatic generation process is uncontrollable, the generated images are usually limited in diversity, and some of them are undesired. In this paper, we propose a human-guided image generation method for more controllable dataset expansion. We develop a multi-modal projection method with theoretical guarantees to facilitate the exploration of both the original and generated images. Based on the exploration, users refine the prompts and re-generate images for better performance. Since directly refining the prompts is challenging for novice users, we develop a sample-level prompt refinement method to make it easier. With this method, users only need to provide sample-level feedback (e.g., which samples are undesired) to obtain better prompts. The effectiveness of our method is demonstrated through the quantitative evaluation of the multi-modal projection method, improved model performance in the case study for both classification and object detection tasks, and positive feedback from the experts.
A Scalable Matrix Visualization for Understanding Tree Ensemble Classifiers
Sep 05, 2024



The high performance of tree ensemble classifiers benefits from a large set of rules, which, in turn, makes the models hard to understand. To improve interpretability, existing methods extract a subset of rules for approximation using model reduction techniques. However, by focusing on the reduced rule set, these methods often lose fidelity and ignore anomalous rules that, despite their infrequency, play crucial roles in real-world applications. This paper introduces a scalable visual analysis method to explain tree ensemble classifiers that contain tens of thousands of rules. The key idea is to address the issue of losing fidelity by adaptively organizing the rules as a hierarchy rather than reducing them. To ensure the inclusion of anomalous rules, we develop an anomaly-biased model reduction method to prioritize these rules at each hierarchical level. Synergized with this hierarchical organization of rules, we develop a matrix-based hierarchical visualization to support exploration at different levels of detail. Our quantitative experiments and case studies demonstrate how our method fosters a deeper understanding of both common and anomalous rules, thereby enhancing interpretability without sacrificing comprehensiveness.
A Unified Interactive Model Evaluation for Classification, Object Detection, and Instance Segmentation in Computer Vision
Aug 09, 2023



Existing model evaluation tools mainly focus on evaluating classification models, leaving a gap in evaluating more complex models, such as object detection. In this paper, we develop an open-source visual analysis tool, Uni-Evaluator, to support a unified model evaluation for classification, object detection, and instance segmentation in computer vision. The key idea behind our method is to formulate both discrete and continuous predictions in different tasks as unified probability distributions. Based on these distributions, we develop 1) a matrix-based visualization to provide an overview of model performance; 2) a table visualization to identify the problematic data subsets where the model performs poorly; 3) a grid visualization to display the samples of interest. These visualizations work together to facilitate the model evaluation from a global overview to individual samples. Two case studies demonstrate the effectiveness of Uni-Evaluator in evaluating model performance and making informed improvements.
VideoPro: A Visual Analytics Approach for Interactive Video Programming
Aug 01, 2023


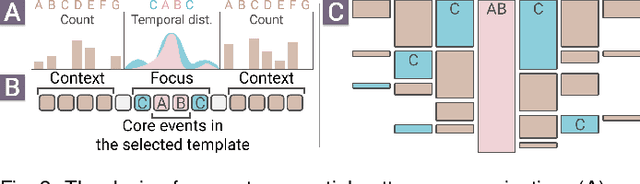
Constructing supervised machine learning models for real-world video analysis require substantial labeled data, which is costly to acquire due to scarce domain expertise and laborious manual inspection. While data programming shows promise in generating labeled data at scale with user-defined labeling functions, the high dimensional and complex temporal information in videos poses additional challenges for effectively composing and evaluating labeling functions. In this paper, we propose VideoPro, a visual analytics approach to support flexible and scalable video data programming for model steering with reduced human effort. We first extract human-understandable events from videos using computer vision techniques and treat them as atomic components of labeling functions. We further propose a two-stage template mining algorithm that characterizes the sequential patterns of these events to serve as labeling function templates for efficient data labeling. The visual interface of VideoPro facilitates multifaceted exploration, examination, and application of the labeling templates, allowing for effective programming of video data at scale. Moreover, users can monitor the impact of programming on model performance and make informed adjustments during the iterative programming process. We demonstrate the efficiency and effectiveness of our approach with two case studies and expert interviews.
OoDAnalyzer: Interactive Analysis of Out-of-Distribution Samples
Feb 08, 2020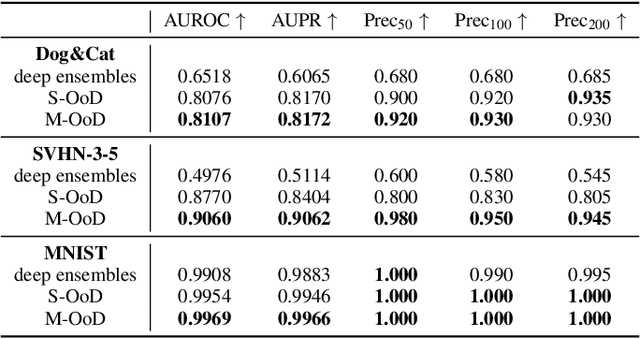

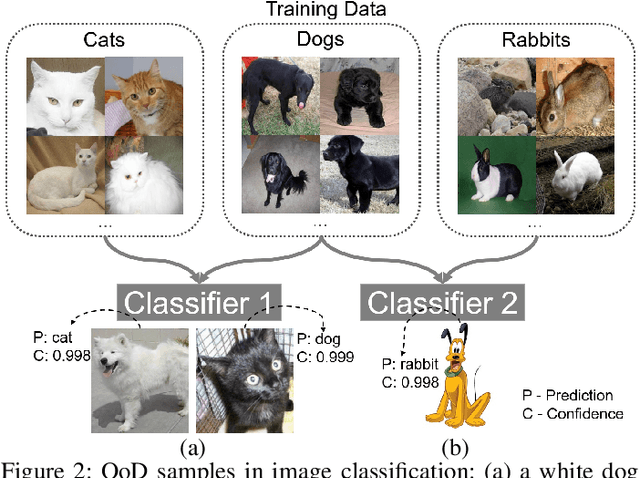
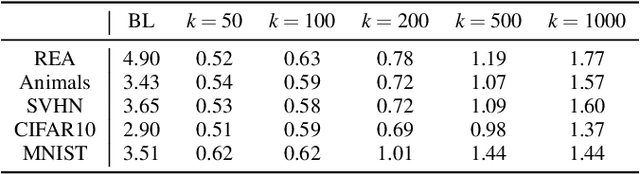
One major cause of performance degradation in predictive models is that the test samples are not well covered by the training data. Such not well-represented samples are called OoD samples. In this paper, we propose OoDAnalyzer, a visual analysis approach for interactively identifying OoD samples and explaining them in context. Our approach integrates an ensemble OoD detection method and a grid-based visualization. The detection method is improved from deep ensembles by combining more features with algorithms in the same family. To better analyze and understand the OoD samples in context, we have developed a novel kNN-based grid layout algorithm motivated by Hall's theorem. The algorithm approximates the optimal layout and has $O(kN^2)$ time complexity, faster than the grid layout algorithm with overall best performance but $O(N^3)$ time complexity. Quantitative evaluation and case studies were performed on several datasets to demonstrate the effectiveness and usefulness of OoDAnalyzer.