 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscreteRTC: Discrete Diffusion Policies are Natural Asynchronous Executors
Apr 27, 2026Unlike chatbots, physical AI must act while the world keeps evolving. Therefore, the inter-chunk pause of synchronous executors are fatal for dynamic tasks regardless of how fast the inference is. Asynchronous execution -- thinking while acting -- is therefore a structural requirement, and real-time chunking (RTC) makes it viable by recasting chunk transitions as inpainting: freezing committed actions and consistently generating the remainder. However, RTC with flow-matching policy is structurally suboptimal: its inpainting comes from inference-time corrections rather than the base policy, yielding little pre-training benefit, specific fine-tuning, heuristic guidance, and extra computation that inflates the latency. In this work, we observe that discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once: they are fine-tuning free since inpainting is their native operation, while early stopping further provides adaptive guidance and reduces inference cost. We propose DiscreteRTC, which replaces external corrections with native unmasking, and show on dynamic simulated benchmarks and real-world dynamic manipulation tasks that it achieves higher success rates than continuous RTC and other baselines. In summary, DiscreteRTC is simpler to implement with 0 lines of code for async inpainting, faster at inference with only 0.7x computation compared with generating actions from scratch, and better at execution with 50% higher success rate in real-world dynamic pick task compared with flow-matching-based RTC. More visualizations are on https://outsider86.github.io/DiscreteRTCSite/.
AgentSPEX: An Agent SPecification and EXecution Language
Apr 14, 2026Language-model agent systems commonly rely on reactive prompting, in which a single instruction guides the model through an open-ended sequence of reasoning and tool-use steps, leaving control flow and intermediate state implicit and making agent behavior potentially difficult to control. Orchestration frameworks such as LangGraph, DSPy, and CrewAI impose greater structure through explicit workflow definitions, but tightly couple workflow logic with Python, making agents difficult to maintain and modify. In this paper, we introduce AgentSPEX, an Agent SPecification and EXecution Language for specifying LLM-agent workflows with explicit control flow and modular structure, along with a customizable agent harness. AgentSPEX supports typed steps, branching and loops, parallel execution, reusable submodules, and explicit state management, and these workflows execute within an agent harness that provides tool access, a sandboxed virtual environment, and support for checkpointing, verification, and logging. Furthermore, we provide a visual editor with synchronized graph and workflow views for authoring and inspection. We include ready-to-use agents for deep research and scientific research, and we evaluate AgentSPEX on 7 benchmarks. Finally, we show through a user study that AgentSPEX provides a more interpretable and accessible workflow-authoring paradigm than a popular existing agent framework.
Mean Flow Policy with Instantaneous Velocity Constraint for One-step Action Generation
Feb 14, 2026Learning expressive and efficient policy functions is a promising direction in reinforcement learning (RL). While flow-based policies have recently proven effective in modeling complex action distributions with a fast deterministic sampling process, they still face a trade-off between expressiveness and computational burden, which is typically controlled by the number of flow steps. In this work, we propose mean velocity policy (MVP), a new generative policy function that models the mean velocity field to achieve the fastest one-step action generation. To ensure its high expressiveness, an instantaneous velocity constraint (IVC) is introduced on the mean velocity field during training. We theoretically prove that this design explicitly serves as a crucial boundary condition, thereby improving learning accuracy and enhancing policy expressiveness. Empirically, our MVP achieves state-of-the-art success rates across several challenging robotic manipulation tasks from Robomimic and OGBench. It also delivers substantial improvements in training and inference speed over existing flow-based policy baselines.
DADP: Domain Adaptive Diffusion Policy
Feb 03, 2026Learning domain adaptive policies that can generalize to unseen transition dynamics, remains a fundamental challenge in learning-based control. Substantial progress has been made through domain representation learning to capture domain-specific information, thus enabling domain-aware decision making. We analyze the process of learning domain representations through dynamical prediction and find that selecting contexts adjacent to the current step causes the learned representations to entangle static domain information with varying dynamical properties. Such mixture can confuse the conditioned policy, thereby constraining zero-shot adaptation. To tackle the challenge, we propose DADP (Domain Adaptive Diffusion Policy), which achieves robust adaptation through unsupervised disentanglement and domain-aware diffusion injection. First, we introduce Lagged Context Dynamical Prediction, a strategy that conditions future state estimation on a historical offset context; by increasing this temporal gap, we unsupervisedly disentangle static domain representations by filtering out transient properties. Second, we integrate the learned domain representations directly into the generative process by biasing the prior distribution and reformulating the diffusion target. Extensive experiments on challenging benchmarks across locomotion and manipulation demonstrate the superior performance, and the generalizability of DADP over prior methods. More visualization results are available on the https://outsider86.github.io/DomainAdaptiveDiffusionPolicy/.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025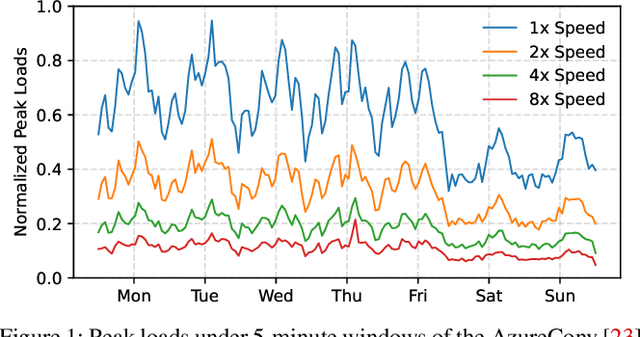
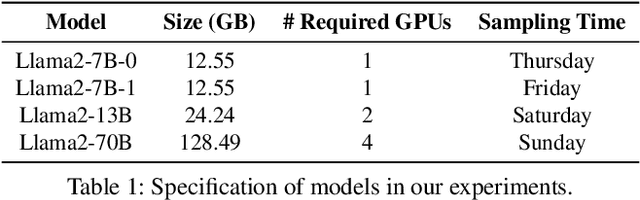
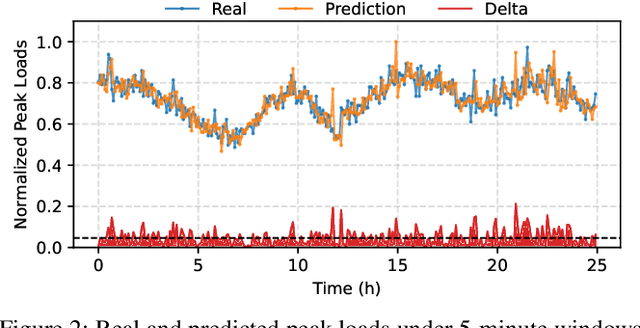
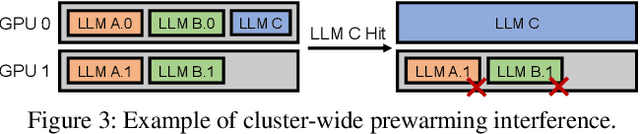
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.
CLO: Efficient LLM Inference System with CPU-Light KVCache Offloading via Algorithm-System Co-Design
Nov 18, 2025The growth of million-token LLMs exposes the scalability limits of inference systems, where the KVCache dominates memory usage and data transfer overhead. Recent offloading systems migrate the KVCache to CPU memory and incorporate top-k attention to reduce the volume of data transferred from the CPU, while further applying system-level optimizations such as on-GPU caching and prefetching to lower transfer overhead. However, they overlook the CPU bottleneck in three aspects: (1) substantial overhead of fine-grained dynamic cache management performed on the CPU side, (2) significant transfer overhead from poor PCIe bandwidth utilization caused by heavy gathering operations at the CPU side, and (3) GPU runtime bubbles introduced by coarse-grained CPU-centric synchronization. To address these challenges, we propose CLO, a CPU-light KVCache offloading system via algorithm-system co-design. CLO features: (1) a coarse-grained head-wise approximate on-GPU caching strategy with negligible cache management cost, (2) seamless combination of data prefetching and on-GPU persistent caching for lower transfer overhead, (3) a zero-copy transfer engine to fully exploit PCIe bandwidth, and a GPU-centric synchronization method to eliminate GPU stalls. Evaluation on two widely-used LLMs demonstrates that CLO achieves comparable accuracy to state-of-the-art systems, while substantially minimizing CPU overhead, fully utilizing PCIe bandwidth, thus improving decoding throughput by 9.3%-66.6%. Our results highlight that algorithm-system co-design is essential for memory-constrained LLM inference on modern GPU platforms. We open source CLO at https://github.com/CommediaJW/CLO.
ReCast: Reliability-aware Codebook Assisted Lightweight Time Series Forecasting
Nov 15, 2025Time series forecasting is crucial for applications in various domains. Conventional methods often rely on global decomposition into trend, seasonal, and residual components, which become ineffective for real-world series dominated by local, complex, and highly dynamic patterns. Moreover, the high model complexity of such approaches limits their applicability in real-time or resource-constrained environments. In this work, we propose a novel \textbf{RE}liability-aware \textbf{C}odebook-\textbf{AS}sisted \textbf{T}ime series forecasting framework (\textbf{ReCast}) that enables lightweight and robust prediction by exploiting recurring local shapes. ReCast encodes local patterns into discrete embeddings through patch-wise quantization using a learnable codebook, thereby compactly capturing stable regular structures. To compensate for residual variations not preserved by quantization, ReCast employs a dual-path architecture comprising a quantization path for efficient modeling of regular structures and a residual path for reconstructing irregular fluctuations. A central contribution of ReCast is a reliability-aware codebook update strategy, which incrementally refines the codebook via weighted corrections. These correction weights are derived by fusing multiple reliability factors from complementary perspectives by a distributionally robust optimization (DRO) scheme, ensuring adaptability to non-stationarity and robustness to distribution shifts. Extensive experiments demonstrate that ReCast outperforms state-of-the-art (SOTA) models in accuracy, efficiency, and adaptability to distribution shifts.
What's on Your Plate? Inferring Chinese Cuisine Intake from Wearable IMUs
Nov 07, 2025Accurate food intake detection is vital for dietary monitoring and chronic disease prevention. Traditional self-report methods are prone to recall bias, while camera-based approaches raise concerns about privacy. Furthermore, existing wearable-based methods primarily focus on a limited number of food types, such as hamburgers and pizza, failing to address the vast diversity of Chinese cuisine. To bridge this gap, we propose CuisineSense, a system that classifies Chinese food types by integrating hand motion cues from a smartwatch with head dynamics from smart glasses. To filter out irrelevant daily activities, we design a two-stage detection pipeline. The first stage identifies eating states by distinguishing characteristic temporal patterns from non-eating behaviors. The second stage then conducts fine-grained food type recognition based on the motions captured during food intake. To evaluate CuisineSense, we construct a dataset comprising 27.5 hours of IMU recordings across 11 food categories and 10 participants. Experiments demonstrate that CuisineSense achieves high accuracy in both eating state detection and food classification, offering a practical solution for unobtrusive, wearable-based dietary monitoring.The system code is publicly available at https://github.com/joeeeeyin/CuisineSense.git.
HD3C: Efficient Medical Data Classification for Embedded Devices
Sep 18, 2025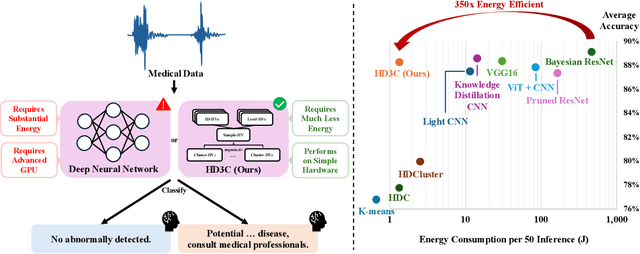
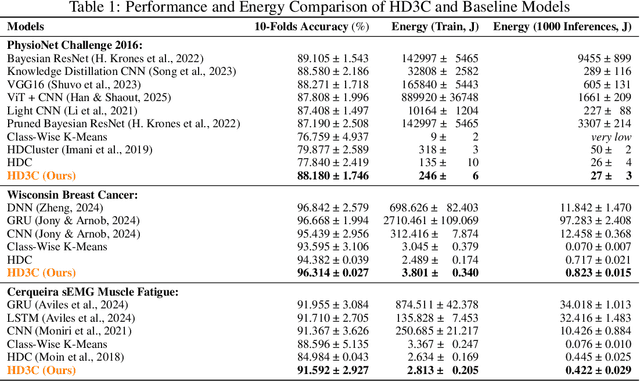
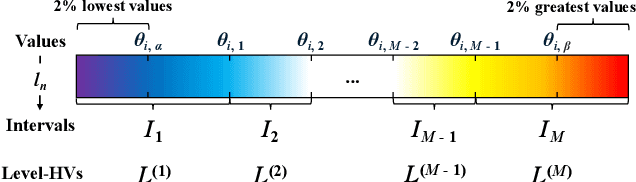
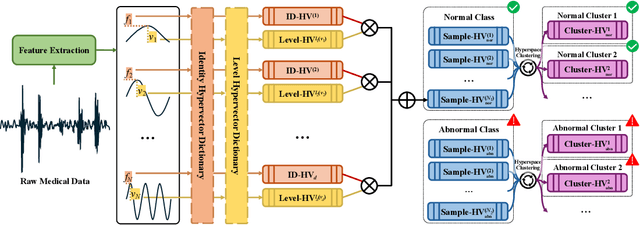
Energy-efficient medical data classification is essential for modern disease screening, particularly in home and field healthcare where embedded devices are prevalent. While deep learning models achieve state-of-the-art accuracy, their substantial energy consumption and reliance on GPUs limit deployment on such platforms. We present Hyperdimensional Computing with Class-Wise Clustering (HD3C), a lightweight classification framework designed for low-power environments. HD3C encodes data into high-dimensional hypervectors, aggregates them into multiple cluster-specific prototypes, and performs classification through similarity search in hyperspace. We evaluate HD3C across three medical classification tasks; on heart sound classification, HD3C is $350\times$ more energy-efficient than Bayesian ResNet with less than 1% accuracy difference. Moreover, HD3C demonstrates exceptional robustness to noise, limited training data, and hardware error, supported by both theoretical analysis and empirical results, highlighting its potential for reliable deployment in real-world settings. Code is available at https://github.com/jianglanwei/HD3C.
Interactive Hybrid Rice Breeding with Parametric Dual Projection
Jul 16, 2025



Hybrid rice breeding crossbreeds different rice lines and cultivates the resulting hybrids in fields to select those with desirable agronomic traits, such as higher yields. Recently, genomic selection has emerged as an efficient way for hybrid rice breeding. It predicts the traits of hybrids based on their genes, which helps exclude many undesired hybrids, largely reducing the workload of field cultivation. However, due to the limited accuracy of genomic prediction models, breeders still need to combine their experience with the models to identify regulatory genes that control traits and select hybrids, which remains a time-consuming process. To ease this process, in this paper, we proposed a visual analysis method to facilitate interactive hybrid rice breeding. Regulatory gene identification and hybrid selection naturally ensemble a dual-analysis task. Therefore, we developed a parametric dual projection method with theoretical guarantees to facilitate interactive dual analysis. Based on this dual projection method, we further developed a gene visualization and a hybrid visualization to verify the identified regulatory genes and hybrids. The effectiveness of our method is demonstrated through the quantitative evaluation of the parametric dual projection method, identified regulatory genes and desired hybrids in the case study, and positive feedback from breeders.