 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDADP: Domain Adaptive Diffusion Policy
Feb 03, 2026Learning domain adaptive policies that can generalize to unseen transition dynamics, remains a fundamental challenge in learning-based control. Substantial progress has been made through domain representation learning to capture domain-specific information, thus enabling domain-aware decision making. We analyze the process of learning domain representations through dynamical prediction and find that selecting contexts adjacent to the current step causes the learned representations to entangle static domain information with varying dynamical properties. Such mixture can confuse the conditioned policy, thereby constraining zero-shot adaptation. To tackle the challenge, we propose DADP (Domain Adaptive Diffusion Policy), which achieves robust adaptation through unsupervised disentanglement and domain-aware diffusion injection. First, we introduce Lagged Context Dynamical Prediction, a strategy that conditions future state estimation on a historical offset context; by increasing this temporal gap, we unsupervisedly disentangle static domain representations by filtering out transient properties. Second, we integrate the learned domain representations directly into the generative process by biasing the prior distribution and reformulating the diffusion target. Extensive experiments on challenging benchmarks across locomotion and manipulation demonstrate the superior performance, and the generalizability of DADP over prior methods. More visualization results are available on the https://outsider86.github.io/DomainAdaptiveDiffusionPolicy/.
Enhanced DACER Algorithm with High Diffusion Efficiency
May 29, 2025Due to their expressive capacity, diffusion models have shown great promise in offline RL and imitation learning. Diffusion Actor-Critic with Entropy Regulator (DACER) extended this capability to online RL by using the reverse diffusion process as a policy approximator, trained end-to-end with policy gradient methods, achieving strong performance. However, this comes at the cost of requiring many diffusion steps, which significantly hampers training efficiency, while directly reducing the steps leads to noticeable performance degradation. Critically, the lack of inference efficiency becomes a significant bottleneck for applying diffusion policies in real-time online RL settings. To improve training and inference efficiency while maintaining or even enhancing performance, we propose a Q-gradient field objective as an auxiliary optimization target to guide the denoising process at each diffusion step. Nonetheless, we observe that the independence of the Q-gradient field from the diffusion time step negatively impacts the performance of the diffusion policy. To address this, we introduce a temporal weighting mechanism that enables the model to efficiently eliminate large-scale noise in the early stages and refine actions in the later stages. Experimental results on MuJoCo benchmarks and several multimodal tasks demonstrate that the DACER2 algorithm achieves state-of-the-art performance in most MuJoCo control tasks with only five diffusion steps, while also exhibiting stronger multimodality compared to DACER.
Chain-of-Thought for Autonomous Driving: A Comprehensive Survey and Future Prospects
May 26, 2025The rapid evolution of large language models in natural language processing has substantially elevated their semantic understanding and logical reasoning capabilities. Such proficiencies have been leveraged in autonomous driving systems, contributing to significant improvements in system performance. Models such as OpenAI o1 and DeepSeek-R1, leverage Chain-of-Thought (CoT) reasoning, an advanced cognitive method that simulates human thinking processes, demonstrating remarkable reasoning capabilities in complex tasks. By structuring complex driving scenarios within a systematic reasoning framework, this approach has emerged as a prominent research focus in autonomous driving, substantially improving the system's ability to handle challenging cases. This paper investigates how CoT methods improve the reasoning abilities of autonomous driving models. Based on a comprehensive literature review, we present a systematic analysis of the motivations, methodologies, challenges, and future research directions of CoT in autonomous driving. Furthermore, we propose the insight of combining CoT with self-learning to facilitate self-evolution in driving systems. To ensure the relevance and timeliness of this study, we have compiled a dynamic repository of literature and open-source projects, diligently updated to incorporate forefront developments. The repository is publicly available at https://github.com/cuiyx1720/Awesome-CoT4AD.
TD-M(PC)$^2$: Improving Temporal Difference MPC Through Policy Constraint
Feb 05, 2025



Model-based reinforcement learning algorithms that combine model-based planning and learned value/policy prior have gained significant recognition for their high data efficiency and superior performance in continuous control. However, we discover that existing methods that rely on standard SAC-style policy iteration for value learning, directly using data generated by the planner, often result in \emph{persistent value overestimation}. Through theoretical analysis and experiments, we argue that this issue is deeply rooted in the structural policy mismatch between the data generation policy that is always bootstrapped by the planner and the learned policy prior. To mitigate such a mismatch in a minimalist way, we propose a policy regularization term reducing out-of-distribution (OOD) queries, thereby improving value learning. Our method involves minimum changes on top of existing frameworks and requires no additional computation. Extensive experiments demonstrate that the proposed approach improves performance over baselines such as TD-MPC2 by large margins, particularly in 61-DoF humanoid tasks. View qualitative results at https://darthutopian.github.io/tdmpc_square/.
Model-Robust and Adaptive-Optimal Transfer Learning for Tackling Concept Shifts in Nonparametric Regression
Jan 18, 2025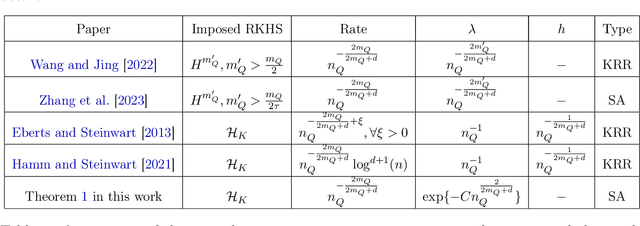
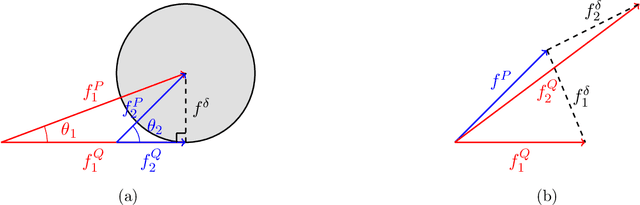
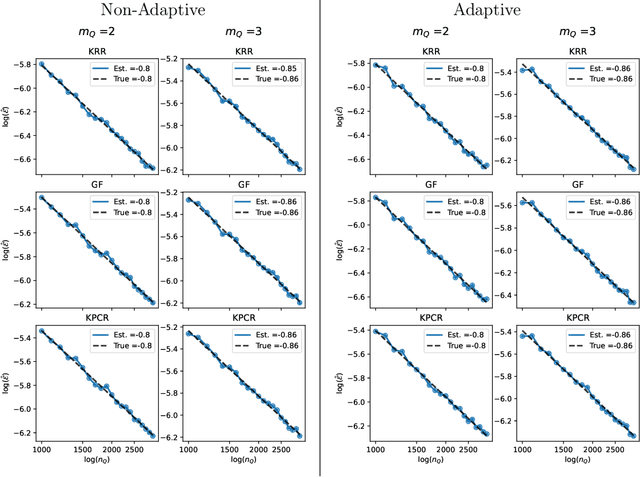
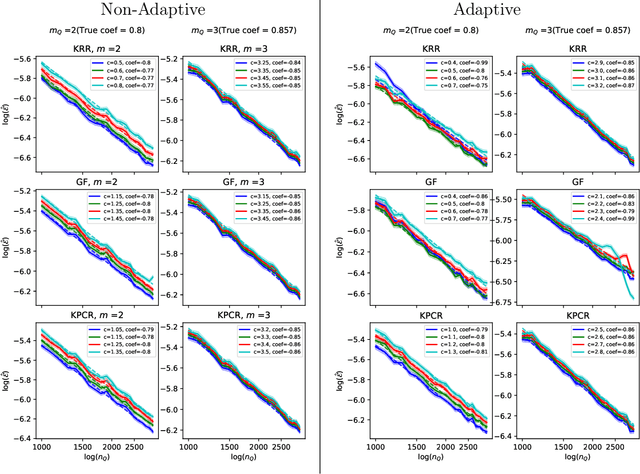
When concept shifts and sample scarcity are present in the target domain of interest, nonparametric regression learners often struggle to generalize effectively. The technique of transfer learning remedies these issues by leveraging data or pre-trained models from similar source domains. While existing generalization analyses of kernel-based transfer learning typically rely on correctly specified models, we present a transfer learning procedure that is robust against model misspecification while adaptively attaining optimality. To facilitate our analysis and avoid the risk of saturation found in classical misspecified results, we establish a novel result in the misspecified single-task learning setting, showing that spectral algorithms with fixed bandwidth Gaussian kernels can attain minimax convergence rates given the true function is in a Sobolev space, which may be of independent interest. Building on this, we derive the adaptive convergence rates of the excess risk for specifying Gaussian kernels in a prevalent class of hypothesis transfer learning algorithms. Our results are minimax optimal up to logarithmic factors and elucidate the key determinants of transfer efficiency.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024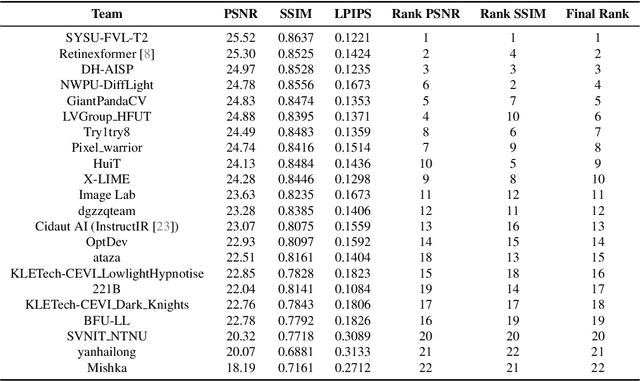

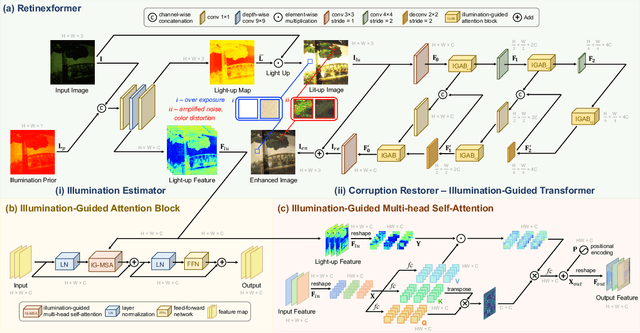

This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
PreGSU-A Generalized Traffic Scene Understanding Model for Autonomous Driving based on Pre-trained Graph Attention Network
Apr 16, 2024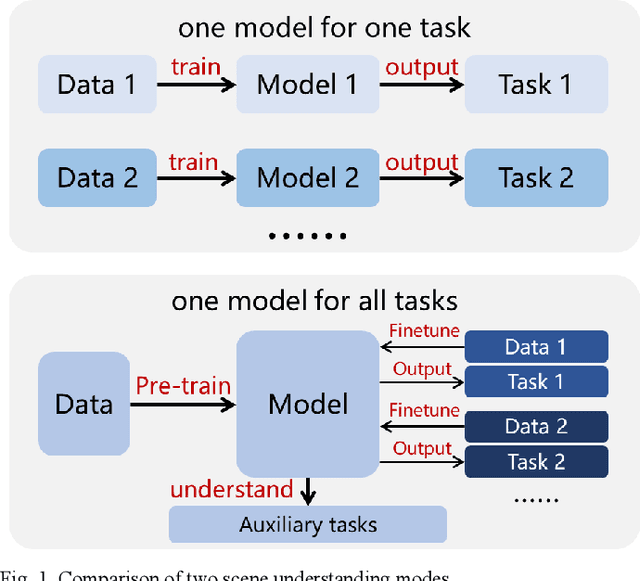
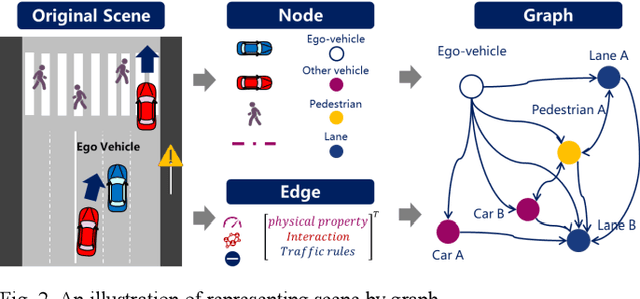
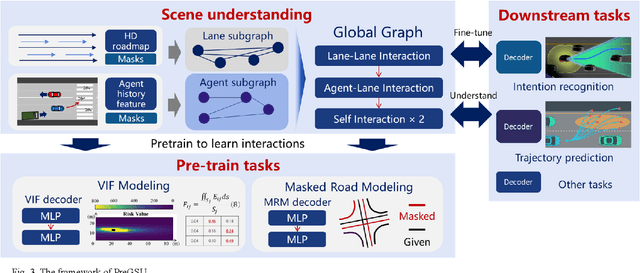
Scene understanding, defined as learning, extraction, and representation of interactions among traffic elements, is one of the critical challenges toward high-level autonomous driving (AD). Current scene understanding methods mainly focus on one concrete single task, such as trajectory prediction and risk level evaluation. Although they perform well on specific metrics, the generalization ability is insufficient to adapt to the real traffic complexity and downstream demand diversity. In this study, we propose PreGSU, a generalized pre-trained scene understanding model based on graph attention network to learn the universal interaction and reasoning of traffic scenes to support various downstream tasks. After the feature engineering and sub-graph module, all elements are embedded as nodes to form a dynamic weighted graph. Then, four graph attention layers are applied to learn the relationships among agents and lanes. In the pre-train phase, the understanding model is trained on two self-supervised tasks: Virtual Interaction Force (VIF) modeling and Masked Road Modeling (MRM). Based on the artificial potential field theory, VIF modeling enables PreGSU to capture the agent-to-agent interactions while MRM extracts agent-to-road connections. In the fine-tuning process, the pre-trained parameters are loaded to derive detailed understanding outputs. We conduct validation experiments on two downstream tasks, i.e., trajectory prediction in urban scenario, and intention recognition in highway scenario, to verify the generalized ability and understanding ability. Results show that compared with the baselines, PreGSU achieves better accuracy on both tasks, indicating the potential to be generalized to various scenes and targets. Ablation study shows the effectiveness of pre-train task design.
Joint Pedestrian Trajectory Prediction through Posterior Sampling
Mar 30, 2024Joint pedestrian trajectory prediction has long grappled with the inherent unpredictability of human behaviors. Recent investigations employing variants of conditional diffusion models in trajectory prediction have exhibited notable success. Nevertheless, the heavy dependence on accurate historical data results in their vulnerability to noise disturbances and data incompleteness. To improve the robustness and reliability, we introduce the Guided Full Trajectory Diffuser (GFTD), a novel diffusion model framework that captures the joint full (historical and future) trajectory distribution. By learning from the full trajectory, GFTD can recover the noisy and missing data, hence improving the robustness. In addition, GFTD can adapt to data imperfections without additional training requirements, leveraging posterior sampling for reliable prediction and controllable generation. Our approach not only simplifies the prediction process but also enhances generalizability in scenarios with noise and incomplete inputs. Through rigorous experimental evaluation, GFTD exhibits superior performance in both trajectory prediction and controllable generation.
Smoothness Adaptive Hypothesis Transfer Learning
Feb 22, 2024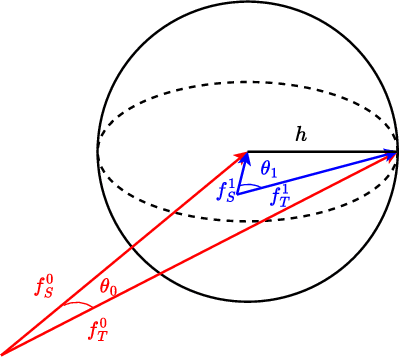
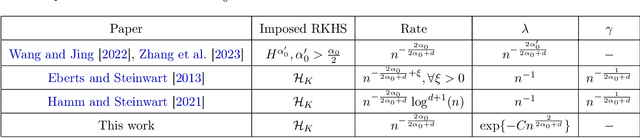
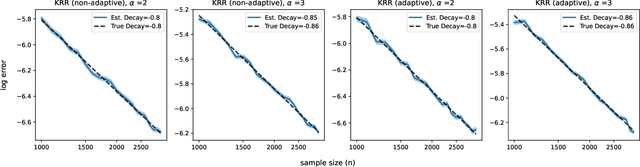
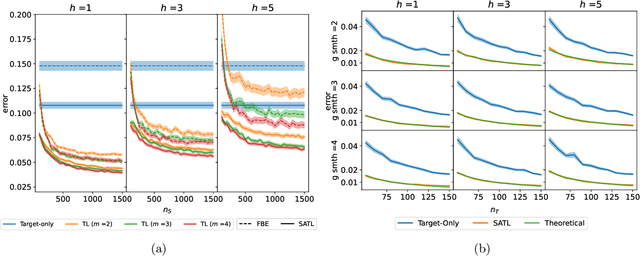
Many existing two-phase kernel-based hypothesis transfer learning algorithms employ the same kernel regularization across phases and rely on the known smoothness of functions to obtain optimality. Therefore, they fail to adapt to the varying and unknown smoothness between the target/source and their offset in practice. In this paper, we address these problems by proposing Smoothness Adaptive Transfer Learning (SATL), a two-phase kernel ridge regression(KRR)-based algorithm. We first prove that employing the misspecified fixed bandwidth Gaussian kernel in target-only KRR learning can achieve minimax optimality and derive an adaptive procedure to the unknown Sobolev smoothness. Leveraging these results, SATL employs Gaussian kernels in both phases so that the estimators can adapt to the unknown smoothness of the target/source and their offset function. We derive the minimax lower bound of the learning problem in excess risk and show that SATL enjoys a matching upper bound up to a logarithmic factor. The minimax convergence rate sheds light on the factors influencing transfer dynamics and demonstrates the superiority of SATL compared to non-transfer learning settings. While our main objective is a theoretical analysis, we also conduct several experiments to confirm our results.
Differentially Private Functional Summaries via the Independent Component Laplace Process
Aug 31, 2023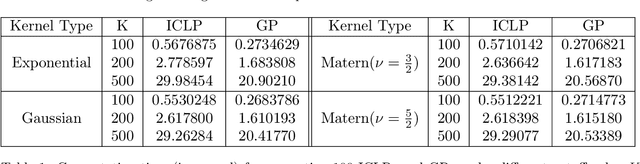
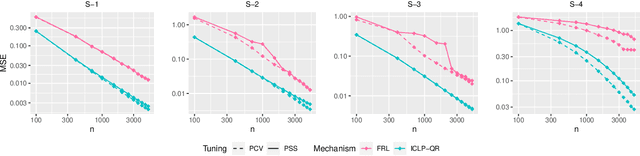
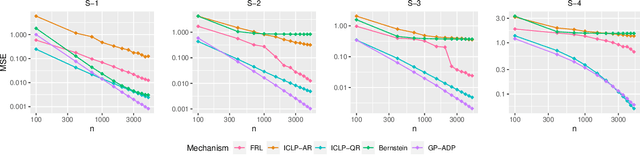
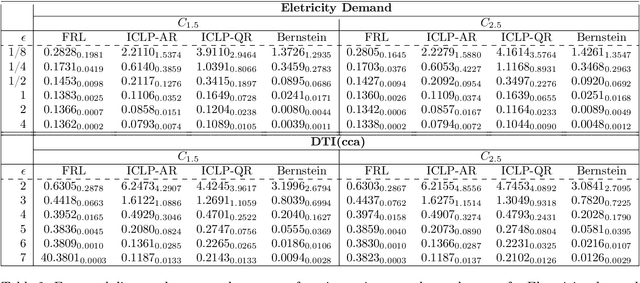
In this work, we propose a new mechanism for releasing differentially private functional summaries called the Independent Component Laplace Process, or ICLP, mechanism. By treating the functional summaries of interest as truly infinite-dimensional objects and perturbing them with the ICLP noise, this new mechanism relaxes assumptions on data trajectories and preserves higher utility compared to classical finite-dimensional subspace embedding approaches in the literature. We establish the feasibility of the proposed mechanism in multiple function spaces. Several statistical estimation problems are considered, and we demonstrate by slightly over-smoothing the summary, the privacy cost will not dominate the statistical error and is asymptotically negligible. Numerical experiments on synthetic and real datasets demonstrate the efficacy of the proposed mechanism.