 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileIE: An Extremely Lightweight and Effective ConvNet for Real-Time Image Enhancement on Mobile Devices
Jul 02, 2025Recent advancements in deep neural networks have driven significant progress in image enhancement (IE). However, deploying deep learning models on resource-constrained platforms, such as mobile devices, remains challenging due to high computation and memory demands. To address these challenges and facilitate real-time IE on mobile, we introduce an extremely lightweight Convolutional Neural Network (CNN) framework with around 4K parameters. Our approach integrates reparameterization with an Incremental Weight Optimization strategy to ensure efficiency. Additionally, we enhance performance with a Feature Self-Transform module and a Hierarchical Dual-Path Attention mechanism, optimized with a Local Variance-Weighted loss. With this efficient framework, we are the first to achieve real-time IE inference at up to 1,100 frames per second (FPS) while delivering competitive image quality, achieving the best trade-off between speed and performance across multiple IE tasks. The code will be available at https://github.com/AVC2-UESTC/MobileIE.git.
Generative Image Compression by Estimating Gradients of the Rate-variable Feature Distribution
May 27, 2025While learned image compression (LIC) focuses on efficient data transmission, generative image compression (GIC) extends this framework by integrating generative modeling to produce photo-realistic reconstructed images. In this paper, we propose a novel diffusion-based generative modeling framework tailored for generative image compression. Unlike prior diffusion-based approaches that indirectly exploit diffusion modeling, we reinterpret the compression process itself as a forward diffusion path governed by stochastic differential equations (SDEs). A reverse neural network is trained to reconstruct images by reversing the compression process directly, without requiring Gaussian noise initialization. This approach achieves smooth rate adjustment and photo-realistic reconstructions with only a minimal number of sampling steps. Extensive experiments on benchmark datasets demonstrate that our method outperforms existing generative image compression approaches across a range of metrics, including perceptual distortion, statistical fidelity, and no-reference quality assessments.
DeepNuParc: A Novel Deep Clustering Framework for Fine-scale Parcellation of Brain Nuclei Using Diffusion MRI Tractography
Mar 10, 2025



Brain nuclei are clusters of anatomically distinct neurons that serve as important hubs for processing and relaying information in various neural circuits. Fine-scale parcellation of the brain nuclei is vital for a comprehensive understanding of its anatomico-functional correlations. Diffusion MRI tractography is an advanced imaging technique that can estimate the brain's white matter structural connectivity to potentially reveal the topography of the nuclei of interest for studying its subdivisions. In this work, we present a deep clustering pipeline, namely DeepNuParc, to perform automated, fine-scale parcellation of brain nuclei using diffusion MRI tractography. First, we incorporate a newly proposed deep learning approach to enable accurate segmentation of the nuclei of interest directly on the dMRI data. Next, we design a novel streamline clustering-based structural connectivity feature for a robust representation of voxels within the nuclei. Finally, we improve the popular joint dimensionality reduction and k-means clustering approach to enable nuclei parcellation at a finer scale. We demonstrate DeepNuParc on two important brain structures, i.e. the amygdala and the thalamus, that are known to have multiple anatomically and functionally distinct nuclei subdivisions. Experimental results show that DeepNuParc enables consistent parcellation of the nuclei into multiple parcels across multiple subjects and achieves good correspondence with the widely used coarse-scale atlases. Our codes are available at https://github.com/HarlandZZC/deep_nuclei_parcellation.
Continuous Patch Stitching for Block-wise Image Compression
Feb 24, 2025

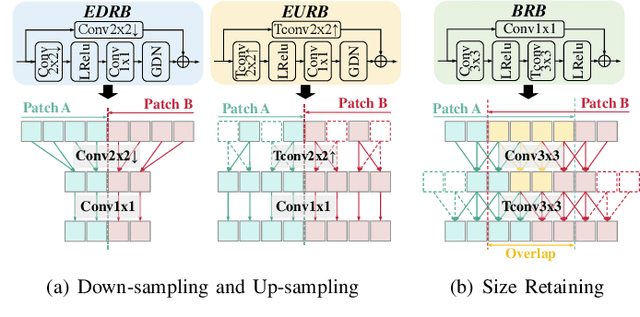

Most recently, learned image compression methods have outpaced traditional hand-crafted standard codecs. However, their inference typically requires to input the whole image at the cost of heavy computing resources, especially for high-resolution image compression; otherwise, the block artefact can exist when compressed by blocks within existing learned image compression methods. To address this issue, we propose a novel continuous patch stitching (CPS) framework for block-wise image compression that is able to achieve seamlessly patch stitching and mathematically eliminate block artefact, thus capable of significantly reducing the required computing resources when compressing images. More specifically, the proposed CPS framework is achieved by padding-free operations throughout, with a newly established parallel overlapping stitching strategy to provide a general upper bound for ensuring the continuity. Upon this, we further propose functional residual blocks with even-sized kernels to achieve down-sampling and up-sampling, together with bottleneck residual blocks retaining feature size to increase network depth. Experimental results demonstrate that our CPS framework achieves the state-of-the-art performance against existing baselines, whilst requiring less than half of computing resources of existing models. Our code shall be released upon acceptance.
Hierarchical Semantic Compression for Consistent Image Semantic Restoration
Feb 24, 2025The emerging semantic compression has been receiving increasing research efforts most recently, capable of achieving high fidelity restoration during compression, even at extremely low bitrates. However, existing semantic compression methods typically combine standard pipelines with either pre-defined or high-dimensional semantics, thus suffering from deficiency in compression. To address this issue, we propose a novel hierarchical semantic compression (HSC) framework that purely operates within intrinsic semantic spaces from generative models, which is able to achieve efficient compression for consistent semantic restoration. More specifically, we first analyse the entropy models for the semantic compression, which motivates us to employ a hierarchical architecture based on a newly developed general inversion encoder. Then, we propose the feature compression network (FCN) and semantic compression network (SCN), such that the middle-level semantic feature and core semantics are hierarchically compressed to restore both accuracy and consistency of image semantics, via an entropy model progressively shared by channel-wise context. Experimental results demonstrate that the proposed HSC framework achieves the state-of-the-art performance on subjective quality and consistency for human vision, together with superior performances on machine vision tasks given compressed bitstreams. This essentially coincides with human visual system in understanding images, thus providing a new framework for future image/video compression paradigms. Our code shall be released upon acceptance.
Triply Laplacian Scale Mixture Modeling for Seismic Data Noise Suppression
Feb 20, 2025Sparsity-based tensor recovery methods have shown great potential in suppressing seismic data noise. These methods exploit tensor sparsity measures capturing the low-dimensional structures inherent in seismic data tensors to remove noise by applying sparsity constraints through soft-thresholding or hard-thresholding operators. However, in these methods, considering that real seismic data are non-stationary and affected by noise, the variances of tensor coefficients are unknown and may be difficult to accurately estimate from the degraded seismic data, leading to undesirable noise suppression performance. In this paper, we propose a novel triply Laplacian scale mixture (TLSM) approach for seismic data noise suppression, which significantly improves the estimation accuracy of both the sparse tensor coefficients and hidden scalar parameters. To make the optimization problem manageable, an alternating direction method of multipliers (ADMM) algorithm is employed to solve the proposed TLSM-based seismic data noise suppression problem. Extensive experimental results on synthetic and field seismic data demonstrate that the proposed TLSM algorithm outperforms many state-of-the-art seismic data noise suppression methods in both quantitative and qualitative evaluations while providing exceptional computational efficiency.
From Dense to Sparse: Event Response for Enhanced Residential Load Forecasting
Jan 08, 2025


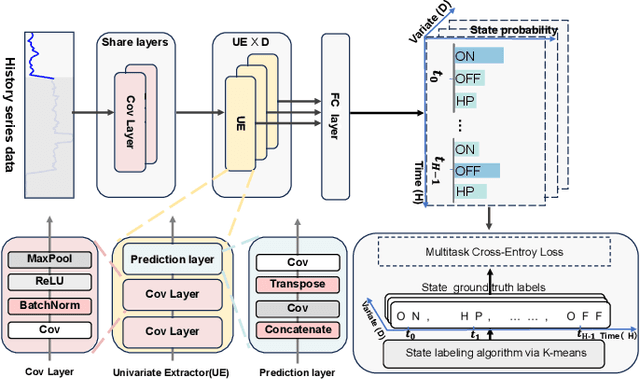
Residential load forecasting (RLF) is crucial for resource scheduling in power systems. Most existing methods utilize all given load records (dense data) to indiscriminately extract the dependencies between historical and future time series. However, there exist important regular patterns residing in the event-related associations among different appliances (sparse knowledge), which have yet been ignored. In this paper, we propose an Event-Response Knowledge Guided approach (ERKG) for RLF by incorporating the estimation of electricity usage events for different appliances, mining event-related sparse knowledge from the load series. With ERKG, the event-response estimation enables portraying the electricity consumption behaviors of residents, revealing regular variations in appliance operational states. To be specific, ERKG consists of knowledge extraction and guidance: i) a forecasting model is designed for the electricity usage events by estimating appliance operational states, aiming to extract the event-related sparse knowledge; ii) a novel knowledge-guided mechanism is established by fusing such state estimates of the appliance events into the RLF model, which can give particular focuses on the patterns of users' electricity consumption behaviors. Notably, ERKG can flexibly serve as a plug-in module to boost the capability of existing forecasting models by leveraging event response. In numerical experiments, extensive comparisons and ablation studies have verified the effectiveness of our ERKG, e.g., over 8% MAE can be reduced on the tested state-of-the-art forecasting models.
Learnable Scaled Gradient Descent for Guaranteed Robust Tensor PCA
Jan 08, 2025



Robust tensor principal component analysis (RTPCA) aims to separate the low-rank and sparse components from multi-dimensional data, making it an essential technique in the signal processing and computer vision fields. Recently emerging tensor singular value decomposition (t-SVD) has gained considerable attention for its ability to better capture the low-rank structure of tensors compared to traditional matrix SVD. However, existing methods often rely on the computationally expensive tensor nuclear norm (TNN), which limits their scalability for real-world tensors. To address this issue, we explore an efficient scaled gradient descent (SGD) approach within the t-SVD framework for the first time, and propose the RTPCA-SGD method. Theoretically, we rigorously establish the recovery guarantees of RTPCA-SGD under mild assumptions, demonstrating that with appropriate parameter selection, it achieves linear convergence to the true low-rank tensor at a constant rate, independent of the condition number. To enhance its practical applicability, we further propose a learnable self-supervised deep unfolding model, which enables effective parameter learning. Numerical experiments on both synthetic and real-world datasets demonstrate the superior performance of the proposed methods while maintaining competitive computational efficiency, especially consuming less time than RTPCA-TNN.
WiFi CSI Based Temporal Activity Detection Via Dual Pyramid Network
Dec 19, 2024We address the challenge of WiFi-based temporal activity detection and propose an efficient Dual Pyramid Network that integrates Temporal Signal Semantic Encoders and Local Sensitive Response Encoders. The Temporal Signal Semantic Encoder splits feature learning into high and low-frequency components, using a novel Signed Mask-Attention mechanism to emphasize important areas and downplay unimportant ones, with the features fused using ContraNorm. The Local Sensitive Response Encoder captures fluctuations without learning. These feature pyramids are then combined using a new cross-attention fusion mechanism. We also introduce a dataset with over 2,114 activity segments across 553 WiFi CSI samples, each lasting around 85 seconds. Extensive experiments show our method outperforms challenging baselines. Code and dataset are available at https://github.com/AVC2-UESTC/WiFiTAD.
Towards Open-Vocabulary Video Semantic Segmentation
Dec 12, 2024



Semantic segmentation in videos has been a focal point of recent research. However, existing models encounter challenges when faced with unfamiliar categories. To address this, we introduce the Open Vocabulary Video Semantic Segmentation (OV-VSS) task, designed to accurately segment every pixel across a wide range of open-vocabulary categories, including those that are novel or previously unexplored. To enhance OV-VSS performance, we propose a robust baseline, OV2VSS, which integrates a spatial-temporal fusion module, allowing the model to utilize temporal relationships across consecutive frames. Additionally, we incorporate a random frame enhancement module, broadening the model's understanding of semantic context throughout the entire video sequence. Our approach also includes video text encoding, which strengthens the model's capability to interpret textual information within the video context. Comprehensive evaluations on benchmark datasets such as VSPW and Cityscapes highlight OV-VSS's zero-shot generalization capabilities, especially in handling novel categories. The results validate OV2VSS's effectiveness, demonstrating improved performance in semantic segmentation tasks across diverse video datasets.