 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Verifiable Multimodal Deep Research: A Multi-Agent Harness for Interleaved Report Generation
May 28, 2026Large Language Models (LLMs) have advanced autonomous agents from deep search, which retrieves concise factual answers, to deep research, which synthesizes scattered evidence into long-form reports. However, verifiable multimodal deep research remains challenging due to open-ended synthesis without deterministic ground truth and the need to interleave textual arguments with visual evidence. We propose \textsc{Ptah}, a multi-agent harness for interleaved report generation. \textsc{Ptah} orchestrates the lifecycle from user query to rendered web report through planning, research, and writing stages, where specialized agents construct visual-aware plans, collect claim-grounded evidence, maintain source-aligned images in a \textit{Visual Working Memory}, and compose reports through declarative multimodal tool use. A verifier agent serves as the harness's acceptance function, enforcing factual grounding, citation fidelity, and cross-modal consistency throughout the workflow. We further introduce \textsc{Ptah}Eval, an evaluation protocol that augments existing benchmarks with image-level and presentation-level assessments. Experiments on deep research benchmarks show that \textsc{Ptah} produces more reliable, visually informative, and usable human-facing multimodal reports than strong baselines.
Beyond Dataset Distillation: Lossless Dataset Concentration via Diffusion-Assisted Distribution Alignment
Mar 30, 2026The high cost and accessibility problem associated with large datasets hinder the development of large-scale visual recognition systems. Dataset Distillation addresses these problems by synthesizing compact surrogate datasets for efficient training, storage, transfer, and privacy preservation. The existing state-of-the-art diffusion-based dataset distillation methods face three issues: lack of theoretical justification, poor efficiency in scaling to high data volumes, and failure in data-free scenarios. To address these issues, we establish a theoretical framework that justifies the use of diffusion models by proving the equivalence between dataset distillation and distribution matching, and reveals an inherent efficiency limit in the dataset distillation paradigm. We then propose a Dataset Concentration (DsCo) framework that uses a diffusion-based Noise-Optimization (NOpt) method to synthesize a small yet representative set of samples, and optionally augments the synthetic data via "Doping", which mixes selected samples from the original dataset with the synthetic samples to overcome the efficiency limit of dataset distillation. DsCo is applicable in both data-accessible and data-free scenarios, achieving SOTA performances for low data volumes, and it extends well to high data volumes, where it nearly reduces the dataset size by half with no performance degradation.
Wukong-Omni: Design, Modeling and Control of a Multi-mode Robot for Air, Land, and Underwater Exploration with All-in-One Propulsion Unit
Mar 03, 2026In flood disaster rescue scenarios, partially submerged buildings prevent aerial robots from accessing lower levels, limiting mission effectiveness. To address this challenge, this paper presents Wukong-Omni, a novel multimode robot capable of operating across land, air, and underwater using a unified propulsion system. The system is enabled by an innovative mechanical design that allows motor reuse and improves thrust generation. Efficiency and peak thrust are enhanced through simulation and tank-based optimization. Experimental results show a 100 percent improvement in propulsion efficiency and a 150 percent increase in maximum thrust compared with direct installation methods. Dynamic models for the three operating domains are developed, and a unified cross-domain control framework is proposed. Comprehensive experiments validate stable locomotion and smooth transition across domains. Outdoor experiments further demonstrate robustness and adaptability in real-world environments.
Arbitrary Ratio Feature Compression via Next Token Prediction
Feb 12, 2026Feature compression is increasingly important for improving the efficiency of downstream tasks, especially in applications involving large-scale or multi-modal data. While existing methods typically rely on dedicated models for achieving specific compression ratios, they are often limited in flexibility and generalization. In particular, retraining is necessary when adapting to a new compression ratio. To address this limitation, we propose a novel and flexible Arbitrary Ratio Feature Compression (ARFC) framework, which supports any compression ratio with a single model, eliminating the need for multiple specialized models. At its core, the Arbitrary Ratio Compressor (ARC) is an auto-regressive model that performs compression via next-token prediction. This allows the compression ratio to be controlled at inference simply by adjusting the number of generated tokens. To enhance the quality of the compressed features, two key modules are introduced. The Mixture of Solutions (MoS) module refines the compressed tokens by utilizing multiple compression results (solutions), reducing uncertainty and improving robustness. The Entity Relation Graph Constraint (ERGC) is integrated into the training process to preserve semantic and structural relationships during compression. Extensive experiments on cross-modal retrieval, image classification, and image retrieval tasks across multiple datasets demonstrate that our method consistently outperforms existing approaches at various compression ratios. Notably, in some cases, it even surpasses the performance of the original, uncompressed features. These results validate the effectiveness and versatility of ARFC for practical, resource-constrained scenarios.
QVLA: Not All Channels Are Equal in Vision-Language-Action Model's Quantization
Feb 03, 2026The advent of Vision-Language-Action (VLA) models represents a significant leap for embodied intelligence, yet their immense computational demands critically hinder deployment on resource-constrained robotic platforms. Intuitively, low-bit quantization is a prevalent and preferred technique for large-scale model compression. However, we find that a systematic analysis of VLA model's quantization is fundamentally lacking. We argue that naively applying uniform-bit quantization from Large Language Models (LLMs) to robotics is flawed, as these methods prioritize passive data fidelity while ignoring how minor action deviations compound into catastrophic task failures. To bridge this gap, we introduce QVLA, the first action-centric quantization framework specifically designed for embodied control. In a sharp departure from the rigid, uniform-bit quantization of LLM-based methods, QVLA introduces a highly granular, channel-wise bit allocation strategy. Its core mechanism is to directly measure the final action-space sensitivity when quantizing each individual channel to various bit-widths. This process yields a precise, per-channel importance metric that guides a global optimization, which elegantly unifies quantization and pruning (0-bit) into a single, cohesive framework. Extensive evaluations on different baselines demonstrate the superiority of our approach. In the LIBERO, the quantization version of OpenVLA-OFT with our method requires only 29.2% of the original model's VRAM while maintaining 98.9% of its original performance and achieving a 1.49x speedup. This translates to a 22.6% performance improvement over the LLM-derived method SmoothQuant. Our work establishes a new, principled foundation for compressing VLA models in robotics, paving the way for deploying powerful, large-scale models on real-world hardware. Code will be released.
The Illusion of Forgetting: Attack Unlearned Diffusion via Initial Latent Variable Optimization
Jan 30, 2026Although unlearning-based defenses claim to purge Not-Safe-For-Work (NSFW) concepts from diffusion models (DMs), we reveals that this "forgetting" is largely an illusion. Unlearning partially disrupts the mapping between linguistic symbols and the underlying knowledge, which remains intact as dormant memories. We find that the distributional discrepancy in the denoising process serves as a measurable indicator of how much of the mapping is retained, also reflecting the strength of unlearning. Inspired by this, we propose IVO (Initial Latent Variable Optimization), a concise and powerful attack framework that reactivates these dormant memories by reconstructing the broken mappings. Through Image Inversion}, Adversarial Optimization and Reused Attack, IVO optimizes initial latent variables to realign the noise distribution of unlearned models with their original unsafe states. Extensive experiments across 8 widely used unlearning techniques demonstrate that IVO achieves superior attack success rates and strong semantic consistency, exposing fundamental flaws in current defenses. The code is available at anonymous.4open.science/r/IVO/. Warning: This paper has unsafe images that may offend some readers.
Burst Image Quality Assessment: A New Benchmark and Unified Framework for Multiple Downstream Tasks
Nov 11, 2025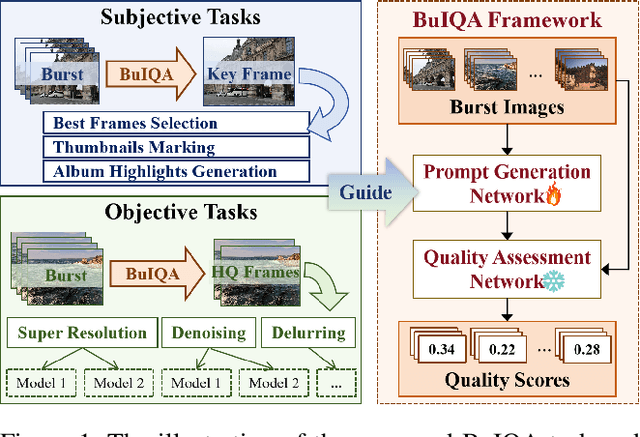
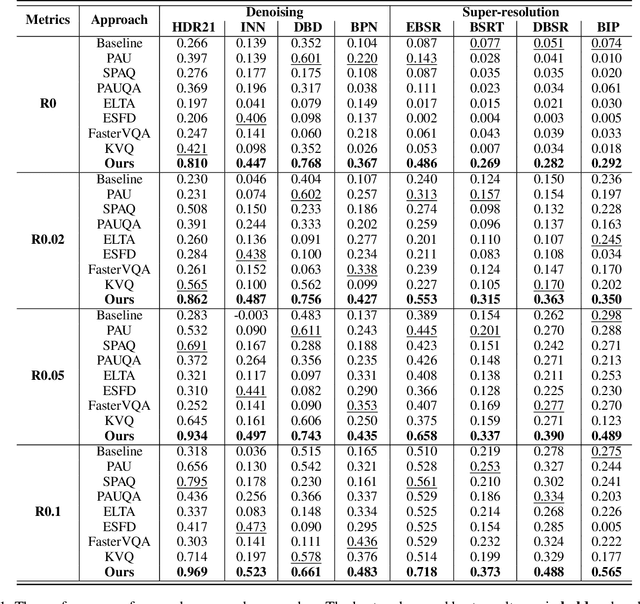

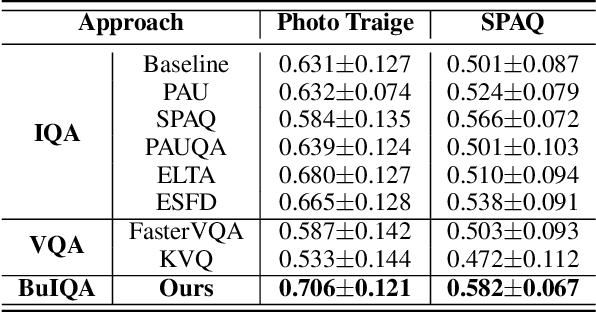
In recent years, the development of burst imaging technology has improved the capture and processing capabilities of visual data, enabling a wide range of applications. However, the redundancy in burst images leads to the increased storage and transmission demands, as well as reduced efficiency of downstream tasks. To address this, we propose a new task of Burst Image Quality Assessment (BuIQA), to evaluate the task-driven quality of each frame within a burst sequence, providing reasonable cues for burst image selection. Specifically, we establish the first benchmark dataset for BuIQA, consisting of $7,346$ burst sequences with $45,827$ images and $191,572$ annotated quality scores for multiple downstream scenarios. Inspired by the data analysis, a unified BuIQA framework is proposed to achieve an efficient adaption for BuIQA under diverse downstream scenarios. Specifically, a task-driven prompt generation network is developed with heterogeneous knowledge distillation, to learn the priors of the downstream task. Then, the task-aware quality assessment network is introduced to assess the burst image quality based on the task prompt. Extensive experiments across 10 downstream scenarios demonstrate the impressive BuIQA performance of the proposed approach, outperforming the state-of-the-art. Furthermore, it can achieve $0.33$ dB PSNR improvement in the downstream tasks of denoising and super-resolution, by applying our approach to select the high-quality burst frames.
Pay Less Attention to Deceptive Artifacts: Robust Detection of Compressed Deepfakes on Online Social Networks
Jun 25, 2025



With the rapid advancement of deep learning, particularly through generative adversarial networks (GANs) and diffusion models (DMs), AI-generated images, or ``deepfakes", have become nearly indistinguishable from real ones. These images are widely shared across Online Social Networks (OSNs), raising concerns about their misuse. Existing deepfake detection methods overlook the ``block effects" introduced by compression in OSNs, which obscure deepfake artifacts, and primarily focus on raw images, rarely encountered in real-world scenarios. To address these challenges, we propose PLADA (Pay Less Attention to Deceptive Artifacts), a novel framework designed to tackle the lack of paired data and the ineffective use of compressed images. PLADA consists of two core modules: Block Effect Eraser (B2E), which uses a dual-stage attention mechanism to handle block effects, and Open Data Aggregation (ODA), which processes both paired and unpaired data to improve detection. Extensive experiments across 26 datasets demonstrate that PLADA achieves a remarkable balance in deepfake detection, outperforming SoTA methods in detecting deepfakes on OSNs, even with limited paired data and compression. More importantly, this work introduces the ``block effect" as a critical factor in deepfake detection, providing a robust solution for open-world scenarios. Our code is available at https://github.com/ManyiLee/PLADA.
Hierarchical Semantic Compression for Consistent Image Semantic Restoration
Feb 24, 2025The emerging semantic compression has been receiving increasing research efforts most recently, capable of achieving high fidelity restoration during compression, even at extremely low bitrates. However, existing semantic compression methods typically combine standard pipelines with either pre-defined or high-dimensional semantics, thus suffering from deficiency in compression. To address this issue, we propose a novel hierarchical semantic compression (HSC) framework that purely operates within intrinsic semantic spaces from generative models, which is able to achieve efficient compression for consistent semantic restoration. More specifically, we first analyse the entropy models for the semantic compression, which motivates us to employ a hierarchical architecture based on a newly developed general inversion encoder. Then, we propose the feature compression network (FCN) and semantic compression network (SCN), such that the middle-level semantic feature and core semantics are hierarchically compressed to restore both accuracy and consistency of image semantics, via an entropy model progressively shared by channel-wise context. Experimental results demonstrate that the proposed HSC framework achieves the state-of-the-art performance on subjective quality and consistency for human vision, together with superior performances on machine vision tasks given compressed bitstreams. This essentially coincides with human visual system in understanding images, thus providing a new framework for future image/video compression paradigms. Our code shall be released upon acceptance.
RealEra: Semantic-level Concept Erasure via Neighbor-Concept Mining
Oct 11, 2024

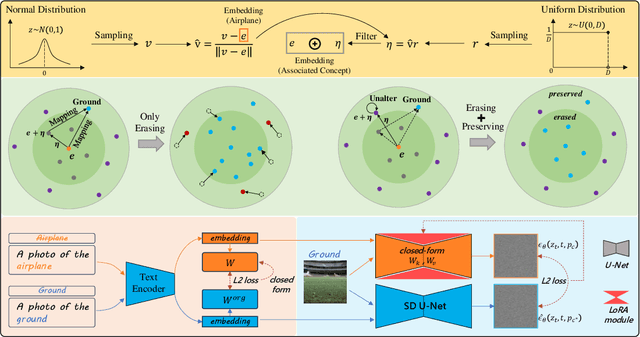
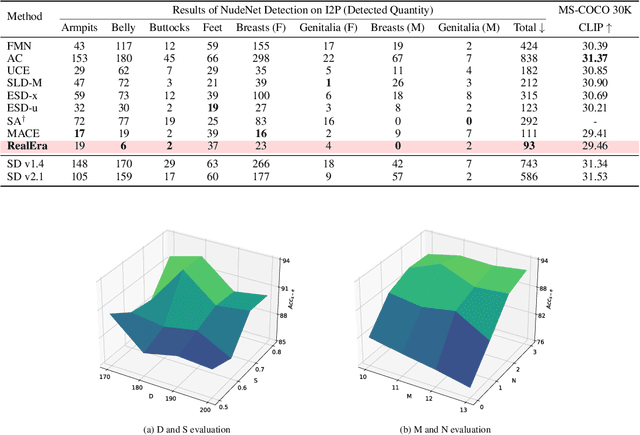
The remarkable development of text-to-image generation models has raised notable security concerns, such as the infringement of portrait rights and the generation of inappropriate content. Concept erasure has been proposed to remove the model's knowledge about protected and inappropriate concepts. Although many methods have tried to balance the efficacy (erasing target concepts) and specificity (retaining irrelevant concepts), they can still generate abundant erasure concepts under the steering of semantically related inputs. In this work, we propose RealEra to address this "concept residue" issue. Specifically, we first introduce the mechanism of neighbor-concept mining, digging out the associated concepts by adding random perturbation into the embedding of erasure concept, thus expanding the erasing range and eliminating the generations even through associated concept inputs. Furthermore, to mitigate the negative impact on the generation of irrelevant concepts caused by the expansion of erasure scope, RealEra preserves the specificity through the beyond-concept regularization. This makes irrelevant concepts maintain their corresponding spatial position, thereby preserving their normal generation performance. We also employ the closed-form solution to optimize weights of U-Net for the cross-attention alignment, as well as the prediction noise alignment with the LoRA module. Extensive experiments on multiple benchmarks demonstrate that RealEra outperforms previous concept erasing methods in terms of superior erasing efficacy, specificity, and generality. More details are available on our project page https://realerasing.github.io/RealEra/ .