 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-World: Building Software Engineering Agents in Docker-Free Environments
Feb 03, 2026Recent advances in large language models (LLMs) have enabled software engineering agents to tackle complex code modification tasks. Most existing approaches rely on execution feedback from containerized environments, which require dependency-complete setup and physical execution of programs and tests. While effective, this paradigm is resource-intensive and difficult to maintain, substantially complicating agent training and limiting scalability. We propose SWE-World, a Docker-free framework that replaces physical execution environments with a learned surrogate for training and evaluating software engineering agents. SWE-World leverages LLM-based models trained on real agent-environment interaction data to predict intermediate execution outcomes and final test feedback, enabling agents to learn without interacting with physical containerized environments. This design preserves the standard agent-environment interaction loop while eliminating the need for costly environment construction and maintenance during agent optimization and evaluation. Furthermore, because SWE-World can simulate the final evaluation outcomes of candidate trajectories without real submission, it enables selecting the best solution among multiple test-time attempts, thereby facilitating effective test-time scaling (TTS) in software engineering tasks. Experiments on SWE-bench Verified demonstrate that SWE-World raises Qwen2.5-Coder-32B from 6.2\% to 52.0\% via Docker-free SFT, 55.0\% with Docker-free RL, and 68.2\% with further TTS. The code is available at https://github.com/RUCAIBox/SWE-World
MMATH: A Multilingual Benchmark for Mathematical Reasoning
May 25, 2025The advent of large reasoning models, such as OpenAI o1 and DeepSeek R1, has significantly advanced complex reasoning tasks. However, their capabilities in multilingual complex reasoning remain underexplored, with existing efforts largely focused on simpler tasks like MGSM. To address this gap, we introduce MMATH, a benchmark for multilingual complex reasoning spanning 374 high-quality math problems across 10 typologically diverse languages. Using MMATH, we observe that even advanced models like DeepSeek R1 exhibit substantial performance disparities across languages and suffer from a critical off-target issue-generating responses in unintended languages. To address this, we explore strategies including prompting and training, demonstrating that reasoning in English and answering in target languages can simultaneously enhance performance and preserve target-language consistency. Our findings offer new insights and practical strategies for advancing the multilingual reasoning capabilities of large language models. Our code and data could be found at https://github.com/RUCAIBox/MMATH.
Token Caching for Diffusion Transformer Acceleration
Sep 27, 2024



Diffusion transformers have gained substantial interest in diffusion generative modeling due to their outstanding performance. However, their high computational cost, arising from the quadratic computational complexity of attention mechanisms and multi-step inference, presents a significant bottleneck. To address this challenge, we propose TokenCache, a novel post-training acceleration method that leverages the token-based multi-block architecture of transformers to reduce redundant computations among tokens across inference steps. TokenCache specifically addresses three critical questions in the context of diffusion transformers: (1) which tokens should be pruned to eliminate redundancy, (2) which blocks should be targeted for efficient pruning, and (3) at which time steps caching should be applied to balance speed and quality. In response to these challenges, TokenCache introduces a Cache Predictor that assigns importance scores to tokens, enabling selective pruning without compromising model performance. Furthermore, we propose an adaptive block selection strategy to focus on blocks with minimal impact on the network's output, along with a Two-Phase Round-Robin (TPRR) scheduling policy to optimize caching intervals throughout the denoising process. Experimental results across various models demonstrate that TokenCache achieves an effective trade-off between generation quality and inference speed for diffusion transformers. Our code will be publicly available.
LLMBox: A Comprehensive Library for Large Language Models
Jul 08, 2024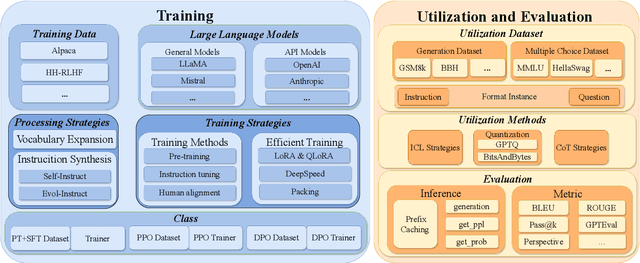
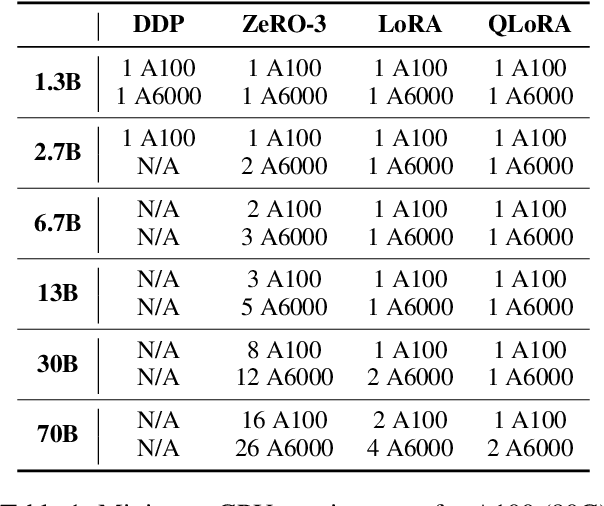


To facilitate the research on large language models (LLMs), this paper presents a comprehensive and unified library, LLMBox, to ease the development, use, and evaluation of LLMs. This library is featured with three main merits: (1) a unified data interface that supports the flexible implementation of various training strategies, (2) a comprehensive evaluation that covers extensive tasks, datasets, and models, and (3) more practical consideration, especially on user-friendliness and efficiency. With our library, users can easily reproduce existing methods, train new models, and conduct comprehensive performance comparisons. To rigorously test LLMBox, we conduct extensive experiments in a diverse coverage of evaluation settings, and experimental results demonstrate the effectiveness and efficiency of our library in supporting various implementations related to LLMs. The detailed introduction and usage guidance can be found at https://github.com/RUCAIBox/LLMBox.
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Feb 26, 2024



Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on two representative LLMs, namely LLaMA-2 and BLOOM. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to "steer" the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.