 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM-based Recommendation with Self-Hard Negatives from Intermediate Layers
Feb 19, 2026Large language models (LLMs) have shown great promise in recommender systems, where supervised fine-tuning (SFT) is commonly used for adaptation. Subsequent studies further introduce preference learning to incorporate negative samples into the training process. However, existing methods rely on sequence-level, offline-generated negatives, making them less discriminative and informative when adapting LLMs to recommendation tasks with large negative item spaces. To address these challenges, we propose ILRec, a novel preference fine-tuning framework for LLM-based recommendation, leveraging self-hard negative signals extracted from intermediate layers to improve preference learning. Specifically, we identify self-hard negative tokens from intermediate layers as fine-grained negative supervision that dynamically reflects the model's preference learning process. To effectively integrate these signals into training, we design a two-stage framework comprising cross-layer preference optimization and cross-layer preference distillation, enabling the model to jointly discriminate informative negatives and enhance the quality of negative signals from intermediate layers. In addition, we introduce a lightweight collaborative filtering model to assign token-level rewards for negative signals, mitigating the risk of over-penalizing false negatives. Extensive experiments on three datasets demonstrate ILRec's effectiveness in enhancing the performance of LLM-based recommender systems.
RecNet: Self-Evolving Preference Propagation for Agentic Recommender Systems
Jan 29, 2026Agentic recommender systems leverage Large Language Models (LLMs) to model complex user behaviors and support personalized decision-making. However, existing methods primarily model preference changes based on explicit user-item interactions, which are sparse, noisy, and unable to reflect the real-time, mutual influences among users and items. To address these limitations, we propose RecNet, a self-evolving preference propagation framework that proactively propagates real-time preference updates across related users and items. RecNet consists of two complementary phases. In the forward phase, the centralized preference routing mechanism leverages router agents to integrate preference updates and dynamically propagate them to the most relevant agents. To ensure accurate and personalized integration of propagated preferences, we further introduce a personalized preference reception mechanism, which combines a message buffer for temporary caching and an optimizable, rule-based filter memory to guide selective preference assimilation based on past experience and interests. In the backward phase, the feedback-driven propagation optimization mechanism simulates a multi-agent reinforcement learning framework, using LLMs for credit assignment, gradient analysis, and module-level optimization, enabling continuous self-evolution of propagation strategies. Extensive experiments on various scenarios demonstrate the effectiveness of RecNet in modeling preference propagation for recommender systems.
LLMBox: A Comprehensive Library for Large Language Models
Jul 08, 2024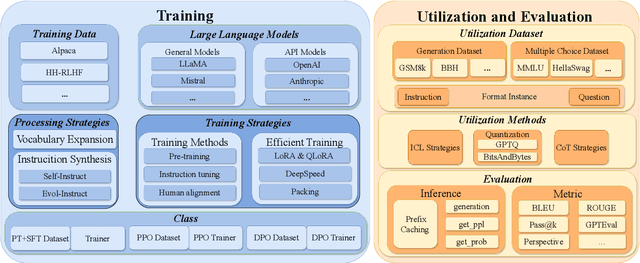
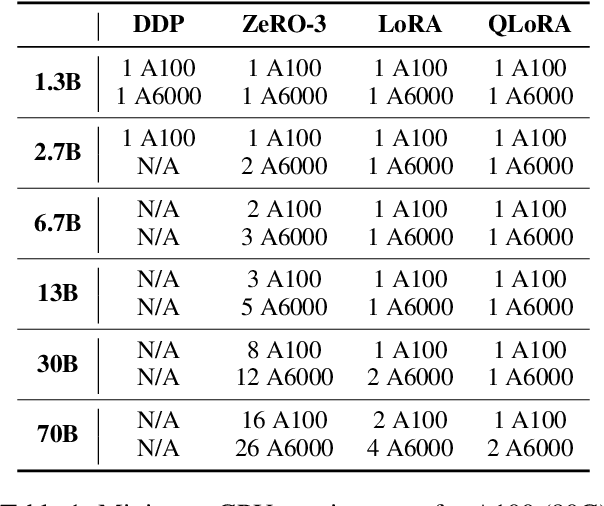


To facilitate the research on large language models (LLMs), this paper presents a comprehensive and unified library, LLMBox, to ease the development, use, and evaluation of LLMs. This library is featured with three main merits: (1) a unified data interface that supports the flexible implementation of various training strategies, (2) a comprehensive evaluation that covers extensive tasks, datasets, and models, and (3) more practical consideration, especially on user-friendliness and efficiency. With our library, users can easily reproduce existing methods, train new models, and conduct comprehensive performance comparisons. To rigorously test LLMBox, we conduct extensive experiments in a diverse coverage of evaluation settings, and experimental results demonstrate the effectiveness and efficiency of our library in supporting various implementations related to LLMs. The detailed introduction and usage guidance can be found at https://github.com/RUCAIBox/LLMBox.
Sequence-level Semantic Representation Fusion for Recommender Systems
Feb 28, 2024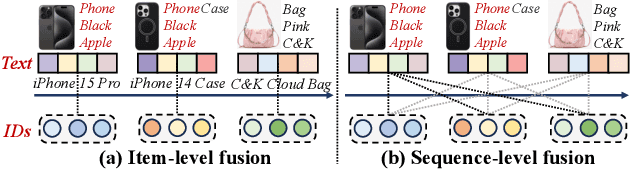
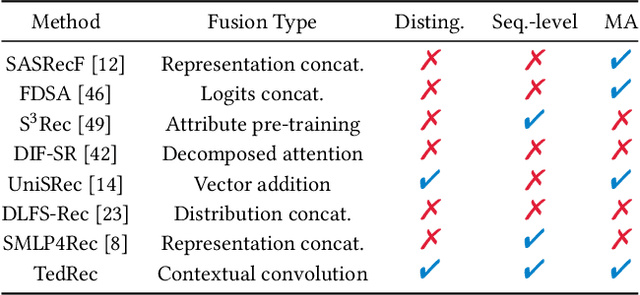
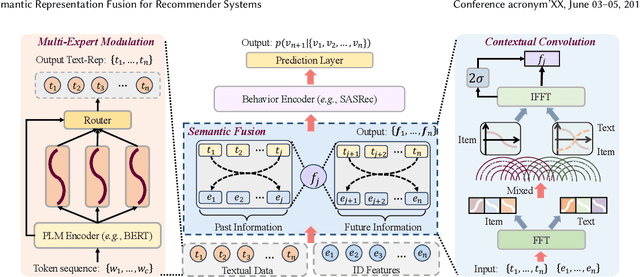
With the rapid development of recommender systems, there is increasing side information that can be employed to improve the recommendation performance. Specially, we focus on the utilization of the associated \emph{textual data} of items (eg product title) and study how text features can be effectively fused with ID features in sequential recommendation. However, there exists distinct data characteristics for the two kinds of item features, making a direct fusion method (eg adding text and ID embeddings as item representation) become less effective. To address this issue, we propose a novel {\ul \emph{Te}}xt-I{\ul \emph{D}} semantic fusion approach for sequential {\ul \emph{Rec}}ommendation, namely \textbf{\our}. The core idea of our approach is to conduct a sequence-level semantic fusion approach by better integrating global contexts. The key strategy lies in that we transform the text embeddings and ID embeddings by Fourier Transform from \emph{time domain} to \emph{frequency domain}. In the frequency domain, the global sequential characteristics of the original sequences are inherently aggregated into the transformed representations, so that we can employ simple multiplicative operations to effectively fuse the two kinds of item features. Our fusion approach can be proved to have the same effects of contextual convolution, so as to achieving sequence-level semantic fusion. In order to further improve the fusion performance, we propose to enhance the discriminability of the text embeddings from the text encoder, by adaptively injecting positional information via a mixture-of-experts~(MoE) modulation method. Our implementation is available at this repository: \textcolor{magenta}{\url{https://github.com/RUCAIBox/TedRec}}.
Prompting Large Language Models for Recommender Systems: A Comprehensive Framework and Empirical Analysis
Jan 10, 2024



Recently, large language models such as ChatGPT have showcased remarkable abilities in solving general tasks, demonstrating the potential for applications in recommender systems. To assess how effectively LLMs can be used in recommendation tasks, our study primarily focuses on employing LLMs as recommender systems through prompting engineering. We propose a general framework for utilizing LLMs in recommendation tasks, focusing on the capabilities of LLMs as recommenders. To conduct our analysis, we formalize the input of LLMs for recommendation into natural language prompts with two key aspects, and explain how our framework can be generalized to various recommendation scenarios. As for the use of LLMs as recommenders, we analyze the impact of public availability, tuning strategies, model architecture, parameter scale, and context length on recommendation results based on the classification of LLMs. As for prompt engineering, we further analyze the impact of four important components of prompts, \ie task descriptions, user interest modeling, candidate items construction and prompting strategies. In each section, we first define and categorize concepts in line with the existing literature. Then, we propose inspiring research questions followed by experiments to systematically analyze the impact of different factors on two public datasets. Finally, we summarize promising directions to shed lights on future research.