 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-level Semantic Representation Fusion for Recommender Systems
Feb 28, 2024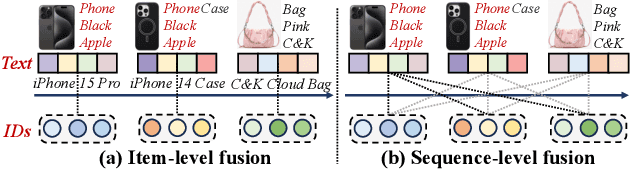
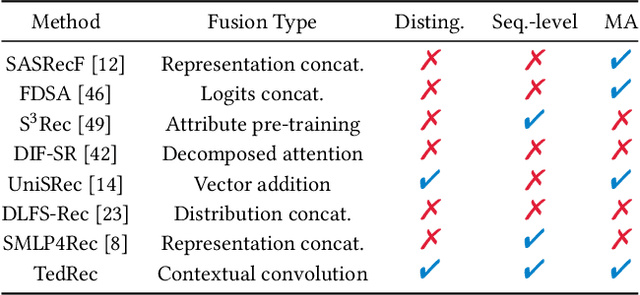
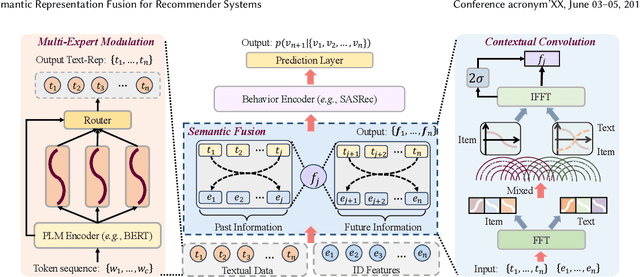
With the rapid development of recommender systems, there is increasing side information that can be employed to improve the recommendation performance. Specially, we focus on the utilization of the associated \emph{textual data} of items (eg product title) and study how text features can be effectively fused with ID features in sequential recommendation. However, there exists distinct data characteristics for the two kinds of item features, making a direct fusion method (eg adding text and ID embeddings as item representation) become less effective. To address this issue, we propose a novel {\ul \emph{Te}}xt-I{\ul \emph{D}} semantic fusion approach for sequential {\ul \emph{Rec}}ommendation, namely \textbf{\our}. The core idea of our approach is to conduct a sequence-level semantic fusion approach by better integrating global contexts. The key strategy lies in that we transform the text embeddings and ID embeddings by Fourier Transform from \emph{time domain} to \emph{frequency domain}. In the frequency domain, the global sequential characteristics of the original sequences are inherently aggregated into the transformed representations, so that we can employ simple multiplicative operations to effectively fuse the two kinds of item features. Our fusion approach can be proved to have the same effects of contextual convolution, so as to achieving sequence-level semantic fusion. In order to further improve the fusion performance, we propose to enhance the discriminability of the text embeddings from the text encoder, by adaptively injecting positional information via a mixture-of-experts~(MoE) modulation method. Our implementation is available at this repository: \textcolor{magenta}{\url{https://github.com/RUCAIBox/TedRec}}.
Prompting Large Language Models for Recommender Systems: A Comprehensive Framework and Empirical Analysis
Jan 10, 2024



Recently, large language models such as ChatGPT have showcased remarkable abilities in solving general tasks, demonstrating the potential for applications in recommender systems. To assess how effectively LLMs can be used in recommendation tasks, our study primarily focuses on employing LLMs as recommender systems through prompting engineering. We propose a general framework for utilizing LLMs in recommendation tasks, focusing on the capabilities of LLMs as recommenders. To conduct our analysis, we formalize the input of LLMs for recommendation into natural language prompts with two key aspects, and explain how our framework can be generalized to various recommendation scenarios. As for the use of LLMs as recommenders, we analyze the impact of public availability, tuning strategies, model architecture, parameter scale, and context length on recommendation results based on the classification of LLMs. As for prompt engineering, we further analyze the impact of four important components of prompts, \ie task descriptions, user interest modeling, candidate items construction and prompting strategies. In each section, we first define and categorize concepts in line with the existing literature. Then, we propose inspiring research questions followed by experiments to systematically analyze the impact of different factors on two public datasets. Finally, we summarize promising directions to shed lights on future research.
Recent Advances in RecBole: Extensions with more Practical Considerations
Nov 28, 2022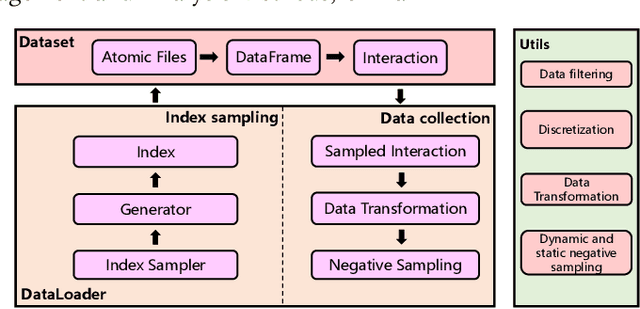



RecBole has recently attracted increasing attention from the research community. As the increase of the number of users, we have received a number of suggestions and update requests. This motivates us to make some significant improvements on our library, so as to meet the user requirements and contribute to the research community. In order to show the recent update in RecBole, we write this technical report to introduce our latest improvements on RecBole. In general, we focus on the flexibility and efficiency of RecBole in the past few months. More specifically, we have four development targets: (1) more flexible data processing, (2) more efficient model training, (3) more reproducible configurations, and (4) more comprehensive user documentation. Readers can download the above updates at: https://github.com/RUCAIBox/RecBole.
RecBole 2.0: Towards a More Up-to-Date Recommendation Library
Jun 16, 2022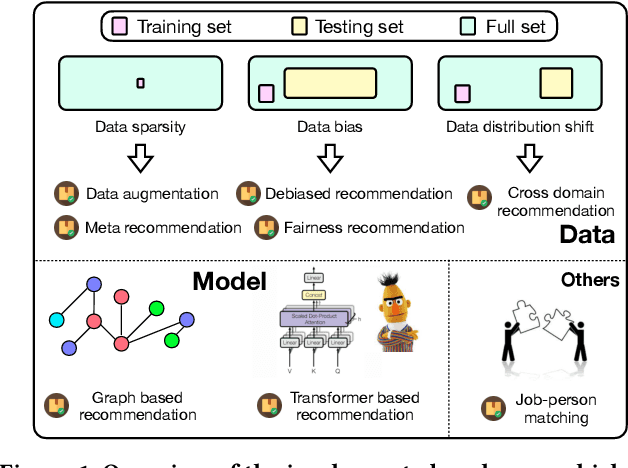
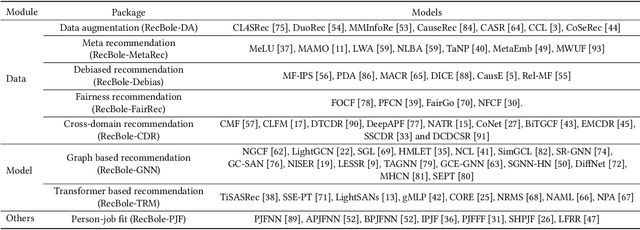

In order to support the study of recent advances in recommender systems, this paper presents an extended recommendation library consisting of eight packages for up-to-date topics and architectures. First of all, from a data perspective, we consider three important topics related to data issues (i.e., sparsity, bias and distribution shift), and develop five packages accordingly: meta-learning, data augmentation, debiasing, fairness and cross-domain recommendation. Furthermore, from a model perspective, we develop two benchmarking packages for Transformer-based and graph neural network (GNN)-based models, respectively. All the packages (consisting of 65 new models) are developed based on a popular recommendation framework RecBole, ensuring that both the implementation and interface are unified. For each package, we provide complete implementations from data loading, experimental setup, evaluation and algorithm implementation. This library provides a valuable resource to facilitate the up-to-date research in recommender systems. The project is released at the link: https://github.com/RUCAIBox/RecBole2.0.
Negative Sampling for Contrastive Representation Learning: A Review
Jun 01, 2022
The learn-to-compare paradigm of contrastive representation learning (CRL), which compares positive samples with negative ones for representation learning, has achieved great success in a wide range of domains, including natural language processing, computer vision, information retrieval and graph learning. While many research works focus on data augmentations, nonlinear transformations or other certain parts of CRL, the importance of negative sample selection is usually overlooked in literature. In this paper, we provide a systematic review of negative sampling (NS) techniques and discuss how they contribute to the success of CRL. As the core part of this paper, we summarize the existing NS methods into four categories with pros and cons in each genre, and further conclude with several open research questions as future directions. By generalizing and aligning the fundamental NS ideas across multiple domains, we hope this survey can accelerate cross-domain knowledge sharing and motivate future researches for better CRL.