 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSTODE: Ocean-Atmosphere Physics-Informed Neural ODEs for Sea Surface Temperature Prediction
Nov 07, 2025Sea Surface Temperature (SST) is crucial for understanding upper-ocean thermal dynamics and ocean-atmosphere interactions, which have profound economic and social impacts. While data-driven models show promise in SST prediction, their black-box nature often limits interpretability and overlooks key physical processes. Recently, physics-informed neural networks have been gaining momentum but struggle with complex ocean-atmosphere dynamics due to 1) inadequate characterization of seawater movement (e.g., coastal upwelling) and 2) insufficient integration of external SST drivers (e.g., turbulent heat fluxes). To address these challenges, we propose SSTODE, a physics-informed Neural Ordinary Differential Equations (Neural ODEs) framework for SST prediction. First, we derive ODEs from fluid transport principles, incorporating both advection and diffusion to model ocean spatiotemporal dynamics. Through variational optimization, we recover a latent velocity field that explicitly governs the temporal dynamics of SST. Building upon ODE, we introduce an Energy Exchanges Integrator (EEI)-inspired by ocean heat budget equations-to account for external forcing factors. Thus, the variations in the components of these factors provide deeper insights into SST dynamics. Extensive experiments demonstrate that SSTODE achieves state-of-the-art performances in global and regional SST forecasting benchmarks. Furthermore, SSTODE visually reveals the impact of advection dynamics, thermal diffusion patterns, and diurnal heating-cooling cycles on SST evolution. These findings demonstrate the model's interpretability and physical consistency.
Rocks Coding, Not Development--A Human-Centric, Experimental Evaluation of LLM-Supported SE Tasks
Feb 21, 2024Recently, large language models (LLM) based generative AI has been gaining momentum for their impressive high-quality performances in multiple domains, particularly after the release of the ChatGPT. Many believe that they have the potential to perform general-purpose problem-solving in software development and replace human software developers. Nevertheless, there are in a lack of serious investigation into the capability of these LLM techniques in fulfilling software development tasks. In a controlled 2 x 2 between-subject experiment with 109 participants, we examined whether and to what degree working with ChatGPT was helpful in the coding task and typical software development task and how people work with ChatGPT. We found that while ChatGPT performed well in solving simple coding problems, its performance in supporting typical software development tasks was not that good. We also observed the interactions between participants and ChatGPT and found the relations between the interactions and the outcomes. Our study thus provides first-hand insights into using ChatGPT to fulfill software engineering tasks with real-world developers and motivates the need for novel interaction mechanisms that help developers effectively work with large language models to achieve desired outcomes.
Scaling Law of Large Sequential Recommendation Models
Nov 19, 2023Scaling of neural networks has recently shown great potential to improve the model capacity in various fields. Specifically, model performance has a power-law relationship with model size or data size, which provides important guidance for the development of large-scale models. However, there is still limited understanding on the scaling effect of user behavior models in recommender systems, where the unique data characteristics (e.g. data scarcity and sparsity) pose new challenges to explore the scaling effect in recommendation tasks. In this work, we focus on investigating the scaling laws in large sequential recommendation models. Specially, we consider a pure ID-based task formulation, where the interaction history of a user is formatted as a chronological sequence of item IDs. We don't incorporate any side information (e.g. item text), because we would like to explore how scaling law holds from the perspective of user behavior. With specially improved strategies, we scale up the model size to 0.8B parameters, making it feasible to explore the scaling effect in a diverse range of model sizes. As the major findings, we empirically show that scaling law still holds for these trained models, even in data-constrained scenarios. We then fit the curve for scaling law, and successfully predict the test loss of the two largest tested model scales. Furthermore, we examine the performance advantage of scaling effect on five challenging recommendation tasks, considering the unique issues (e.g. cold start, robustness, long-term preference) in recommender systems. We find that scaling up the model size can greatly boost the performance on these challenging tasks, which again verifies the benefits of large recommendation models.
Towards Spatio-temporal Sea Surface Temperature Forecasting via Static and Dynamic Learnable Personalized Graph Convolution Network
Apr 12, 2023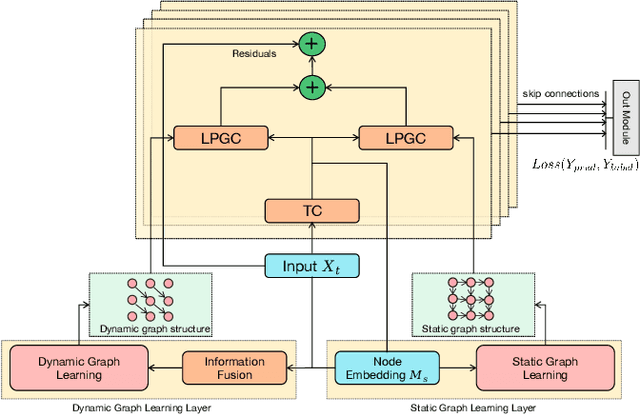
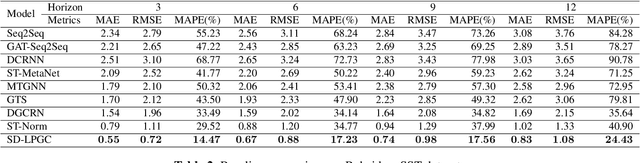
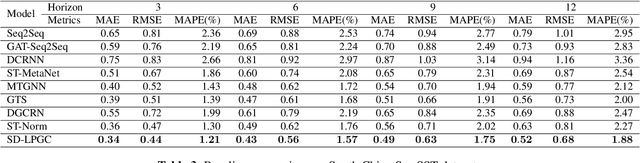
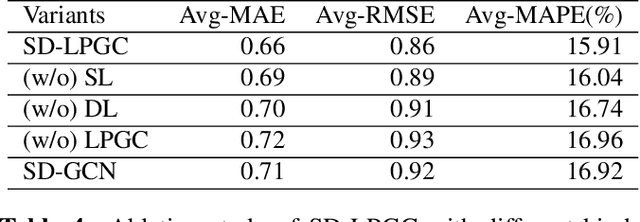
Sea surface temperature (SST) is uniquely important to the Earth's atmosphere since its dynamics are a major force in shaping local and global climate and profoundly affect our ecosystems. Accurate forecasting of SST brings significant economic and social implications, for example, better preparation for extreme weather such as severe droughts or tropical cyclones months ahead. However, such a task faces unique challenges due to the intrinsic complexity and uncertainty of ocean systems. Recently, deep learning techniques, such as graphical neural networks (GNN), have been applied to address this task. Even though these methods have some success, they frequently have serious drawbacks when it comes to investigating dynamic spatiotemporal dependencies between signals. To solve this problem, this paper proposes a novel static and dynamic learnable personalized graph convolution network (SD-LPGC). Specifically, two graph learning layers are first constructed to respectively model the stable long-term and short-term evolutionary patterns hidden in the multivariate SST signals. Then, a learnable personalized convolution layer is designed to fuse this information. Our experiments on real SST datasets demonstrate the state-of-the-art performances of the proposed approach on the forecasting task.
Recent Advances in RecBole: Extensions with more Practical Considerations
Nov 28, 2022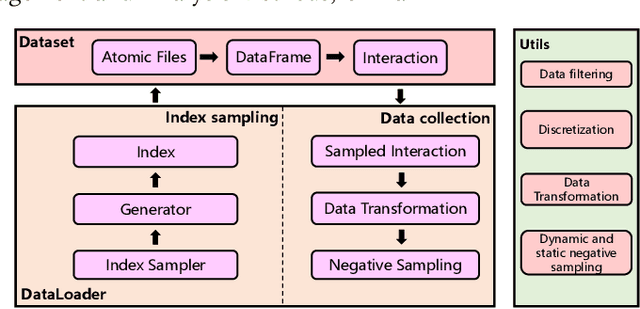



RecBole has recently attracted increasing attention from the research community. As the increase of the number of users, we have received a number of suggestions and update requests. This motivates us to make some significant improvements on our library, so as to meet the user requirements and contribute to the research community. In order to show the recent update in RecBole, we write this technical report to introduce our latest improvements on RecBole. In general, we focus on the flexibility and efficiency of RecBole in the past few months. More specifically, we have four development targets: (1) more flexible data processing, (2) more efficient model training, (3) more reproducible configurations, and (4) more comprehensive user documentation. Readers can download the above updates at: https://github.com/RUCAIBox/RecBole.
RecBole 2.0: Towards a More Up-to-Date Recommendation Library
Jun 16, 2022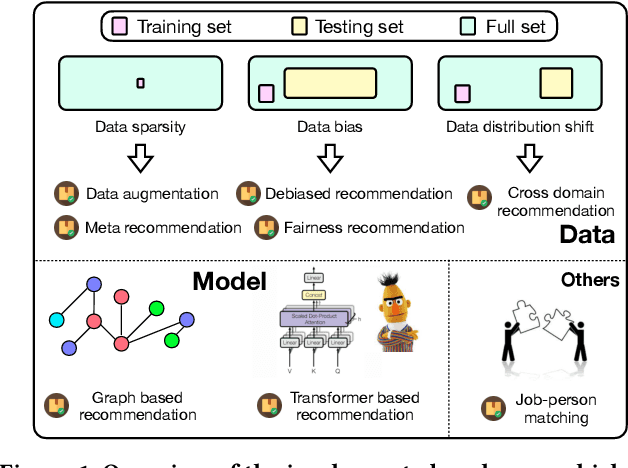
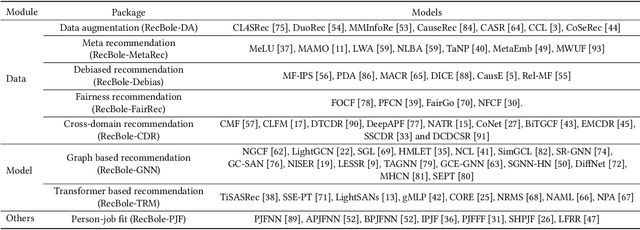

In order to support the study of recent advances in recommender systems, this paper presents an extended recommendation library consisting of eight packages for up-to-date topics and architectures. First of all, from a data perspective, we consider three important topics related to data issues (i.e., sparsity, bias and distribution shift), and develop five packages accordingly: meta-learning, data augmentation, debiasing, fairness and cross-domain recommendation. Furthermore, from a model perspective, we develop two benchmarking packages for Transformer-based and graph neural network (GNN)-based models, respectively. All the packages (consisting of 65 new models) are developed based on a popular recommendation framework RecBole, ensuring that both the implementation and interface are unified. For each package, we provide complete implementations from data loading, experimental setup, evaluation and algorithm implementation. This library provides a valuable resource to facilitate the up-to-date research in recommender systems. The project is released at the link: https://github.com/RUCAIBox/RecBole2.0.
Dynamic Graph Learning-Neural Network for Multivariate Time Series Modeling
Dec 06, 2021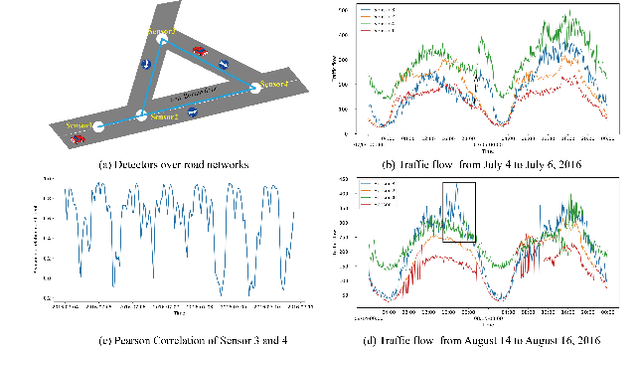
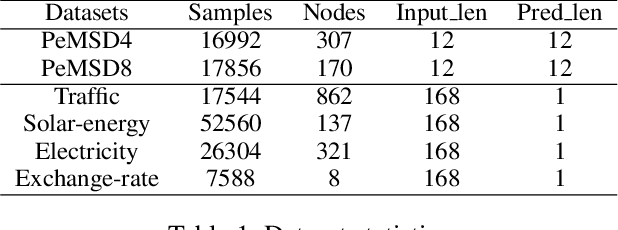
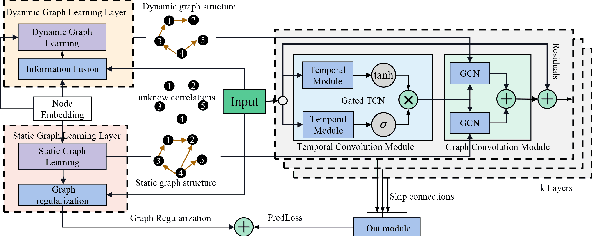

Multivariate time series forecasting is a challenging task because the data involves a mixture of long- and short-term patterns, with dynamic spatio-temporal dependencies among variables. Existing graph neural networks (GNN) typically model multivariate relationships with a pre-defined spatial graph or learned fixed adjacency graph. It limits the application of GNN and fails to handle the above challenges. In this paper, we propose a novel framework, namely static- and dynamic-graph learning-neural network (SDGL). The model acquires static and dynamic graph matrices from data to model long- and short-term patterns respectively. Static matric is developed to capture the fixed long-term association pattern via node embeddings, and we leverage graph regularity for controlling the quality of the learned static graph. To capture dynamic dependencies among variables, we propose dynamic graphs learning method to generate time-varying matrices based on changing node features and static node embeddings. And in the method, we integrate the learned static graph information as inductive bias to construct dynamic graphs and local spatio-temporal patterns better. Extensive experiments are conducted on two traffic datasets with extra structural information and four time series datasets, which show that our approach achieves state-of-the-art performance on almost all datasets. If the paper is accepted, I will open the source code on github.