 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDWM: Towards a Unified Driving World Model via Multifaceted Representation Learning
Feb 02, 2026Achieving reliable and efficient planning in complex driving environments requires a model that can reason over the scene's geometry, appearance, and dynamics. We present UniDWM, a unified driving world model that advances autonomous driving through multifaceted representation learning. UniDWM constructs a structure- and dynamic-aware latent world representation that serves as a physically grounded state space, enabling consistent reasoning across perception, prediction, and planning. Specifically, a joint reconstruction pathway learns to recover the scene's structure, including geometry and visual texture, while a collaborative generation framework leverages a conditional diffusion transformer to forecast future world evolution within the latent space. Furthermore, we show that our UniDWM can be deemed as a variation of VAE, which provides theoretical guidance for the multifaceted representation learning. Extensive experiments demonstrate the effectiveness of UniDWM in trajectory planning, 4D reconstruction and generation, highlighting the potential of multifaceted world representations as a foundation for unified driving intelligence. The code will be publicly available at https://github.com/Say2L/UniDWM.
E2PL: Effective and Efficient Prompt Learning for Incomplete Multi-view Multi-Label Class Incremental Learning
Jan 23, 2026Multi-view multi-label classification (MvMLC) is indispensable for modern web applications aggregating information from diverse sources. However, real-world web-scale settings are rife with missing views and continuously emerging classes, which pose significant obstacles to robust learning. Prevailing methods are ill-equipped for this reality, as they either lack adaptability to new classes or incur exponential parameter growth when handling all possible missing-view patterns, severely limiting their scalability in web environments. To systematically address this gap, we formally introduce a novel task, termed \emph{incomplete multi-view multi-label class incremental learning} (IMvMLCIL), which requires models to simultaneously address heterogeneous missing views and dynamic class expansion. To tackle this task, we propose \textsf{E2PL}, an Effective and Efficient Prompt Learning framework for IMvMLCIL. \textsf{E2PL} unifies two novel prompt designs: \emph{task-tailored prompts} for class-incremental adaptation and \emph{missing-aware prompts} for the flexible integration of arbitrary view-missing scenarios. To fundamentally address the exponential parameter explosion inherent in missing-aware prompts, we devise an \emph{efficient prototype tensorization} module, which leverages atomic tensor decomposition to elegantly reduce the prompt parameter complexity from exponential to linear w.r.t. the number of views. We further incorporate a \emph{dynamic contrastive learning} strategy explicitly model the complex dependencies among diverse missing-view patterns, thus enhancing the model's robustness. Extensive experiments on three benchmarks demonstrate that \textsf{E2PL} consistently outperforms state-of-the-art methods in both effectiveness and efficiency. The codes and datasets are available at https://anonymous.4open.science/r/code-for-E2PL.
E-Navi: Environmental Adaptive Navigation for UAVs on Resource Constrained Platforms
Dec 16, 2025
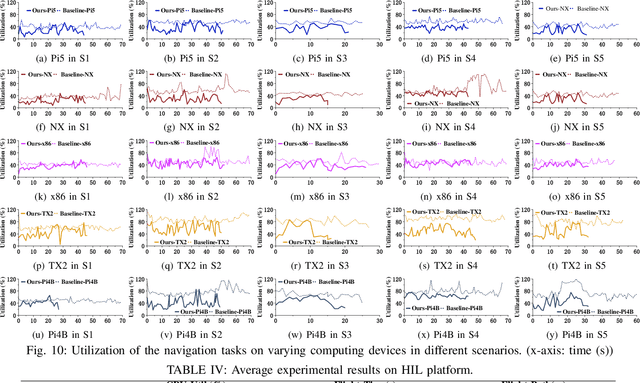
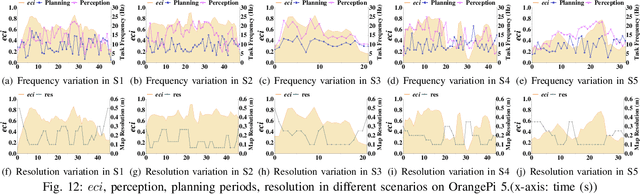
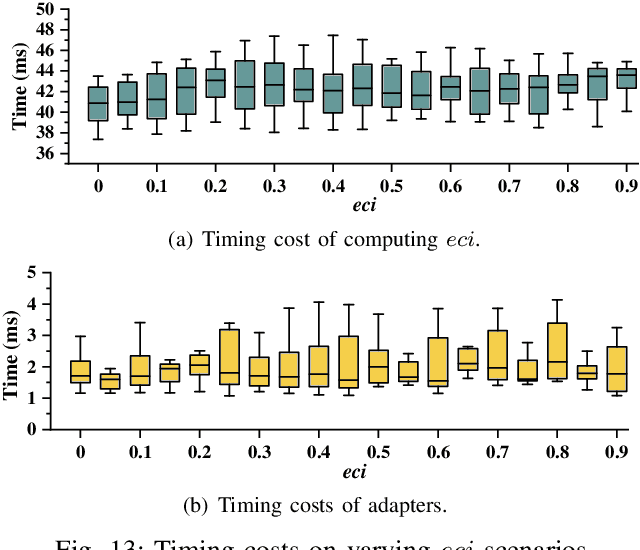
The ability to adapt to changing environments is crucial for the autonomous navigation systems of Unmanned Aerial Vehicles (UAVs). However, existing navigation systems adopt fixed execution configurations without considering environmental dynamics based on available computing resources, e.g., with a high execution frequency and task workload. This static approach causes rigid flight strategies and excessive computations, ultimately degrading flight performance or even leading to failures in UAVs. Despite the necessity for an adaptive system, dynamically adjusting workloads remains challenging, due to difficulties in quantifying environmental complexity and modeling the relationship between environment and system configuration. Aiming at adapting to dynamic environments, this paper proposes E-Navi, an environmental-adaptive navigation system for UAVs that dynamically adjusts task executions on the CPUs in response to environmental changes based on available computational resources. Specifically, the perception-planning pipeline of UAVs navigation system is redesigned through dynamic adaptation of mapping resolution and execution frequency, driven by the quantitative environmental complexity evaluations. In addition, E-Navi supports flexible deployment across hardware platforms with varying levels of computing capability. Extensive Hardware-In-the-Loop and real-world experiments demonstrate that the proposed system significantly outperforms the baseline method across various hardware platforms, achieving up to 53.9% navigation task workload reduction, up to 63.8% flight time savings, and delivering more stable velocity control.
Protecting participants or population? Comparison of k-anonymous Origin-Destination matrices
Sep 16, 2025Origin-Destination (OD) matrices are a core component of research on users' mobility and summarize how individuals move between geographical regions. These regions should be small enough to be representative of user mobility, without incurring substantial privacy risks. There are two added values of the NetMob2025 challenge dataset. Firstly, the data is extensive and contains a lot of socio-demographic information that can be used to create multiple OD matrices, based on the segments of the population. Secondly, a participant is not merely a record in the data, but a statistically weighted proxy for a segment of the real population. This opens the door to a fundamental shift in the anonymization paradigm. A population-based view of privacy is central to our contribution. By adjusting our anonymization framework to account for representativeness, we are also protecting the inferred identity of the actual population, rather than survey participants alone. The challenge addressed in this work is to produce and compare OD matrices that are k-anonymous for survey participants and for the whole population. We compare several traditional methods of anonymization to k-anonymity by generalizing geographical areas. These include generalization over a hierarchy (ATG and OIGH) and the classical Mondrian. To this established toolkit, we add a novel method, i.e., ODkAnon, a greedy algorithm aiming at balancing speed and quality. Unlike previous approaches, which primarily address the privacy aspects of the given datasets, we aim to contribute to the generation of privacy-preserving OD matrices enriched with socio-demographic segmentation that achieves k-anonymity on the actual population.
CLAPS: A CLIP-Unified Auto-Prompt Segmentation for Multi-Modal Retinal Imaging
Sep 10, 2025Recent advancements in foundation models, such as the Segment Anything Model (SAM), have significantly impacted medical image segmentation, especially in retinal imaging, where precise segmentation is vital for diagnosis. Despite this progress, current methods face critical challenges: 1) modality ambiguity in textual disease descriptions, 2) a continued reliance on manual prompting for SAM-based workflows, and 3) a lack of a unified framework, with most methods being modality- and task-specific. To overcome these hurdles, we propose CLIP-unified Auto-Prompt Segmentation (\CLAPS), a novel method for unified segmentation across diverse tasks and modalities in retinal imaging. Our approach begins by pre-training a CLIP-based image encoder on a large, multi-modal retinal dataset to handle data scarcity and distribution imbalance. We then leverage GroundingDINO to automatically generate spatial bounding box prompts by detecting local lesions. To unify tasks and resolve ambiguity, we use text prompts enhanced with a unique "modality signature" for each imaging modality. Ultimately, these automated textual and spatial prompts guide SAM to execute precise segmentation, creating a fully automated and unified pipeline. Extensive experiments on 12 diverse datasets across 11 critical segmentation categories show that CLAPS achieves performance on par with specialized expert models while surpassing existing benchmarks across most metrics, demonstrating its broad generalizability as a foundation model.
UOPSL: Unpaired OCT Predilection Sites Learning for Fundus Image Diagnosis Augmentation
Sep 10, 2025Significant advancements in AI-driven multimodal medical image diagnosis have led to substantial improvements in ophthalmic disease identification in recent years. However, acquiring paired multimodal ophthalmic images remains prohibitively expensive. While fundus photography is simple and cost-effective, the limited availability of OCT data and inherent modality imbalance hinder further progress. Conventional approaches that rely solely on fundus or textual features often fail to capture fine-grained spatial information, as each imaging modality provides distinct cues about lesion predilection sites. In this study, we propose a novel unpaired multimodal framework \UOPSL that utilizes extensive OCT-derived spatial priors to dynamically identify predilection sites, enhancing fundus image-based disease recognition. Our approach bridges unpaired fundus and OCTs via extended disease text descriptions. Initially, we employ contrastive learning on a large corpus of unpaired OCT and fundus images while simultaneously learning the predilection sites matrix in the OCT latent space. Through extensive optimization, this matrix captures lesion localization patterns within the OCT feature space. During the fine-tuning or inference phase of the downstream classification task based solely on fundus images, where paired OCT data is unavailable, we eliminate OCT input and utilize the predilection sites matrix to assist in fundus image classification learning. Extensive experiments conducted on 9 diverse datasets across 28 critical categories demonstrate that our framework outperforms existing benchmarks.
Power Allocation for Delay Optimization in Device-to-Device Networks: A Graph Reinforcement Learning Approach
May 19, 2025The pursuit of rate maximization in wireless communication frequently encounters substantial challenges associated with user fairness. This paper addresses these challenges by exploring a novel power allocation approach for delay optimization, utilizing graph neural networks (GNNs)-based reinforcement learning (RL) in device-to-device (D2D) communication. The proposed approach incorporates not only channel state information but also factors such as packet delay, the number of backlogged packets, and the number of transmitted packets into the components of the state information. We adopt a centralized RL method, where a central controller collects and processes the state information. The central controller functions as an agent trained using the proximal policy optimization (PPO) algorithm. To better utilize topology information in the communication network and enhance the generalization of the proposed method, we embed GNN layers into both the actor and critic networks of the PPO algorithm. This integration allows for efficient parameter updates of GNNs and enables the state information to be parameterized as a low-dimensional embedding, which is leveraged by the agent to optimize power allocation strategies. Simulation results demonstrate that the proposed method effectively reduces average delay while ensuring user fairness, outperforms baseline methods, and exhibits scalability and generalization capability.
AirCache: Activating Inter-modal Relevancy KV Cache Compression for Efficient Large Vision-Language Model Inference
Mar 31, 2025Recent advancements in Large Visual Language Models (LVLMs) have gained significant attention due to their remarkable reasoning capabilities and proficiency in generalization. However, processing a large number of visual tokens and generating long-context outputs impose substantial computational overhead, leading to excessive demands for key-value (KV) cache. To address this critical bottleneck, we propose AirCache, a novel KV cache compression method aimed at accelerating LVLMs inference. This work systematically investigates the correlations between visual and textual tokens within the attention mechanisms of LVLMs. Our empirical analysis reveals considerable redundancy in cached visual tokens, wherein strategically eliminating these tokens preserves model performance while significantly accelerating context generation. Inspired by these findings, we introduce an elite observation window for assessing the importance of visual components in the KV cache, focusing on stable inter-modal relevancy modeling with enhanced multi-perspective consistency. Additionally, we develop an adaptive layer-wise budget allocation strategy that capitalizes on the strength and skewness of token importance distribution, showcasing superior efficiency compared to uniform allocation. Comprehensive evaluations across multiple LVLMs and benchmarks demonstrate that our method achieves comparable performance to the full cache while retaining only 10% of visual KV cache, thereby reducing decoding latency by 29% to 66% across various batch size and prompt length of inputs. Notably, as cache retention rates decrease, our method exhibits increasing performance advantages over existing approaches.
Pick-and-place Manipulation Across Grippers Without Retraining: A Learning-optimization Diffusion Policy Approach
Feb 21, 2025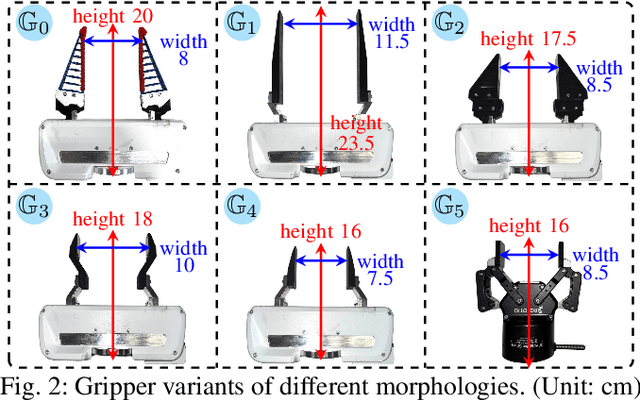
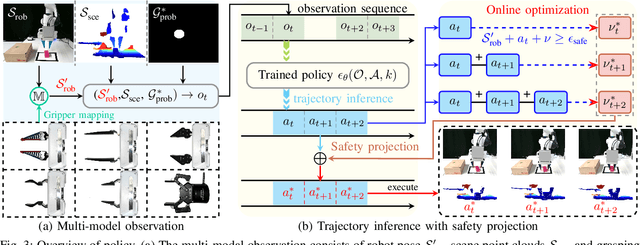

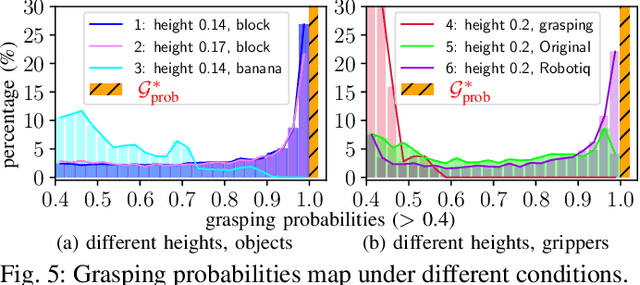
Current robotic pick-and-place policies typically require consistent gripper configurations across training and inference. This constraint imposes high retraining or fine-tuning costs, especially for imitation learning-based approaches, when adapting to new end-effectors. To mitigate this issue, we present a diffusion-based policy with a hybrid learning-optimization framework, enabling zero-shot adaptation to novel grippers without additional data collection for retraining policy. During training, the policy learns manipulation primitives from demonstrations collected using a base gripper. At inference, a diffusion-based optimization strategy dynamically enforces kinematic and safety constraints, ensuring that generated trajectories align with the physical properties of unseen grippers. This is achieved through a constrained denoising procedure that adapts trajectories to gripper-specific parameters (e.g., tool-center-point offsets, jaw widths) while preserving collision avoidance and task feasibility. We validate our method on a Franka Panda robot across six gripper configurations, including 3D-printed fingertips, flexible silicone gripper, and Robotiq 2F-85 gripper. Our approach achieves a 93.3% average task success rate across grippers (vs. 23.3-26.7% for diffusion policy baselines), supporting tool-center-point variations of 16-23.5 cm and jaw widths of 7.5-11.5 cm. The results demonstrate that constrained diffusion enables robust cross-gripper manipulation while maintaining the sample efficiency of imitation learning, eliminating the need for gripper-specific retraining. Video and code are available at https://github.com/yaoxt3/GADP.
A Real-Time System for Scheduling and Managing UAV Delivery in Urban
Dec 16, 2024



As urban logistics demand continues to grow, UAV delivery has become a key solution to improve delivery efficiency, reduce traffic congestion, and lower logistics costs. However, to fully leverage the potential of UAV delivery networks, efficient swarm scheduling and management are crucial. In this paper, we propose a real-time scheduling and management system based on the ``Airport-Unloading Station" model, aiming to bridge the gap between high-level scheduling algorithms and low-level execution systems. This system, acting as middleware, accurately translates the requirements from the scheduling layer into specific execution instructions, ensuring that the scheduling algorithms perform effectively in real-world environments. Additionally, we implement three collaborative scheduling schemes involving autonomous ground vehicles (AGVs), unmanned aerial vehicles (UAVs), and ground staff to further optimize overall delivery efficiency. Through extensive experiments, this study demonstrates the rationality and feasibility of the proposed management system, providing practical solution for the commercial application of UAVs delivery in urban. Code: https://github.com/chengji253/UAVDeliverySystem