 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Unobserved Confounders: A Kernelized Regression Approach
Jan 01, 2026Detecting unobserved confounders is crucial for reliable causal inference in observational studies. Existing methods require either linearity assumptions or multiple heterogeneous environments, limiting applicability to nonlinear single-environment settings. To bridge this gap, we propose Kernel Regression Confounder Detection (KRCD), a novel method for detecting unobserved confounding in nonlinear observational data under single-environment conditions. KRCD leverages reproducing kernel Hilbert spaces to model complex dependencies. By comparing standard and higherorder kernel regressions, we derive a test statistic whose significant deviation from zero indicates unobserved confounding. Theoretically, we prove two key results: First, in infinite samples, regression coefficients coincide if and only if no unobserved confounders exist. Second, finite-sample differences converge to zero-mean Gaussian distributions with tractable variance. Extensive experiments on synthetic benchmarks and the Twins dataset demonstrate that KRCD not only outperforms existing baselines but also achieves superior computational efficiency.
Generating Risky Samples with Conformity Constraints via Diffusion Models
Dec 21, 2025Although neural networks achieve promising performance in many tasks, they may still fail when encountering some examples and bring about risks to applications. To discover risky samples, previous literature attempts to search for patterns of risky samples within existing datasets or inject perturbation into them. Yet in this way the diversity of risky samples is limited by the coverage of existing datasets. To overcome this limitation, recent works adopt diffusion models to produce new risky samples beyond the coverage of existing datasets. However, these methods struggle in the conformity between generated samples and expected categories, which could introduce label noise and severely limit their effectiveness in applications. To address this issue, we propose RiskyDiff that incorporates the embeddings of both texts and images as implicit constraints of category conformity. We also design a conformity score to further explicitly strengthen the category conformity, as well as introduce the mechanisms of embedding screening and risky gradient guidance to boost the risk of generated samples. Extensive experiments reveal that RiskyDiff greatly outperforms existing methods in terms of the degree of risk, generation quality, and conformity with conditioned categories. We also empirically show the generalization ability of the models can be enhanced by augmenting training data with generated samples of high conformity.
GEA: Generation-Enhanced Alignment for Text-to-Image Person Retrieval
Nov 13, 2025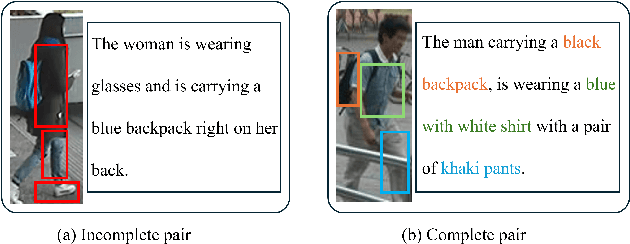
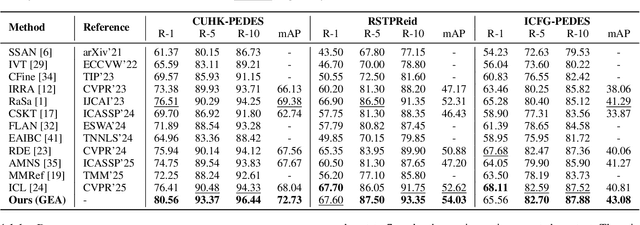
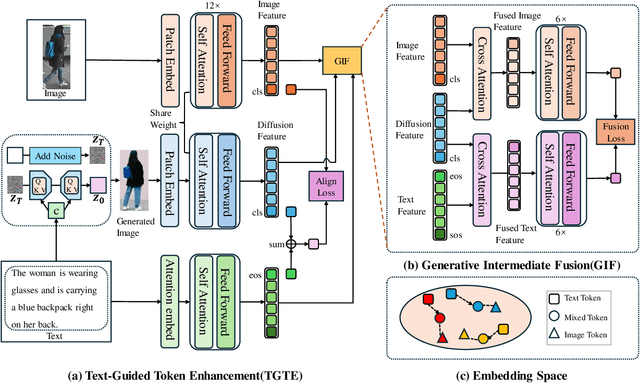
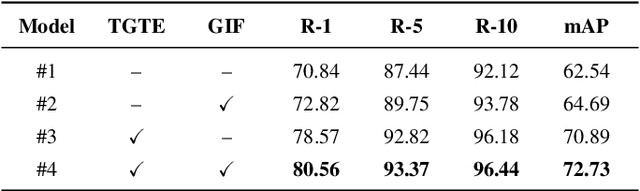
Text-to-Image Person Retrieval (TIPR) aims to retrieve person images based on natural language descriptions. Although many TIPR methods have achieved promising results, sometimes textual queries cannot accurately and comprehensively reflect the content of the image, leading to poor cross-modal alignment and overfitting to limited datasets. Moreover, the inherent modality gap between text and image further amplifies these issues, making accurate cross-modal retrieval even more challenging. To address these limitations, we propose the Generation-Enhanced Alignment (GEA) from a generative perspective. GEA contains two parallel modules: (1) Text-Guided Token Enhancement (TGTE), which introduces diffusion-generated images as intermediate semantic representations to bridge the gap between text and visual patterns. These generated images enrich the semantic representation of text and facilitate cross-modal alignment. (2) Generative Intermediate Fusion (GIF), which combines cross-attention between generated images, original images, and text features to generate a unified representation optimized by triplet alignment loss. We conduct extensive experiments on three public TIPR datasets, CUHK-PEDES, RSTPReid, and ICFG-PEDES, to evaluate the performance of GEA. The results justify the effectiveness of our method. More implementation details and extended results are available at https://github.com/sugelamyd123/Sup-for-GEA.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025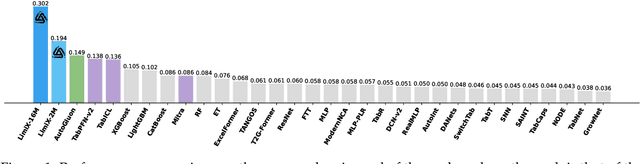
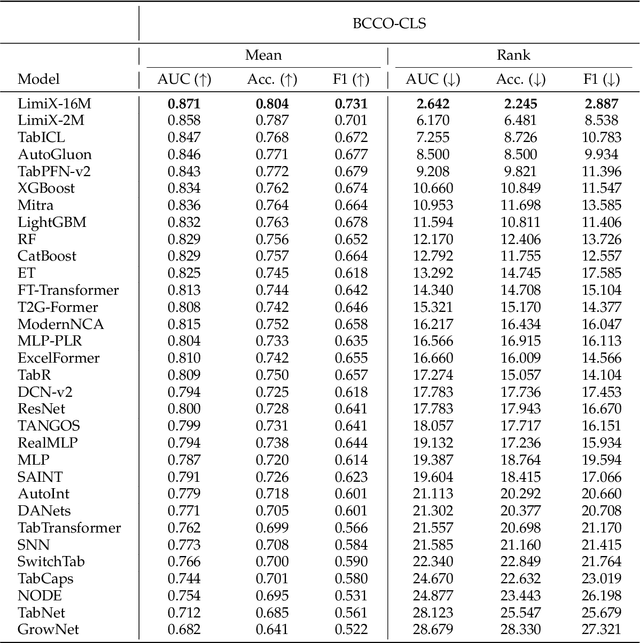
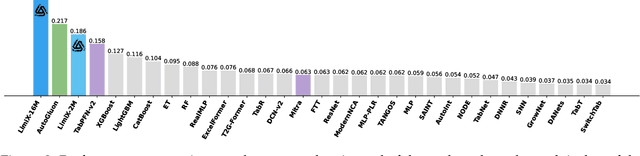
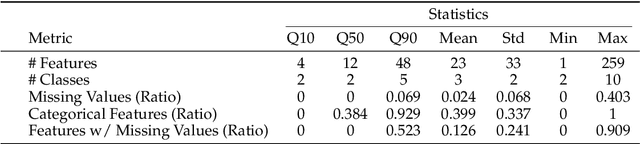
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
COUNTS: Benchmarking Object Detectors and Multimodal Large Language Models under Distribution Shifts
Apr 14, 2025Current object detectors often suffer significant perfor-mance degradation in real-world applications when encountering distributional shifts. Consequently, the out-of-distribution (OOD) generalization capability of object detectors has garnered increasing attention from researchers. Despite this growing interest, there remains a lack of a large-scale, comprehensive dataset and evaluation benchmark with fine-grained annotations tailored to assess the OOD generalization on more intricate tasks like object detection and grounding. To address this gap, we introduce COUNTS, a large-scale OOD dataset with object-level annotations. COUNTS encompasses 14 natural distributional shifts, over 222K samples, and more than 1,196K labeled bounding boxes. Leveraging COUNTS, we introduce two novel benchmarks: O(OD)2 and OODG. O(OD)2 is designed to comprehensively evaluate the OOD generalization capabilities of object detectors by utilizing controlled distribution shifts between training and testing data. OODG, on the other hand, aims to assess the OOD generalization of grounding abilities in multimodal large language models (MLLMs). Our findings reveal that, while large models and extensive pre-training data substantially en hance performance in in-distribution (IID) scenarios, significant limitations and opportunities for improvement persist in OOD contexts for both object detectors and MLLMs. In visual grounding tasks, even the advanced GPT-4o and Gemini-1.5 only achieve 56.7% and 28.0% accuracy, respectively. We hope COUNTS facilitates advancements in the development and assessment of robust object detectors and MLLMs capable of maintaining high performance under distributional shifts.
AirCache: Activating Inter-modal Relevancy KV Cache Compression for Efficient Large Vision-Language Model Inference
Mar 31, 2025Recent advancements in Large Visual Language Models (LVLMs) have gained significant attention due to their remarkable reasoning capabilities and proficiency in generalization. However, processing a large number of visual tokens and generating long-context outputs impose substantial computational overhead, leading to excessive demands for key-value (KV) cache. To address this critical bottleneck, we propose AirCache, a novel KV cache compression method aimed at accelerating LVLMs inference. This work systematically investigates the correlations between visual and textual tokens within the attention mechanisms of LVLMs. Our empirical analysis reveals considerable redundancy in cached visual tokens, wherein strategically eliminating these tokens preserves model performance while significantly accelerating context generation. Inspired by these findings, we introduce an elite observation window for assessing the importance of visual components in the KV cache, focusing on stable inter-modal relevancy modeling with enhanced multi-perspective consistency. Additionally, we develop an adaptive layer-wise budget allocation strategy that capitalizes on the strength and skewness of token importance distribution, showcasing superior efficiency compared to uniform allocation. Comprehensive evaluations across multiple LVLMs and benchmarks demonstrate that our method achieves comparable performance to the full cache while retaining only 10% of visual KV cache, thereby reducing decoding latency by 29% to 66% across various batch size and prompt length of inputs. Notably, as cache retention rates decrease, our method exhibits increasing performance advantages over existing approaches.
Understanding the Generalization of In-Context Learning in Transformers: An Empirical Study
Mar 19, 2025Large language models (LLMs) like GPT-4 and LLaMA-3 utilize the powerful in-context learning (ICL) capability of Transformer architecture to learn on the fly from limited examples. While ICL underpins many LLM applications, its full potential remains hindered by a limited understanding of its generalization boundaries and vulnerabilities. We present a systematic investigation of transformers' generalization capability with ICL relative to training data coverage by defining a task-centric framework along three dimensions: inter-problem, intra-problem, and intra-task generalization. Through extensive simulation and real-world experiments, encompassing tasks such as function fitting, API calling, and translation, we find that transformers lack inter-problem generalization with ICL, but excel in intra-task and intra-problem generalization. When the training data includes a greater variety of mixed tasks, it significantly enhances the generalization ability of ICL on unseen tasks and even on known simple tasks. This guides us in designing training data to maximize the diversity of tasks covered and to combine different tasks whenever possible, rather than solely focusing on the target task for testing.
Error Slice Discovery via Manifold Compactness
Jan 31, 2025



Despite the great performance of deep learning models in many areas, they still make mistakes and underperform on certain subsets of data, i.e. error slices. Given a trained model, it is important to identify its semantically coherent error slices that are easy to interpret, which is referred to as the error slice discovery problem. However, there is no proper metric of slice coherence without relying on extra information like predefined slice labels. Current evaluation of slice coherence requires access to predefined slices formulated by metadata like attributes or subclasses. Its validity heavily relies on the quality and abundance of metadata, where some possible patterns could be ignored. Besides, current algorithms cannot directly incorporate the constraint of coherence into their optimization objective due to the absence of an explicit coherence metric, which could potentially hinder their effectiveness. In this paper, we propose manifold compactness, a coherence metric without reliance on extra information by incorporating the data geometry property into its design, and experiments on typical datasets empirically validate the rationality of the metric. Then we develop Manifold Compactness based error Slice Discovery (MCSD), a novel algorithm that directly treats risk and coherence as the optimization objective, and is flexible to be applied to models of various tasks. Extensive experiments on the benchmark and case studies on other typical datasets demonstrate the superiority of MCSD.
Hidden Question Representations Tell Non-Factuality Within and Across Large Language Models
Jun 08, 2024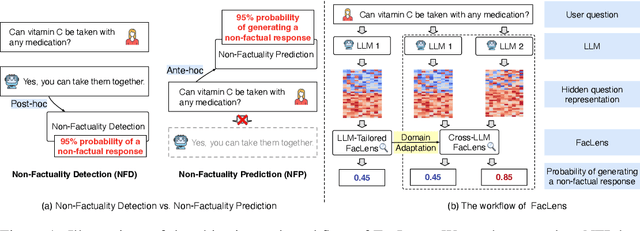
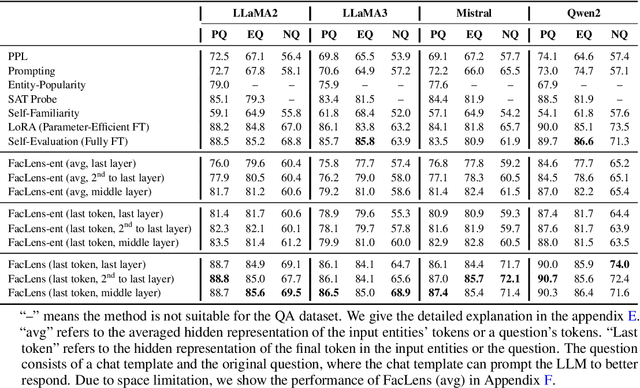
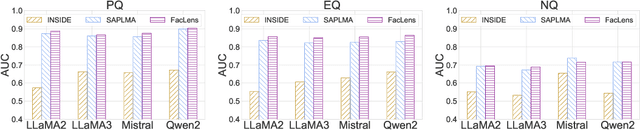
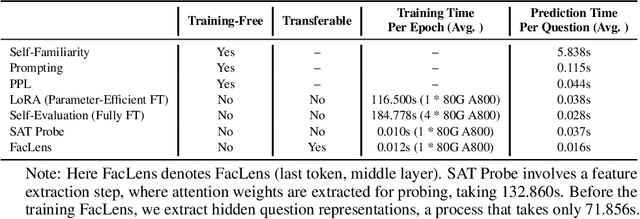
Despite the remarkable advance of large language models (LLMs), the prevalence of non-factual responses remains a common issue. This work studies non-factuality prediction (NFP), which predicts whether an LLM will generate non-factual responses to a question before the generation process. Previous efforts on NFP usually rely on extensive computation. In this work, we conduct extensive analysis to explore the capabilities of using a lightweight probe to elicit ``whether an LLM knows'' from the hidden representations of questions. Additionally, we discover that the non-factuality probe employs similar patterns for NFP across multiple LLMs. Motivated by the intriguing finding, we conduct effective transfer learning for cross-LLM NFP and propose a question-aligned strategy to ensure the efficacy of mini-batch based training.
Geometry-Calibrated DRO: Combating Over-Pessimism with Free Energy Implications
Nov 08, 2023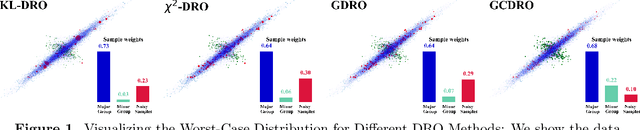
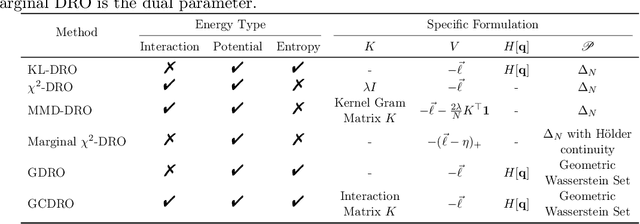
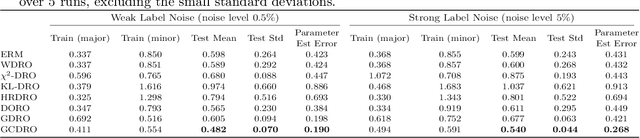
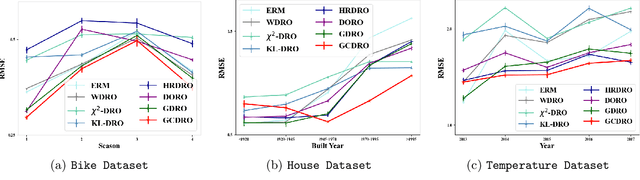
Machine learning algorithms minimizing average risk are susceptible to distributional shifts. Distributionally Robust Optimization (DRO) addresses this issue by optimizing the worst-case risk within an uncertainty set. However, DRO suffers from over-pessimism, leading to low-confidence predictions, poor parameter estimations as well as poor generalization. In this work, we conduct a theoretical analysis of a probable root cause of over-pessimism: excessive focus on noisy samples. To alleviate the impact of noise, we incorporate data geometry into calibration terms in DRO, resulting in our novel Geometry-Calibrated DRO (GCDRO) for regression. We establish the connection between our risk objective and the Helmholtz free energy in statistical physics, and this free-energy-based risk can extend to standard DRO methods. Leveraging gradient flow in Wasserstein space, we develop an approximate minimax optimization algorithm with a bounded error ratio and elucidate how our approach mitigates noisy sample effects. Comprehensive experiments confirm GCDRO's superiority over conventional DRO methods.