 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Amazing Agent Race: Strong Tool Users, Weak Navigators
Apr 11, 2026Existing tool-use benchmarks for LLM agents are overwhelmingly linear: our analysis of six benchmarks shows 55 to 100% of instances are simple chains of 2 to 5 steps. We introduce The Amazing Agent Race (AAR), a benchmark featuring directed acyclic graph (DAG) puzzles (or "legs") with fork-merge tool chains. We release 1,400 instances across two variants: sequential (800 legs) and compositional (600 DAG legs). Agents must navigate Wikipedia, execute multi-step tool chains, and aggregate results into a verifiable answer. Legs are procedurally generated from Wikipedia seeds across four difficulty levels with live-API validation. Three complementary metrics (finish-line accuracy, pit-stop visit rate, and roadblock completion rate) separately diagnose navigation, tool-use, and arithmetic failures. Evaluating three agent frameworks on 1,400 legs, the best achieves only 37.2% accuracy. Navigation errors dominate (27 to 52% of trials) while tool-use errors remain below 17%, and agent architecture matters as much as model scale (Claude Code matches Codex CLI at 37% with 6x fewer tokens). The compositional structure of AAR reveals that agents fail not at calling tools but at navigating to the right pages, a blind spot invisible to linear benchmarks. The project page can be accessed at: https://minnesotanlp.github.io/the-amazing-agent-race
Toward Evaluative Thinking: Meta Policy Optimization with Evolving Reward Models
Apr 28, 2025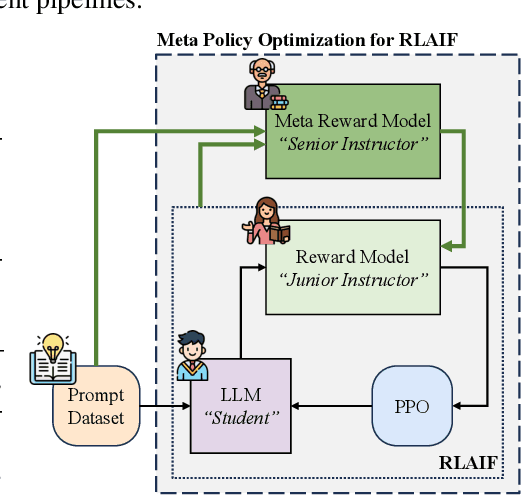


Reward-based alignment methods for large language models (LLMs) face two key limitations: vulnerability to reward hacking, where models exploit flaws in the reward signal; and reliance on brittle, labor-intensive prompt engineering when LLMs are used as reward models. We introduce Meta Policy Optimization (MPO), a framework that addresses these challenges by integrating a meta-reward model that dynamically refines the reward model's prompt throughout training. In MPO, the meta-reward model monitors the evolving training context and continuously adjusts the reward model's prompt to maintain high alignment, providing an adaptive reward signal that resists exploitation by the policy. This meta-learning approach promotes a more stable policy optimization, and greatly reduces the need for manual reward prompt design. It yields performance on par with or better than models guided by extensively hand-crafted reward prompts. Furthermore, we show that MPO maintains its effectiveness across diverse tasks, such as question answering and mathematical reasoning, without requiring specialized reward designs. Beyond standard RLAIF, MPO's meta-learning formulation is readily extensible to higher-level alignment frameworks. Overall, this method addresses theoretical and practical challenges in reward-based RL alignment for LLMs, paving the way for more robust and adaptable alignment strategies. The code and models will be publicly shared.
Align to Structure: Aligning Large Language Models with Structural Information
Apr 04, 2025Generating long, coherent text remains a challenge for large language models (LLMs), as they lack hierarchical planning and structured organization in discourse generation. We introduce Structural Alignment, a novel method that aligns LLMs with human-like discourse structures to enhance long-form text generation. By integrating linguistically grounded discourse frameworks into reinforcement learning, our approach guides models to produce coherent and well-organized outputs. We employ a dense reward scheme within a Proximal Policy Optimization framework, assigning fine-grained, token-level rewards based on the discourse distinctiveness relative to human writing. Two complementary reward models are evaluated: the first improves readability by scoring surface-level textual features to provide explicit structuring, while the second reinforces deeper coherence and rhetorical sophistication by analyzing global discourse patterns through hierarchical discourse motifs, outperforming both standard and RLHF-enhanced models in tasks such as essay generation and long-document summarization. All training data and code will be publicly shared at https://github.com/minnesotanlp/struct_align.
Anchors Aweigh! Sail for Optimal Unified Multi-Modal Representations
Oct 02, 2024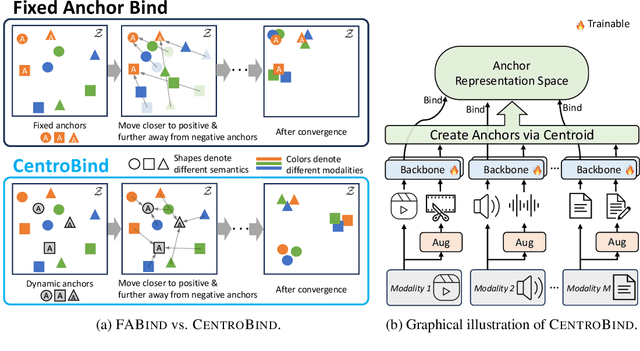
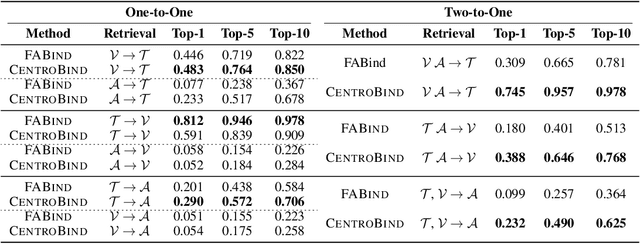
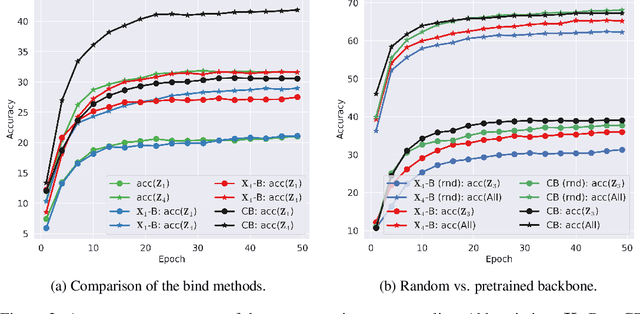
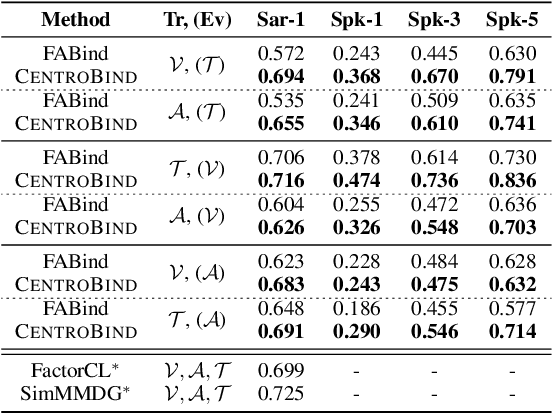
Multimodal learning plays a crucial role in enabling machine learning models to fuse and utilize diverse data sources, such as text, images, and audio, to support a variety of downstream tasks. A unified representation across various modalities is particularly important for improving efficiency and performance. Recent binding methods, such as ImageBind (Girdhar et al., 2023), typically use a fixed anchor modality to align multimodal data in the anchor modal embedding space. In this paper, we mathematically analyze the fixed anchor binding methods and uncover notable limitations: (1) over-reliance on the choice of the anchor modality, (2) failure to capture intra-modal information, and (3) failure to account for inter-modal correlation among non-anchored modalities. To address these limitations, we propose CentroBind, a simple yet powerful approach that eliminates the need for a fixed anchor; instead, it employs dynamically adjustable centroid-based anchors generated from all available modalities, resulting in a balanced and rich representation space. We theoretically demonstrate that our method captures three crucial properties of multimodal learning: intra-modal learning, inter-modal learning, and multimodal alignment, while also constructing a robust unified representation across all modalities. Our experiments on both synthetic and real-world datasets demonstrate the superiority of the proposed method, showing that dynamic anchor methods outperform all fixed anchor binding methods as the former captures more nuanced multimodal interactions.
Human-AI Collaborative Taxonomy Construction: A Case Study in Profession-Specific Writing Assistants
Jun 26, 2024Large Language Models (LLMs) have assisted humans in several writing tasks, including text revision and story generation. However, their effectiveness in supporting domain-specific writing, particularly in business contexts, is relatively less explored. Our formative study with industry professionals revealed the limitations in current LLMs' understanding of the nuances in such domain-specific writing. To address this gap, we propose an approach of human-AI collaborative taxonomy development to perform as a guideline for domain-specific writing assistants. This method integrates iterative feedback from domain experts and multiple interactions between these experts and LLMs to refine the taxonomy. Through larger-scale experiments, we aim to validate this methodology and thus improve LLM-powered writing assistance, tailoring it to meet the unique requirements of different stakeholder needs.
Threads of Subtlety: Detecting Machine-Generated Texts Through Discourse Motifs
Feb 16, 2024With the advent of large language models (LLM), the line between human-crafted and machine-generated texts has become increasingly blurred. This paper delves into the inquiry of identifying discernible and unique linguistic properties in texts that were written by humans, particularly uncovering the underlying discourse structures of texts beyond their surface structures. Introducing a novel methodology, we leverage hierarchical parse trees and recursive hypergraphs to unveil distinctive discourse patterns in texts produced by both LLMs and humans. Empirical findings demonstrate that, although both LLMs and humans generate distinct discourse patterns influenced by specific domains, human-written texts exhibit more structural variability, reflecting the nuanced nature of human writing in different domains. Notably, incorporating hierarchical discourse features enhances binary classifiers' overall performance in distinguishing between human-written and machine-generated texts, even on out-of-distribution and paraphrased samples. This underscores the significance of incorporating hierarchical discourse features in the analysis of text patterns. The code and dataset will be available at [TBA].
Under the Surface: Tracking the Artifactuality of LLM-Generated Data
Jan 30, 2024



This work delves into the expanding role of large language models (LLMs) in generating artificial data. LLMs are increasingly employed to create a variety of outputs, including annotations, preferences, instruction prompts, simulated dialogues, and free text. As these forms of LLM-generated data often intersect in their application, they exert mutual influence on each other and raise significant concerns about the quality and diversity of the artificial data incorporated into training cycles, leading to an artificial data ecosystem. To the best of our knowledge, this is the first study to aggregate various types of LLM-generated text data, from more tightly constrained data like "task labels" to more lightly constrained "free-form text". We then stress test the quality and implications of LLM-generated artificial data, comparing it with human data across various existing benchmarks. Despite artificial data's capability to match human performance, this paper reveals significant hidden disparities, especially in complex tasks where LLMs often miss the nuanced understanding of intrinsic human-generated content. This study critically examines diverse LLM-generated data and emphasizes the need for ethical practices in data creation and when using LLMs. It highlights the LLMs' shortcomings in replicating human traits and behaviors, underscoring the importance of addressing biases and artifacts produced in LLM-generated content for future research and development. All data and code are available on our project page.
Benchmarking Cognitive Biases in Large Language Models as Evaluators
Sep 29, 2023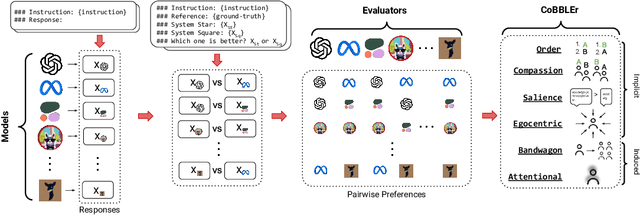



Large Language Models (LLMs) have recently been shown to be effective as automatic evaluators with simple prompting and in-context learning. In this work, we assemble 15 LLMs of four different size ranges and evaluate their output responses by preference ranking from the other LLMs as evaluators, such as System Star is better than System Square. We then evaluate the quality of ranking outputs introducing the Cognitive Bias Benchmark for LLMs as Evaluators (CoBBLEr), a benchmark to measure six different cognitive biases in LLM evaluation outputs, such as the Egocentric bias where a model prefers to rank its own outputs highly in evaluation. We find that LLMs are biased text quality evaluators, exhibiting strong indications on our bias benchmark (average of 40% of comparisons across all models) within each of their evaluations that question their robustness as evaluators. Furthermore, we examine the correlation between human and machine preferences and calculate the average Rank-Biased Overlap (RBO) score to be 49.6%, indicating that machine preferences are misaligned with humans. According to our findings, LLMs may still be unable to be utilized for automatic annotation aligned with human preferences. Our project page is at: https://minnesotanlp.github.io/cobbler.
An Analysis of Reader Engagement in Literary Fiction through Eye Tracking and Linguistic Features
Jun 06, 2023Capturing readers' engagement in fiction is a challenging but important aspect of narrative understanding. In this study, we collected 23 readers' reactions to 2 short stories through eye tracking, sentence-level annotations, and an overall engagement scale survey. We analyzed the significance of various qualities of the text in predicting how engaging a reader is likely to find it. As enjoyment of fiction is highly contextual, we also investigated individual differences in our data. Furthering our understanding of what captivates readers in fiction will help better inform models used in creative narrative generation and collaborative writing tools.
Diffusion Models in NLP: A Survey
May 24, 2023This survey paper provides a comprehensive review of the use of diffusion models in natural language processing (NLP). Diffusion models are a class of mathematical models that aim to capture the diffusion of information or signals across a network or manifold. In NLP, diffusion models have been used in a variety of applications, such as natural language generation, sentiment analysis, topic modeling, and machine translation. This paper discusses the different formulations of diffusion models used in NLP, their strengths and limitations, and their applications. We also perform a thorough comparison between diffusion models and alternative generative models, specifically highlighting the autoregressive (AR) models, while also examining how diverse architectures incorporate the Transformer in conjunction with diffusion models. Compared to AR models, diffusion models have significant advantages for parallel generation, text interpolation, token-level controls such as syntactic structures and semantic contents, and robustness. Exploring further permutations of integrating Transformers into diffusion models would be a valuable pursuit. Also, the development of multimodal diffusion models and large-scale diffusion language models with notable capabilities for few-shot learning would be important directions for the future advance of diffusion models in NLP.