 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThreads of Subtlety: Detecting Machine-Generated Texts Through Discourse Motifs
Feb 16, 2024With the advent of large language models (LLM), the line between human-crafted and machine-generated texts has become increasingly blurred. This paper delves into the inquiry of identifying discernible and unique linguistic properties in texts that were written by humans, particularly uncovering the underlying discourse structures of texts beyond their surface structures. Introducing a novel methodology, we leverage hierarchical parse trees and recursive hypergraphs to unveil distinctive discourse patterns in texts produced by both LLMs and humans. Empirical findings demonstrate that, although both LLMs and humans generate distinct discourse patterns influenced by specific domains, human-written texts exhibit more structural variability, reflecting the nuanced nature of human writing in different domains. Notably, incorporating hierarchical discourse features enhances binary classifiers' overall performance in distinguishing between human-written and machine-generated texts, even on out-of-distribution and paraphrased samples. This underscores the significance of incorporating hierarchical discourse features in the analysis of text patterns. The code and dataset will be available at [TBA].
LFI-CAM: Learning Feature Importance for Better Visual Explanation
May 03, 2021



Class Activation Mapping (CAM) is a powerful technique used to understand the decision making of Convolutional Neural Network (CNN) in computer vision. Recently, there have been attempts not only to generate better visual explanations, but also to improve classification performance using visual explanations. However, the previous works still have their own drawbacks. In this paper, we propose a novel architecture, LFI-CAM, which is trainable for image classification and visual explanation in an end-to-end manner. LFI-CAM generates an attention map for visual explanation during forward propagation, at the same time, leverages the attention map to improve the classification performance through the attention mechanism. Our Feature Importance Network (FIN) focuses on learning the feature importance instead of directly learning the attention map to obtain a more reliable and consistent attention map. We confirmed that LFI-CAM model is optimized not only by learning the feature importance but also by enhancing the backbone feature representation to focus more on important features of the input image. Experimental results show that LFI-CAM outperforms the baseline models's accuracy on the classification tasks as well as significantly improves on the previous works in terms of attention map quality and stability over different hyper-parameters.
Unsupervised Image-to-Image Translation with Self-Attention Networks
Jan 24, 2019



Unsupervised image translation aims to learn the transformation from a source domain to another target domain given unpaired training data. Several state-of-the-art works have yielded impressive results in the GANs-based unsupervised image-to-image translation. It fails to capture strong geometric or structural change between domains or is unsatisfactory for complex scenes, compared to texture change tasks such as style transfer. Recently, SAGAN (Han Zhang, 2018) showed that the self-attention network produces better results than the convolution-based GAN. However, the effectiveness of the self-attention network in unsupervised image-to-image translation tasks have not been verified. In this paper, we propose an unsupervised image-to-image translation with self-attention networks, in which long range dependency helps to not only capture strong geometric change but also generate details using cues from all feature locations. In experiments, we qualitatively and quantitatively show superiority of the proposed method compared to existing state-of-the-art unsupervised image-to-image translation task.
Arbitrary Style Transfer with Style-Attentional Networks
Jan 03, 2019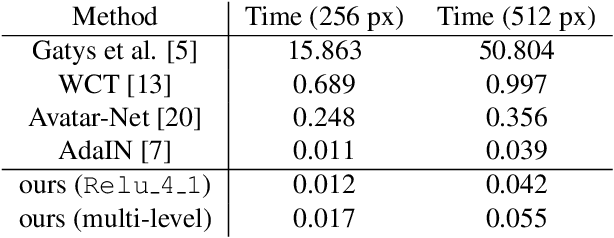
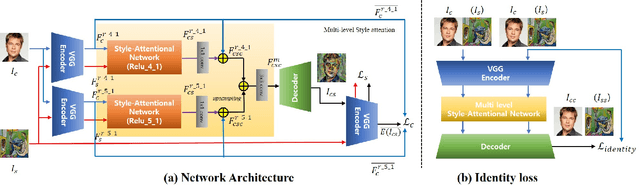
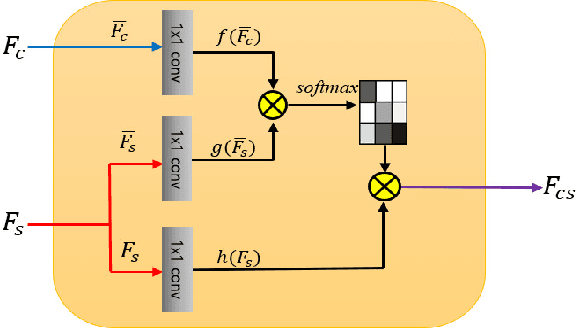
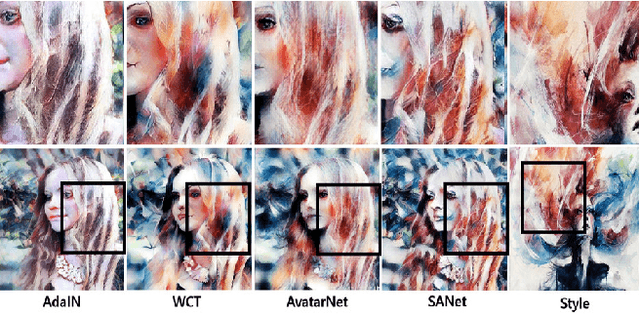
Arbitrary style transfer aims to synthesize a content image with style of an image that has never been seen before. Recent arbitrary style transfer algorithms have trade-off between the content structure and the style patterns, or maintaining the global and local style patterns at the same time is difficult due to the patch-based mechanism. In this paper, we introduce a novel style-attentional network (SANet), which efficiently and flexibly decorates the local style patterns according to the semantic spatial distribution of the content image. A new identity loss function and a multi-level features embedding also make our SANet and decoder preserve the content structure as much as possible while enriching the style patterns. Experimental results demonstrate that our algorithm synthesizes higher-quality stylized images in real-time than the state-of-the-art-algorithms.
Deterministic Hypothesis Generation for Robust Fitting of Multiple Structures
Jul 25, 2018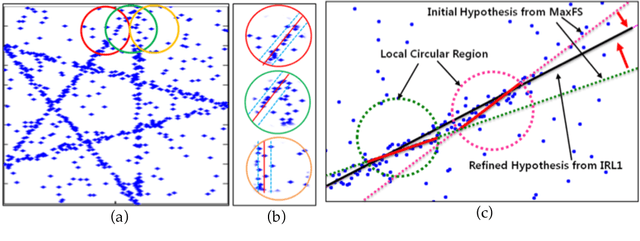
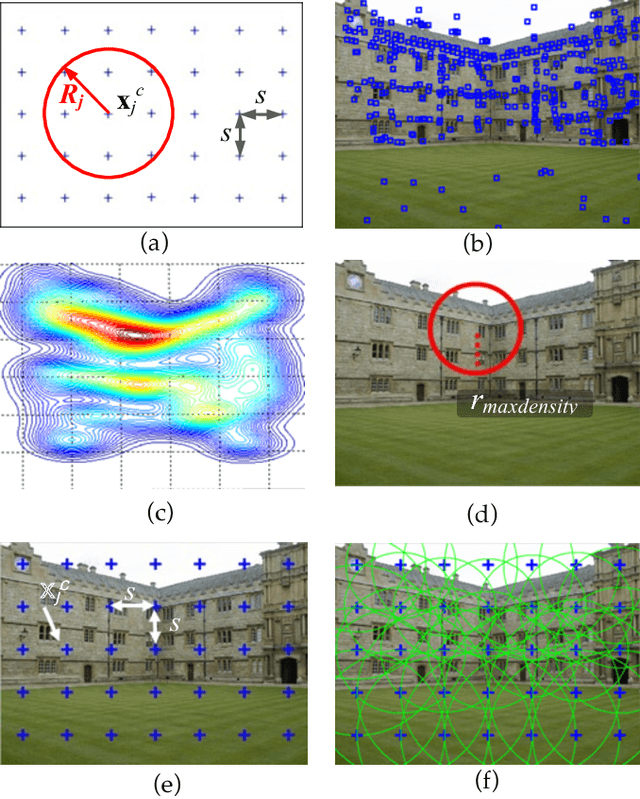
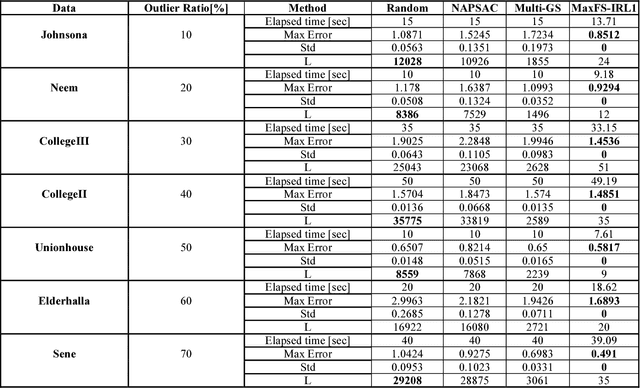
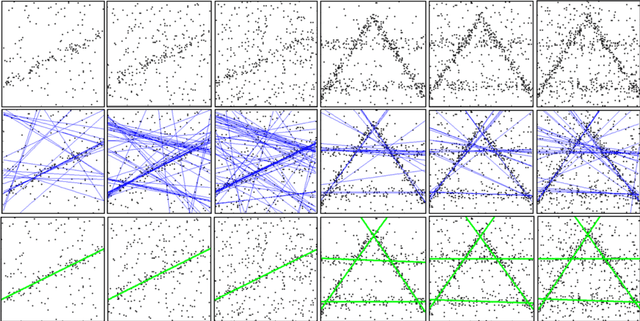
We present a novel algorithm for generating robust and consistent hypotheses for multiple-structure model fitting. Most of the existing methods utilize random sampling which produce varying results especially when outlier ratio is high. For a structure where a model is fitted, the inliers of other structures are regarded as outliers when multiple structures are present. Global optimization has recently been investigated to provide stable and unique solutions, but the computational cost of the algorithms is prohibitively high for most image data with reasonable sizes. The algorithm presented in this paper uses a maximum feasible subsystem (MaxFS) algorithm to generate consistent initial hypotheses only from partial datasets in spatially overlapping local image regions. Our assumption is that each genuine structure will exist as a dominant structure in at least one of the local regions. To refine initial hypotheses estimated from partial datasets and to remove residual tolerance dependency of the MaxFS algorithm, iterative re-weighted L1 (IRL1) minimization is performed for all the image data. Initial weights of IRL1 framework are determined from the initial hypotheses generated in local regions. Our approach is significantly more efficient than those that use only global optimization for all the image data. Experimental results demonstrate that the presented method can generate more reliable and consistent hypotheses than random-sampling methods for estimating single and multiple structures from data with a large amount of outliers. We clearly expose the influence of algorithm parameter settings on the results in our experiments.
Deterministic Fitting of Multiple Structures using Iterative MaxFS with Inlier Scale Estimation and Subset Updating
Jul 24, 2018
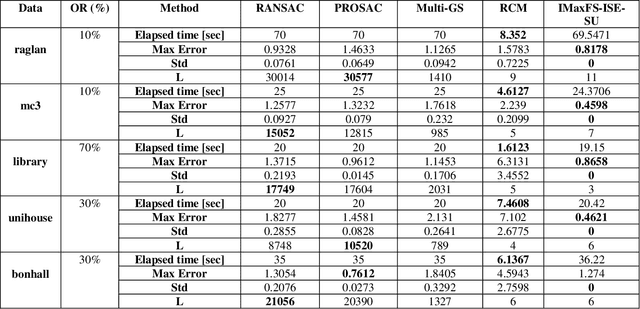
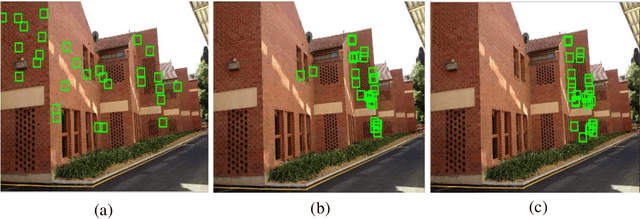
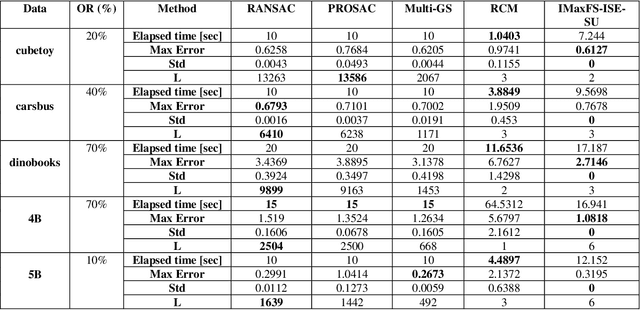
We present an efficient deterministic hypothesis generation algorithm for robust fitting of multiple structures based on the maximum feasible subsystem (MaxFS) framework. Despite its advantage, a global optimization method such as MaxFS has two main limitations for geometric model fitting. First, its performance is much influenced by the user-specified inlier scale. Second, it is computationally inefficient for large data. The presented MaxFS-based algorithm iteratively estimates model parameters and inlier scale and also overcomes the second limitation by reducing data for the MaxFS problem. Further it generates hypotheses only with top-n ranked subsets based on matching scores and data fitting residuals. This reduction of data for the MaxFS problem makes the algorithm computationally realistic. Our method, called iterative MaxFS with inlier scale estimation and subset updating (IMaxFS-ISE-SU) in this paper, performs hypothesis generation and fitting alternately until all of true structures are found. The IMaxFS-ISE-SU algorithm generates substantially more reliable hypotheses than random sampling-based methods especially as (pseudo-)outlier ratios increase. Experimental results demonstrate that our method can generate more reliable and consistent hypotheses than random sampling-based methods for estimating multiple structures from data with many outliers.
2-gram-based Phonetic Feature Generation for Convolutional Neural Network in Assessment of Trademark Similarity
Feb 10, 2018



A trademark is a mark used to identify various commodities. If same or similar trademark is registered for the same or similar commodity, the purchaser of the goods may be confused. Therefore, in the process of trademark registration examination, the examiner judges whether the trademark is the same or similar to the other applied or registered trademarks. The confusion in trademarks is based on the visual, phonetic or conceptual similarity of the marks. In this paper, we focus specifically on the phonetic similarity between trademarks. We propose a method to generate 2D phonetic feature for convolutional neural network in assessment of trademark similarity. This proposed algorithm is tested with 12,553 trademark phonetic similar pairs and 34,020 trademark phonetic non-similar pairs from 2010 to 2016. As a result, we have obtained approximately 92% judgment accuracy.
Color-Stripe Structured Light Robust to Surface Color and Discontinuity
Sep 18, 2015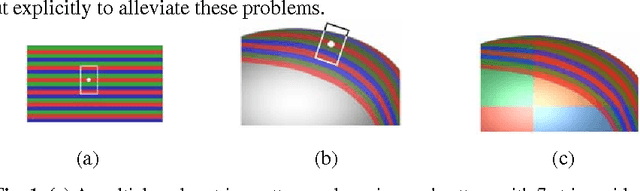


Multiple color stripes have been employed for structured light-based rapid range imaging to increase the number of uniquely identifiable stripes. The use of multiple color stripes poses two problems: (1) object surface color may disturb the stripe color and (2) the number of adjacent stripes required for identifying a stripe may not be maintained near surface discontinuities such as occluding boundaries. In this paper, we present methods to alleviate those problems. Log-gradient filters are employed to reduce the influence of object colors, and color stripes in two and three directions are used to increase the chance of identifying correct stripes near surface discontinuities. Experimental results demonstrate the effectiveness of our methods.
* 10 pages, 9 figures, 8th Asian Conference on Computer Vision (ACCV), Tokyo, Japan, November 2007, Proceedings, Part II
Multi-Projector Color Structured-Light Vision
Aug 31, 2015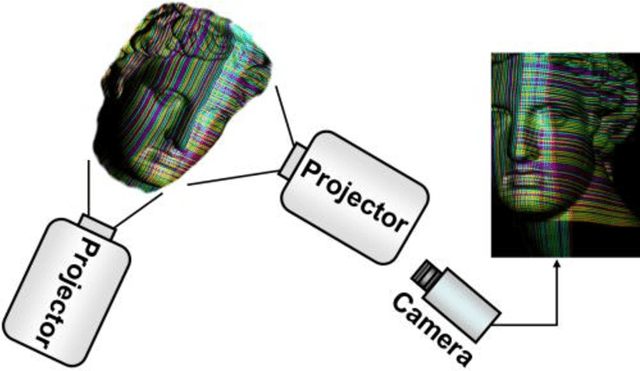
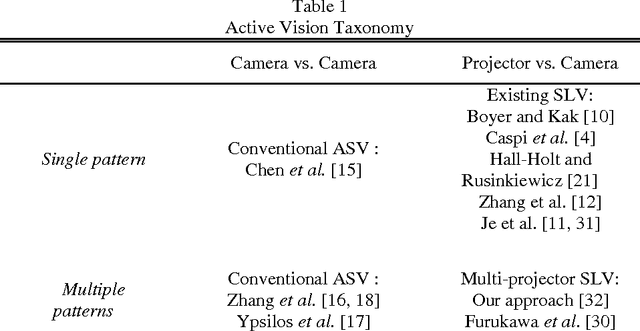
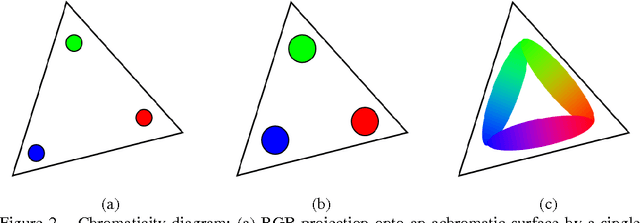
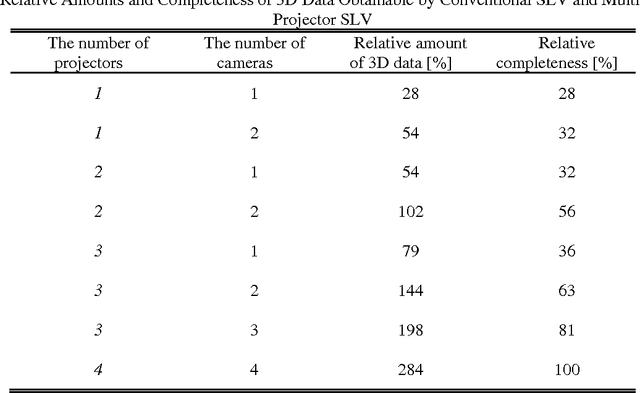
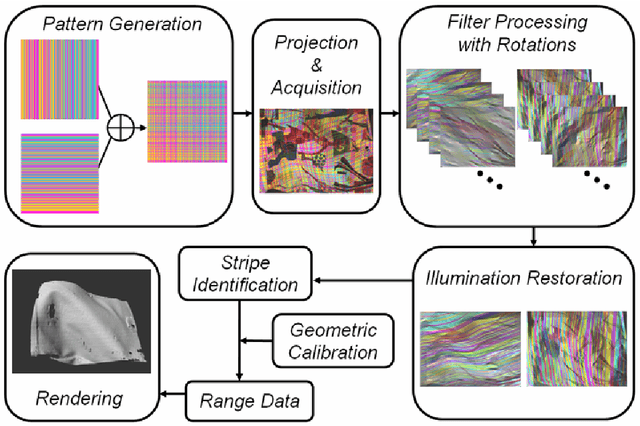
Research interest in rapid structured-light imaging has grown increasingly for the modeling of moving objects, and a number of methods have been suggested for the range capture in a single video frame. The imaging area of a 3D object using a single projector is restricted since the structured light is projected only onto a limited area of the object surface. Employing additional projectors to broaden the imaging area is a challenging problem since simultaneous projection of multiple patterns results in their superposition in the light-intersected areas and the recognition of original patterns is by no means trivial. This paper presents a novel method of multi-projector color structured-light vision based on projector-camera triangulation. By analyzing the behavior of superposed-light colors in a chromaticity domain, we show that the original light colors cannot be properly extracted by the conventional direct estimation. We disambiguate multiple projectors by multiplexing the orientations of projector patterns so that the superposed patterns can be separated by explicit derivative computations. Experimental studies are carried out to demonstrate the validity of the presented method. The proposed method increases the efficiency of range acquisition compared to conventional active stereo using multiple projectors.
* 25 pages, 13 figures