 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAID: A Benchmark for Bias Assessment of AI Detectors
Dec 12, 2025AI-generated text detectors have recently gained adoption in educational and professional contexts. Prior research has uncovered isolated cases of bias, particularly against English Language Learners (ELLs) however, there is a lack of systematic evaluation of such systems across broader sociolinguistic factors. In this work, we propose BAID, a comprehensive evaluation framework for AI detectors across various types of biases. As a part of the framework, we introduce over 200k samples spanning 7 major categories: demographics, age, educational grade level, dialect, formality, political leaning, and topic. We also generated synthetic versions of each sample with carefully crafted prompts to preserve the original content while reflecting subgroup-specific writing styles. Using this, we evaluate four open-source state-of-the-art AI text detectors and find consistent disparities in detection performance, particularly low recall rates for texts from underrepresented groups. Our contributions provide a scalable, transparent approach for auditing AI detectors and emphasize the need for bias-aware evaluation before these tools are deployed for public use.
Are LLM Agents Behaviorally Coherent? Latent Profiles for Social Simulation
Sep 03, 2025The impressive capabilities of Large Language Models (LLMs) have fueled the notion that synthetic agents can serve as substitutes for real participants in human-subject research. In an effort to evaluate the merits of this claim, social science researchers have largely focused on whether LLM-generated survey data corresponds to that of a human counterpart whom the LLM is prompted to represent. In contrast, we address a more fundamental question: Do agents maintain internal consistency, retaining similar behaviors when examined under different experimental settings? To this end, we develop a study designed to (a) reveal the agent's internal state and (b) examine agent behavior in a basic dialogue setting. This design enables us to explore a set of behavioral hypotheses to assess whether an agent's conversation behavior is consistent with what we would expect from their revealed internal state. Our findings on these hypotheses show significant internal inconsistencies in LLMs across model families and at differing model sizes. Most importantly, we find that, although agents may generate responses matching those of their human counterparts, they fail to be internally consistent, representing a critical gap in their capabilities to accurately substitute for real participants in human-subject research. Our simulation code and data are publicly accessible.
Toward Evaluative Thinking: Meta Policy Optimization with Evolving Reward Models
Apr 28, 2025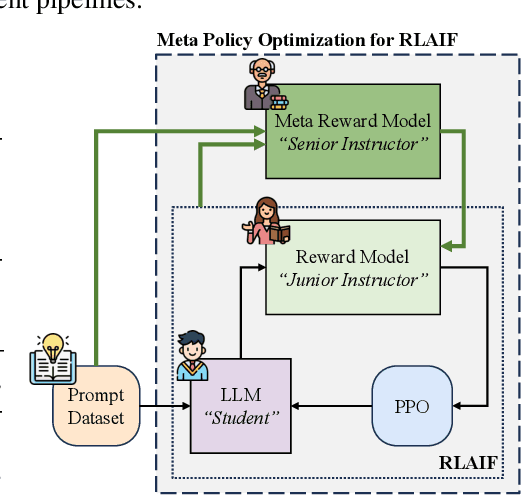

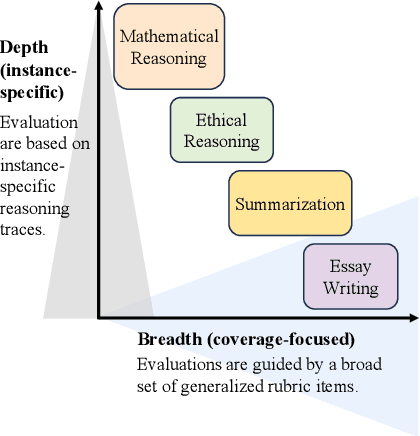

Reward-based alignment methods for large language models (LLMs) face two key limitations: vulnerability to reward hacking, where models exploit flaws in the reward signal; and reliance on brittle, labor-intensive prompt engineering when LLMs are used as reward models. We introduce Meta Policy Optimization (MPO), a framework that addresses these challenges by integrating a meta-reward model that dynamically refines the reward model's prompt throughout training. In MPO, the meta-reward model monitors the evolving training context and continuously adjusts the reward model's prompt to maintain high alignment, providing an adaptive reward signal that resists exploitation by the policy. This meta-learning approach promotes a more stable policy optimization, and greatly reduces the need for manual reward prompt design. It yields performance on par with or better than models guided by extensively hand-crafted reward prompts. Furthermore, we show that MPO maintains its effectiveness across diverse tasks, such as question answering and mathematical reasoning, without requiring specialized reward designs. Beyond standard RLAIF, MPO's meta-learning formulation is readily extensible to higher-level alignment frameworks. Overall, this method addresses theoretical and practical challenges in reward-based RL alignment for LLMs, paving the way for more robust and adaptable alignment strategies. The code and models will be publicly shared.
Learning Explainable Dense Reward Shapes via Bayesian Optimization
Apr 22, 2025Current reinforcement learning from human feedback (RLHF) pipelines for large language model (LLM) alignment typically assign scalar rewards to sequences, using the final token as a surrogate indicator for the quality of the entire sequence. However, this leads to sparse feedback and suboptimal token-level credit assignment. In this work, we frame reward shaping as an optimization problem focused on token-level credit assignment. We propose a reward-shaping function leveraging explainability methods such as SHAP and LIME to estimate per-token rewards from the reward model. To learn parameters of this shaping function, we employ a bilevel optimization framework that integrates Bayesian Optimization and policy training to handle noise from the token reward estimates. Our experiments show that achieving a better balance of token-level reward attribution leads to performance improvements over baselines on downstream tasks and finds an optimal policy faster during training. Furthermore, we show theoretically that explainability methods that are feature additive attribution functions maintain the optimal policy as the original reward.
Spivavtor: An Instruction Tuned Ukrainian Text Editing Model
Apr 29, 2024We introduce Spivavtor, a dataset, and instruction-tuned models for text editing focused on the Ukrainian language. Spivavtor is the Ukrainian-focused adaptation of the English-only CoEdIT model. Similar to CoEdIT, Spivavtor performs text editing tasks by following instructions in Ukrainian. This paper describes the details of the Spivavtor-Instruct dataset and Spivavtor models. We evaluate Spivavtor on a variety of text editing tasks in Ukrainian, such as Grammatical Error Correction (GEC), Text Simplification, Coherence, and Paraphrasing, and demonstrate its superior performance on all of them. We publicly release our best-performing models and data as resources to the community to advance further research in this space.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024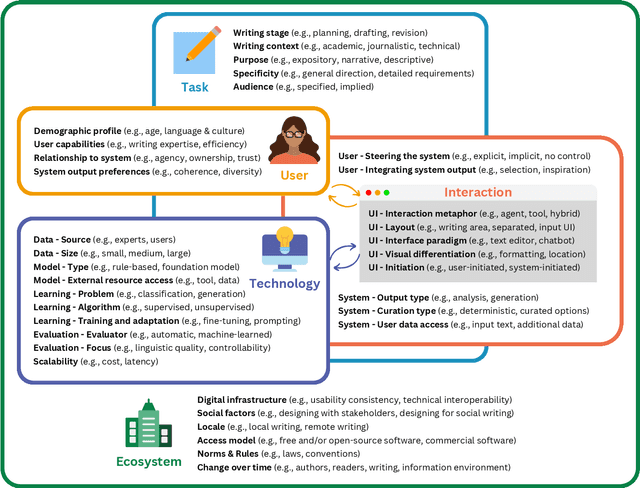
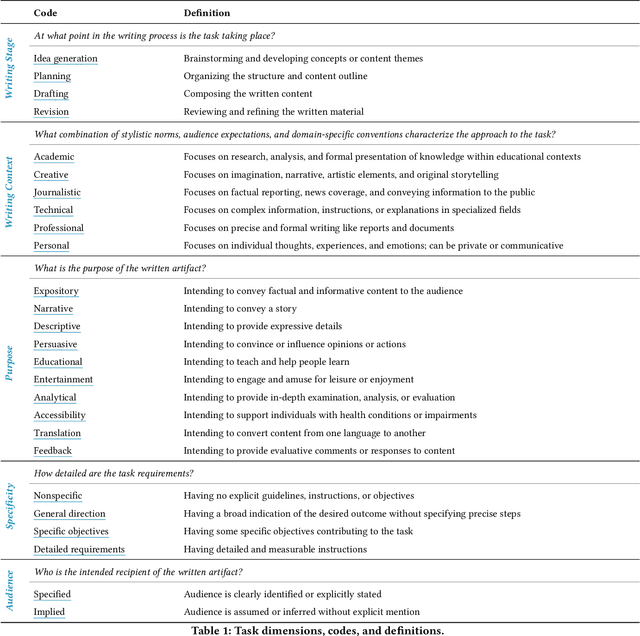
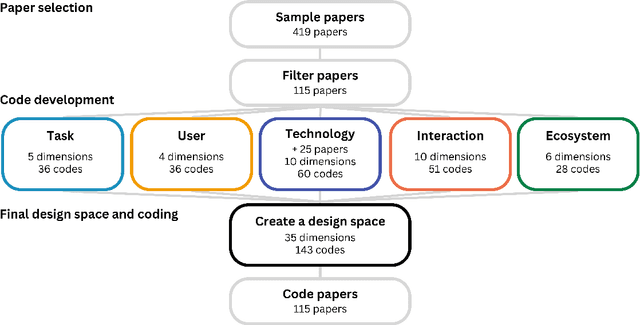
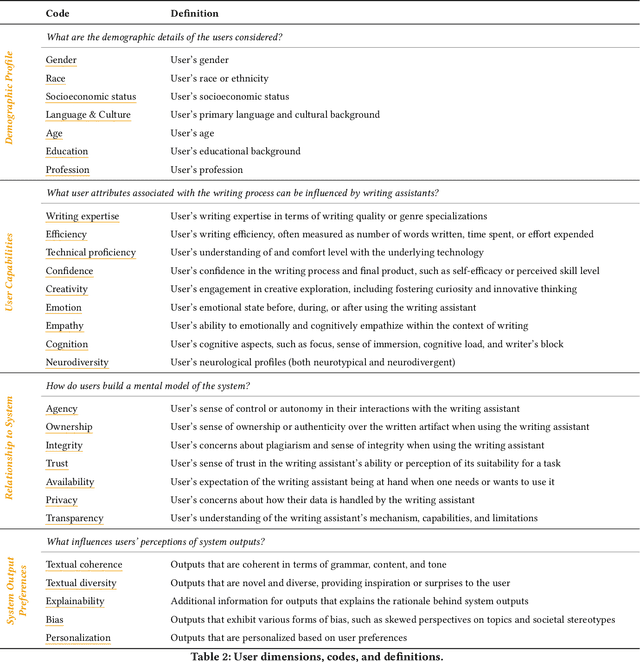
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
mEdIT: Multilingual Text Editing via Instruction Tuning
Feb 26, 2024We introduce mEdIT, a multi-lingual extension to CoEdIT -- the recent state-of-the-art text editing models for writing assistance. mEdIT models are trained by fine-tuning multi-lingual large, pre-trained language models (LLMs) via instruction tuning. They are designed to take instructions from the user specifying the attributes of the desired text in the form of natural language instructions, such as Grammatik korrigieren (German) or Parafrasee la oraci\'on (Spanish). We build mEdIT by curating data from multiple publicly available human-annotated text editing datasets for three text editing tasks (Grammatical Error Correction (GEC), Text Simplification, and Paraphrasing) across diverse languages belonging to six different language families. We detail the design and training of mEdIT models and demonstrate their strong performance on many multi-lingual text editing benchmarks against other multilingual LLMs. We also find that mEdIT generalizes effectively to new languages over multilingual baselines. We publicly release our data, code, and trained models at https://github.com/vipulraheja/medit.
Threads of Subtlety: Detecting Machine-Generated Texts Through Discourse Motifs
Feb 16, 2024With the advent of large language models (LLM), the line between human-crafted and machine-generated texts has become increasingly blurred. This paper delves into the inquiry of identifying discernible and unique linguistic properties in texts that were written by humans, particularly uncovering the underlying discourse structures of texts beyond their surface structures. Introducing a novel methodology, we leverage hierarchical parse trees and recursive hypergraphs to unveil distinctive discourse patterns in texts produced by both LLMs and humans. Empirical findings demonstrate that, although both LLMs and humans generate distinct discourse patterns influenced by specific domains, human-written texts exhibit more structural variability, reflecting the nuanced nature of human writing in different domains. Notably, incorporating hierarchical discourse features enhances binary classifiers' overall performance in distinguishing between human-written and machine-generated texts, even on out-of-distribution and paraphrased samples. This underscores the significance of incorporating hierarchical discourse features in the analysis of text patterns. The code and dataset will be available at [TBA].
Personalized Text Generation with Fine-Grained Linguistic Control
Feb 07, 2024



As the text generation capabilities of large language models become increasingly prominent, recent studies have focused on controlling particular aspects of the generated text to make it more personalized. However, most research on controllable text generation focuses on controlling the content or modeling specific high-level/coarse-grained attributes that reflect authors' writing styles, such as formality, domain, or sentiment. In this paper, we focus on controlling fine-grained attributes spanning multiple linguistic dimensions, such as lexical and syntactic attributes. We introduce a novel benchmark to train generative models and evaluate their ability to generate personalized text based on multiple fine-grained linguistic attributes. We systematically investigate the performance of various large language models on our benchmark and draw insights from the factors that impact their performance. We make our code, data, and pretrained models publicly available.
ContraDoc: Understanding Self-Contradictions in Documents with Large Language Models
Nov 15, 2023

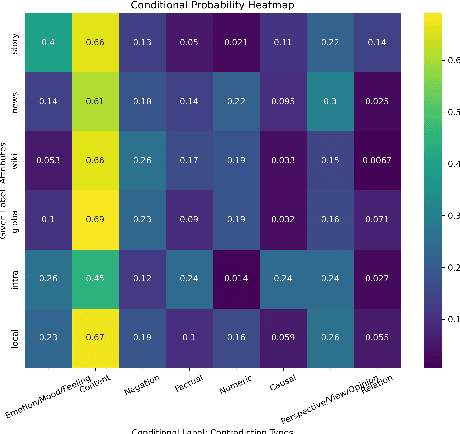

In recent times, large language models (LLMs) have shown impressive performance on various document-level tasks such as document classification, summarization, and question-answering. However, research on understanding their capabilities on the task of self-contradictions in long documents has been very limited. In this work, we introduce ContraDoc, the first human-annotated dataset to study self-contradictions in long documents across multiple domains, varying document lengths, self-contradictions types, and scope. We then analyze the current capabilities of four state-of-the-art open-source and commercially available LLMs: GPT3.5, GPT4, PaLM2, and LLaMAv2 on this dataset. While GPT4 performs the best and can outperform humans on this task, we find that it is still unreliable and struggles with self-contradictions that require more nuance and context. We release the dataset and all the code associated with the experiments.