 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakerly: A Voice-based Writing Assistant for Text Composition
Oct 24, 2023We present Speakerly, a new real-time voice-based writing assistance system that helps users with text composition across various use cases such as emails, instant messages, and notes. The user can interact with the system through instructions or dictation, and the system generates a well-formatted and coherent document. We describe the system architecture and detail how we address the various challenges while building and deploying such a system at scale. More specifically, our system uses a combination of small, task-specific models as well as pre-trained language models for fast and effective text composition while supporting a variety of input modes for better usability.
English Broadcast News Speech Recognition by Humans and Machines
Apr 30, 2019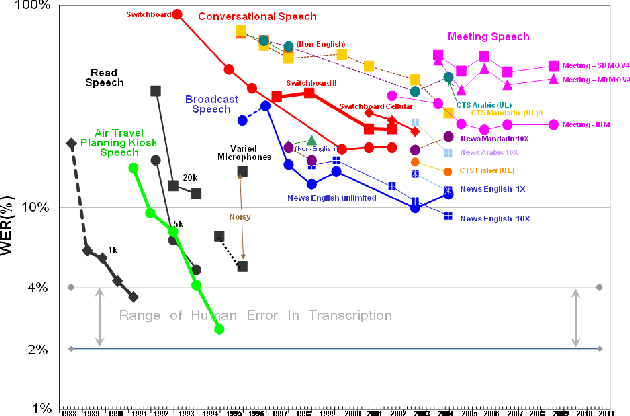
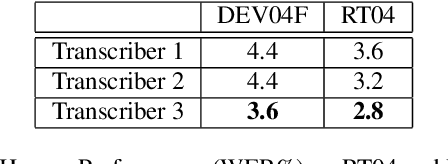


With recent advances in deep learning, considerable attention has been given to achieving automatic speech recognition performance close to human performance on tasks like conversational telephone speech (CTS) recognition. In this paper we evaluate the usefulness of these proposed techniques on broadcast news (BN), a similar challenging task. We also perform a set of recognition measurements to understand how close the achieved automatic speech recognition results are to human performance on this task. On two publicly available BN test sets, DEV04F and RT04, our speech recognition system using LSTM and residual network based acoustic models with a combination of n-gram and neural network language models performs at 6.5% and 5.9% word error rate. By achieving new performance milestones on these test sets, our experiments show that techniques developed on other related tasks, like CTS, can be transferred to achieve similar performance. In contrast, the best measured human recognition performance on these test sets is much lower, at 3.6% and 2.8% respectively, indicating that there is still room for new techniques and improvements in this space, to reach human performance levels.