 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Robust ASR Error Correction with Conservative Data Filtering
Jul 18, 2024
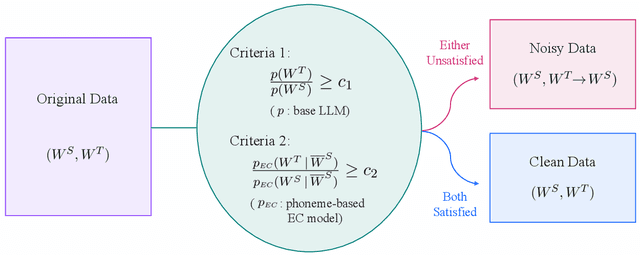

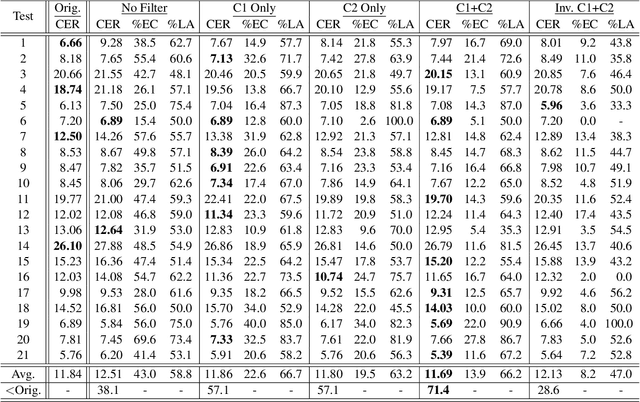
Error correction (EC) based on large language models is an emerging technology to enhance the performance of automatic speech recognition (ASR) systems. Generally, training data for EC are collected by automatically pairing a large set of ASR hypotheses (as sources) and their gold references (as targets). However, the quality of such pairs is not guaranteed, and we observed various types of noise which can make the EC models brittle, e.g. inducing overcorrection in out-of-domain (OOD) settings. In this work, we propose two fundamental criteria that EC training data should satisfy: namely, EC targets should (1) improve linguistic acceptability over sources and (2) be inferable from the available context (e.g. source phonemes). Through these criteria, we identify low-quality EC pairs and train the models not to make any correction in such cases, the process we refer to as conservative data filtering. In our experiments, we focus on Japanese ASR using a strong Conformer-CTC as the baseline and finetune Japanese LLMs for EC. Through our evaluation on a suite of 21 internal benchmarks, we demonstrate that our approach can significantly reduce overcorrection and improve both the accuracy and quality of ASR results in the challenging OOD settings.
Multiple Representation Transfer from Large Language Models to End-to-End ASR Systems
Sep 07, 2023



Transferring the knowledge of large language models (LLMs) is a promising technique to incorporate linguistic knowledge into end-to-end automatic speech recognition (ASR) systems. However, existing works only transfer a single representation of LLM (e.g. the last layer of pretrained BERT), while the representation of a text is inherently non-unique and can be obtained variously from different layers, contexts and models. In this work, we explore a wide range of techniques to obtain and transfer multiple representations of LLMs into a transducer-based ASR system. While being conceptually simple, we show that transferring multiple representations of LLMs can be an effective alternative to transferring only a single representation.
Effect and Analysis of Large-scale Language Model Rescoring on Competitive ASR Systems
Apr 01, 2022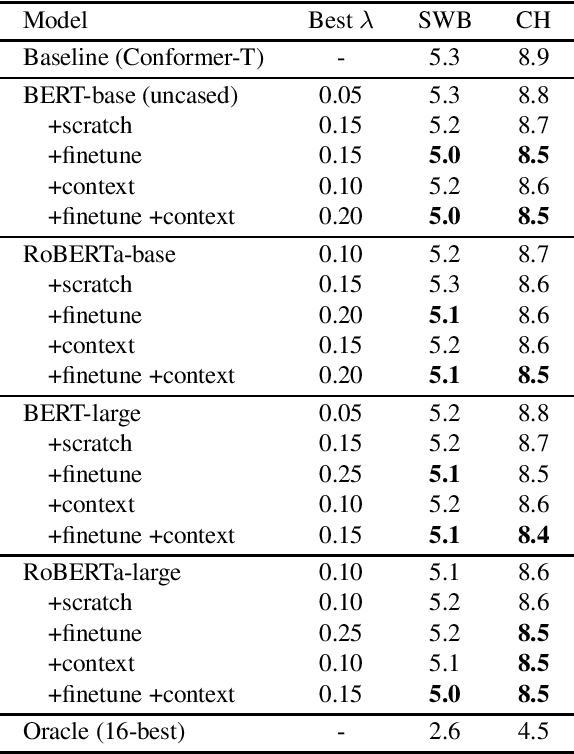
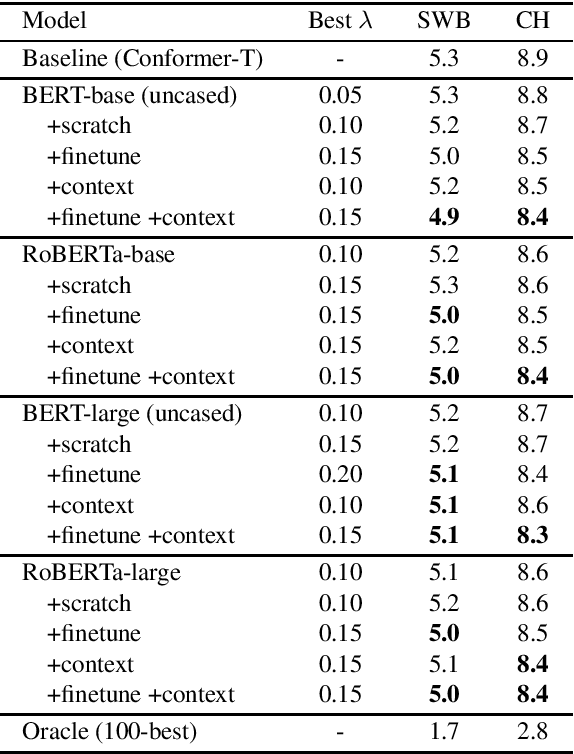
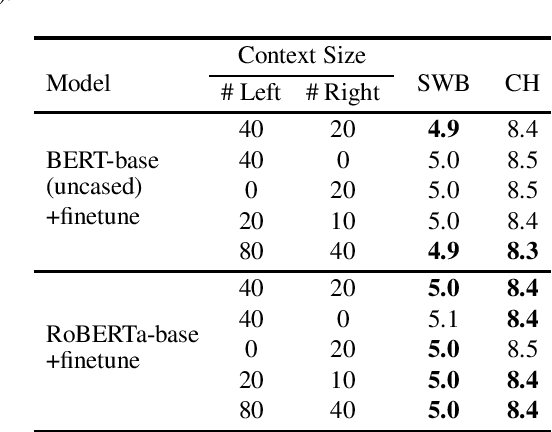
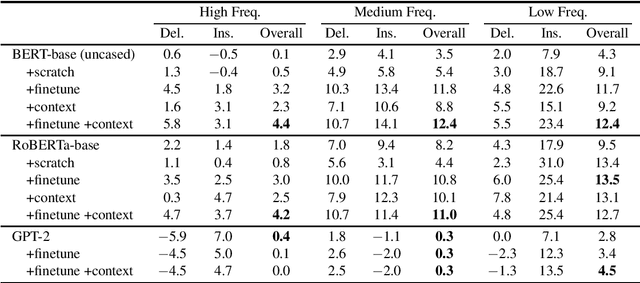
Large-scale language models (LLMs) such as GPT-2, BERT and RoBERTa have been successfully applied to ASR N-best rescoring. However, whether or how they can benefit competitive, near state-of-the-art ASR systems remains unexplored. In this study, we incorporate LLM rescoring into one of the most competitive ASR baselines: the Conformer-Transducer model. We demonstrate that consistent improvement is achieved by the LLM's bidirectionality, pretraining, in-domain finetuning and context augmentation. Furthermore, our lexical analysis sheds light on how each of these components may be contributing to the ASR performance.
Improving Generalization of Deep Neural Network Acoustic Models with Length Perturbation and N-best Based Label Smoothing
Mar 29, 2022
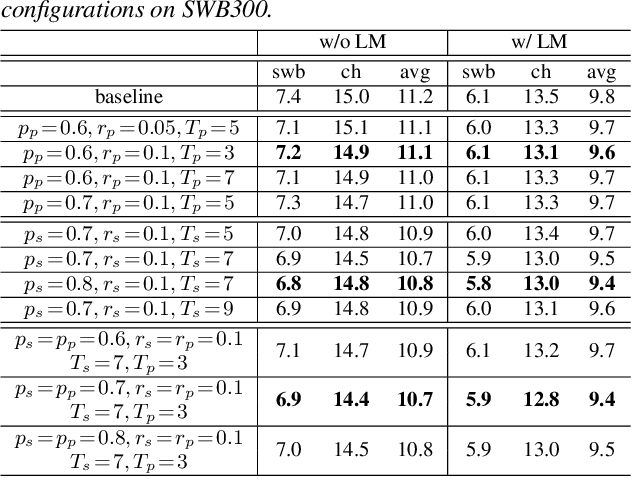
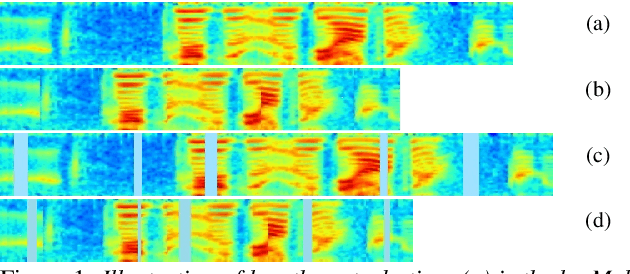
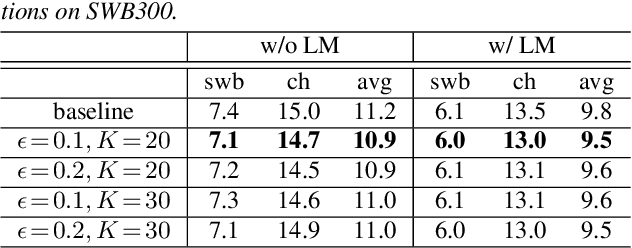
We introduce two techniques, length perturbation and n-best based label smoothing, to improve generalization of deep neural network (DNN) acoustic models for automatic speech recognition (ASR). Length perturbation is a data augmentation algorithm that randomly drops and inserts frames of an utterance to alter the length of the speech feature sequence. N-best based label smoothing randomly injects noise to ground truth labels during training in order to avoid overfitting, where the noisy labels are generated from n-best hypotheses. We evaluate these two techniques extensively on the 300-hour Switchboard (SWB300) dataset and an in-house 500-hour Japanese (JPN500) dataset using recurrent neural network transducer (RNNT) acoustic models for ASR. We show that both techniques improve the generalization of RNNT models individually and they can also be complementary. In particular, they yield good improvements over a strong SWB300 baseline and give state-of-art performance on SWB300 using RNNT models.
Knowledge Distillation Leveraging Alternative Soft Targets from Non-Parallel Qualified Speech Data
Dec 16, 2021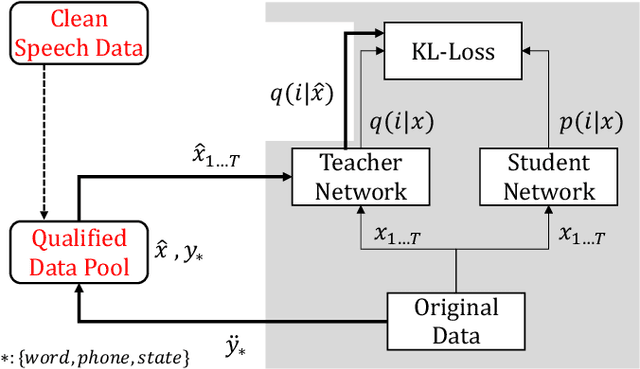
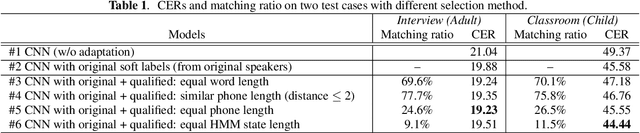
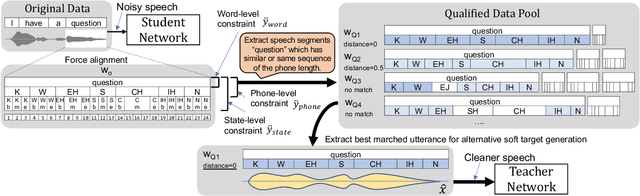
This paper describes a novel knowledge distillation framework that leverages acoustically qualified speech data included in an existing training data pool as privileged information. In our proposed framework, a student network is trained with multiple soft targets for each utterance that consist of main soft targets from original speakers' utterance and alternative targets from other speakers' utterances spoken under better acoustic conditions as a secondary view. These qualified utterances from other speakers, used to generate better soft targets, are collected from a qualified data pool by using strict constraints in terms of word/phone/state durations. Our proposed method is a form of target-side data augmentation that creates multiple copies of data with corresponding better soft targets obtained from a qualified data pool. We show in our experiments under acoustic model adaptation settings that the proposed method, exploiting better soft targets obtained from various speakers, can further improve recognition accuracy compared with conventional methods using only soft targets from original speakers.
RNN Transducer Models For Spoken Language Understanding
Apr 08, 2021
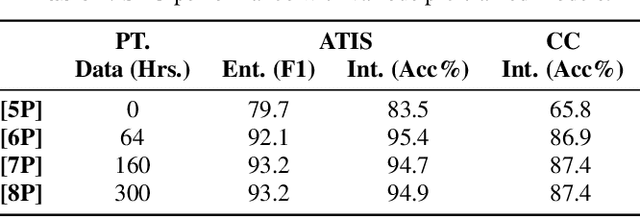


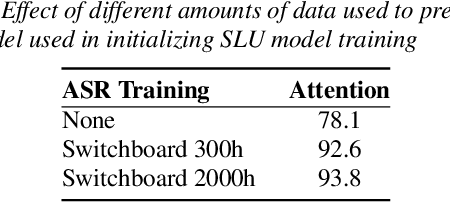
We present a comprehensive study on building and adapting RNN transducer (RNN-T) models for spoken language understanding(SLU). These end-to-end (E2E) models are constructed in three practical settings: a case where verbatim transcripts are available, a constrained case where the only available annotations are SLU labels and their values, and a more restrictive case where transcripts are available but not corresponding audio. We show how RNN-T SLU models can be developed starting from pre-trained automatic speech recognition (ASR) systems, followed by an SLU adaptation step. In settings where real audio data is not available, artificially synthesized speech is used to successfully adapt various SLU models. When evaluated on two SLU data sets, the ATIS corpus and a customer call center data set, the proposed models closely track the performance of other E2E models and achieve state-of-the-art results.
End-to-End Spoken Language Understanding Without Full Transcripts
Sep 30, 2020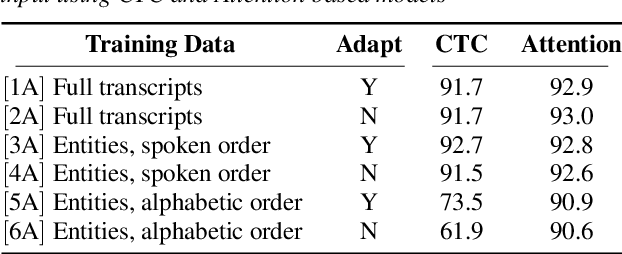
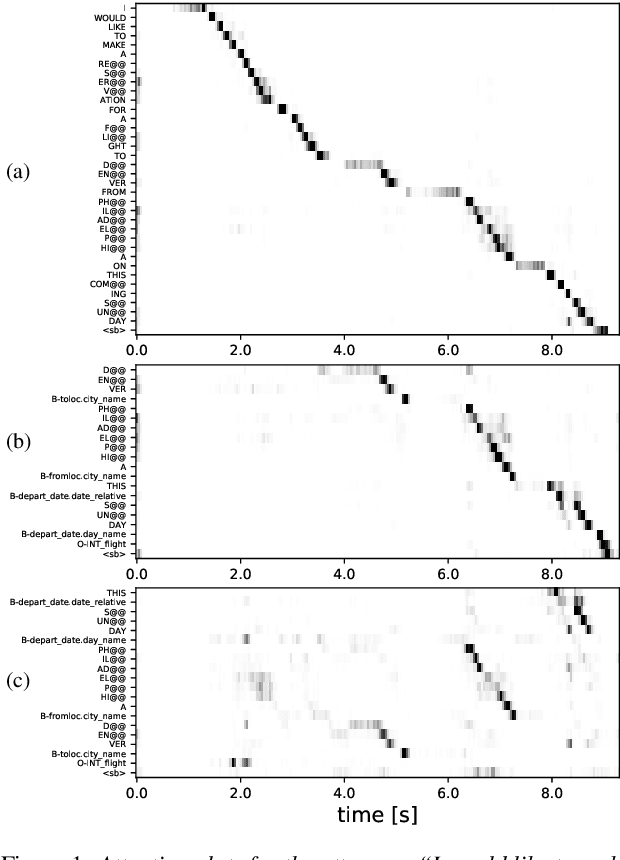

An essential component of spoken language understanding (SLU) is slot filling: representing the meaning of a spoken utterance using semantic entity labels. In this paper, we develop end-to-end (E2E) spoken language understanding systems that directly convert speech input to semantic entities and investigate if these E2E SLU models can be trained solely on semantic entity annotations without word-for-word transcripts. Training such models is very useful as they can drastically reduce the cost of data collection. We created two types of such speech-to-entities models, a CTC model and an attention-based encoder-decoder model, by adapting models trained originally for speech recognition. Given that our experiments involve speech input, these systems need to recognize both the entity label and words representing the entity value correctly. For our speech-to-entities experiments on the ATIS corpus, both the CTC and attention models showed impressive ability to skip non-entity words: there was little degradation when trained on just entities versus full transcripts. We also explored the scenario where the entities are in an order not necessarily related to spoken order in the utterance. With its ability to do re-ordering, the attention model did remarkably well, achieving only about 2% degradation in speech-to-bag-of-entities F1 score.
English Broadcast News Speech Recognition by Humans and Machines
Apr 30, 2019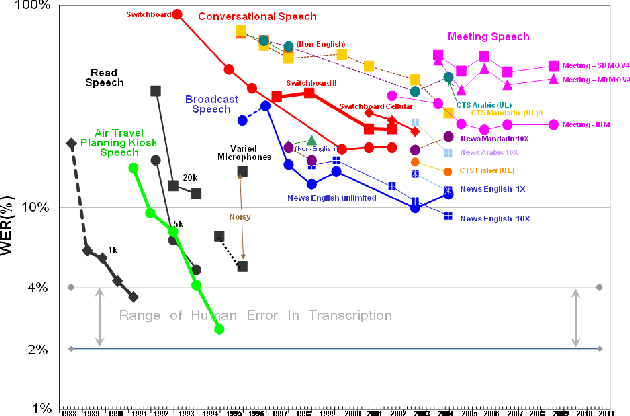
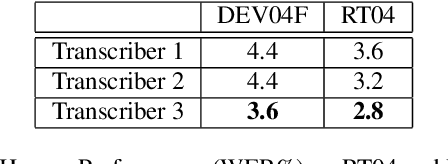


With recent advances in deep learning, considerable attention has been given to achieving automatic speech recognition performance close to human performance on tasks like conversational telephone speech (CTS) recognition. In this paper we evaluate the usefulness of these proposed techniques on broadcast news (BN), a similar challenging task. We also perform a set of recognition measurements to understand how close the achieved automatic speech recognition results are to human performance on this task. On two publicly available BN test sets, DEV04F and RT04, our speech recognition system using LSTM and residual network based acoustic models with a combination of n-gram and neural network language models performs at 6.5% and 5.9% word error rate. By achieving new performance milestones on these test sets, our experiments show that techniques developed on other related tasks, like CTS, can be transferred to achieve similar performance. In contrast, the best measured human recognition performance on these test sets is much lower, at 3.6% and 2.8% respectively, indicating that there is still room for new techniques and improvements in this space, to reach human performance levels.
Guiding CTC Posterior Spike Timings for Improved Posterior Fusion and Knowledge Distillation
Apr 17, 2019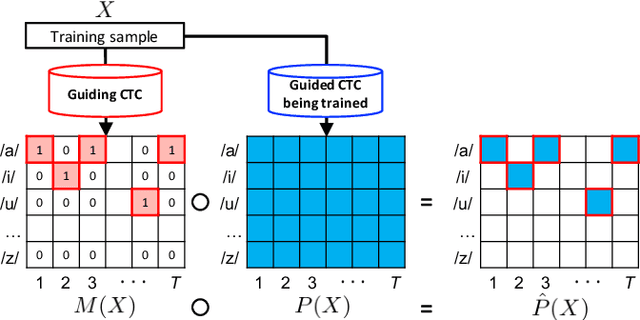

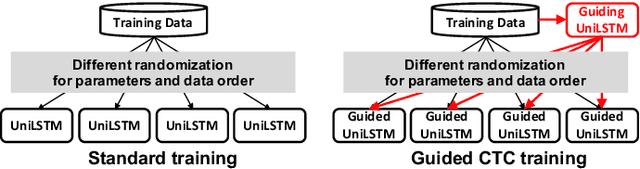

Conventional automatic speech recognition (ASR) systems trained from frame-level alignments can easily leverage posterior fusion to improve ASR accuracy and build a better single model with knowledge distillation. End-to-end ASR systems trained using the Connectionist Temporal Classification (CTC) loss do not require frame-level alignment and hence simplify model training. However, sparse and arbitrary posterior spike timings from CTC models pose a new set of challenges in posterior fusion from multiple models and knowledge distillation between CTC models. We propose a method to train a CTC model so that its spike timings are guided to align with those of a pre-trained guiding CTC model. As a result, all models that share the same guiding model have aligned spike timings. We show the advantage of our method in various scenarios including posterior fusion of CTC models and knowledge distillation between CTC models with different architectures. With the 300-hour Switchboard training data, the single word CTC model distilled from multiple models improved the word error rates to 13.7%/23.1% from 14.9%/24.1% on the Hub5 2000 Switchboard/CallHome test sets without using any data augmentation, language model, or complex decoder.