 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Joint Speech-Text Representations Without Alignment
Aug 11, 2023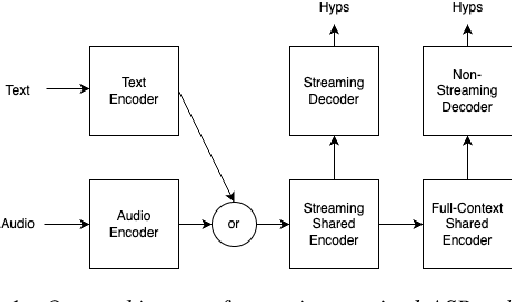
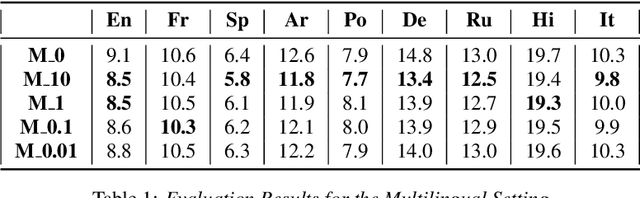
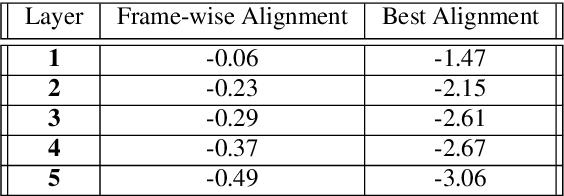
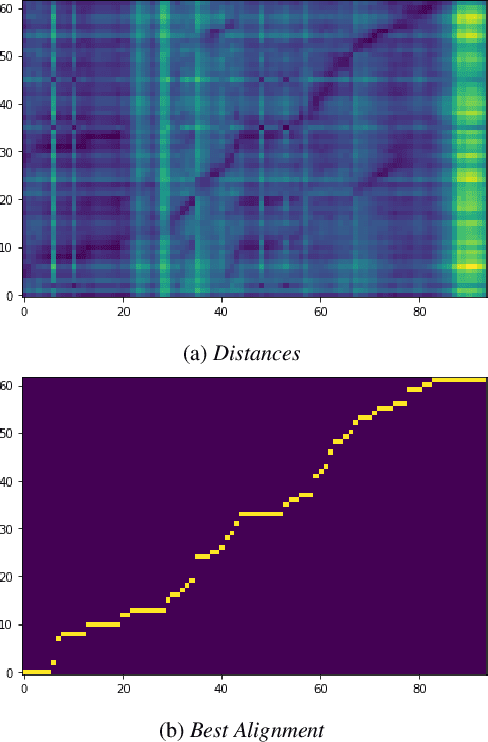
The last year has seen astonishing progress in text-prompted image generation premised on the idea of a cross-modal representation space in which the text and image domains are represented jointly. In ASR, this idea has found application as joint speech-text encoders that can scale to the capacities of very large parameter models by being trained on both unpaired speech and text. While these methods show promise, they have required special treatment of the sequence-length mismatch inherent in speech and text, either by up-sampling heuristics or an explicit alignment model. In this work, we offer evidence that joint speech-text encoders naturally achieve consistent representations across modalities by disregarding sequence length, and argue that consistency losses could forgive length differences and simply assume the best alignment. We show that such a loss improves downstream WER in both a large-parameter monolingual and multilingual system.
A Comparison of Semi-Supervised Learning Techniques for Streaming ASR at Scale
Apr 19, 2023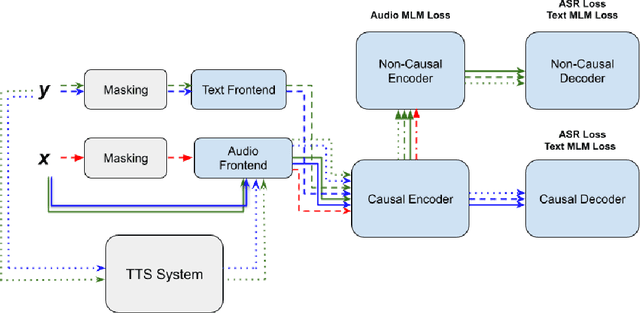
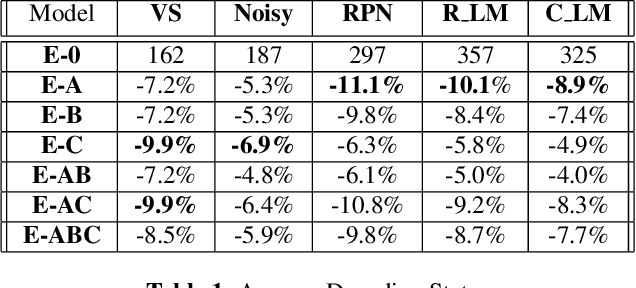
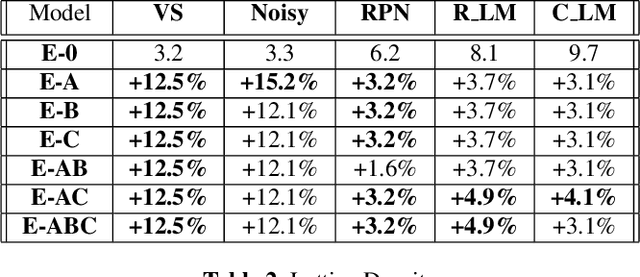
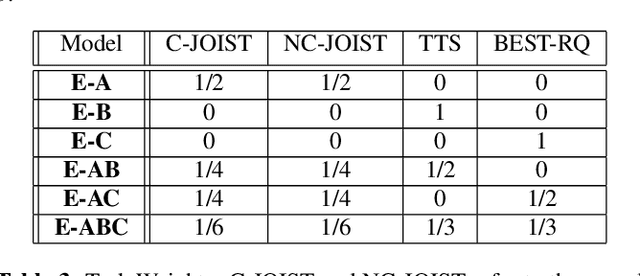
Unpaired text and audio injection have emerged as dominant methods for improving ASR performance in the absence of a large labeled corpus. However, little guidance exists on deploying these methods to improve production ASR systems that are trained on very large supervised corpora and with realistic requirements like a constrained model size and CPU budget, streaming capability, and a rich lattice for rescoring and for downstream NLU tasks. In this work, we compare three state-of-the-art semi-supervised methods encompassing both unpaired text and audio as well as several of their combinations in a controlled setting using joint training. We find that in our setting these methods offer many improvements beyond raw WER, including substantial gains in tail-word WER, decoder computation during inference, and lattice density.
Dual Learning for Large Vocabulary On-Device ASR
Jan 11, 2023



Dual learning is a paradigm for semi-supervised machine learning that seeks to leverage unsupervised data by solving two opposite tasks at once. In this scheme, each model is used to generate pseudo-labels for unlabeled examples that are used to train the other model. Dual learning has seen some use in speech processing by pairing ASR and TTS as dual tasks. However, these results mostly address only the case of using unpaired examples to compensate for very small supervised datasets, and mostly on large, non-streaming models. Dual learning has not yet been proven effective for using unsupervised data to improve realistic on-device streaming models that are already trained on large supervised corpora. We provide this missing piece though an analysis of an on-device-sized streaming conformer trained on the entirety of Librispeech, showing relative WER improvements of 10.7%/5.2% without an LM and 11.7%/16.4% with an LM.
Towards Disentangled Speech Representations
Aug 28, 2022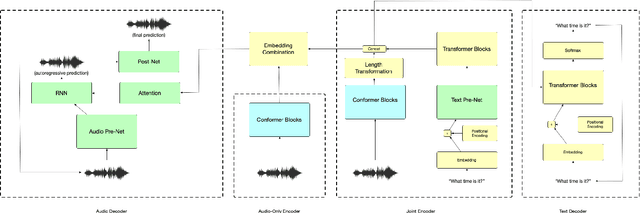
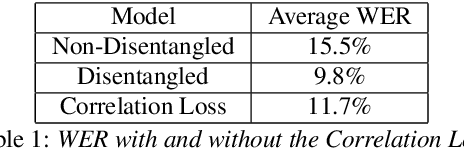

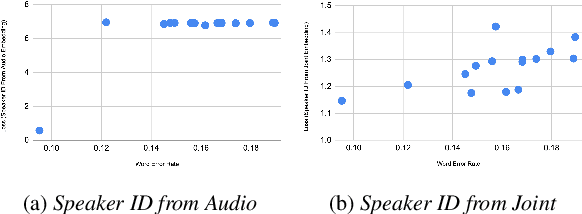
The careful construction of audio representations has become a dominant feature in the design of approaches to many speech tasks. Increasingly, such approaches have emphasized "disentanglement", where a representation contains only parts of the speech signal relevant to transcription while discarding irrelevant information. In this paper, we construct a representation learning task based on joint modeling of ASR and TTS, and seek to learn a representation of audio that disentangles that part of the speech signal that is relevant to transcription from that part which is not. We present empirical evidence that successfully finding such a representation is tied to the randomness inherent in training. We then make the observation that these desired, disentangled solutions to the optimization problem possess unique statistical properties. Finally, we show that enforcing these properties during training improves WER by 24.5% relative on average for our joint modeling task. These observations motivate a novel approach to learning effective audio representations.
Towards Measuring Fairness in Speech Recognition: Casual Conversations Dataset Transcriptions
Nov 18, 2021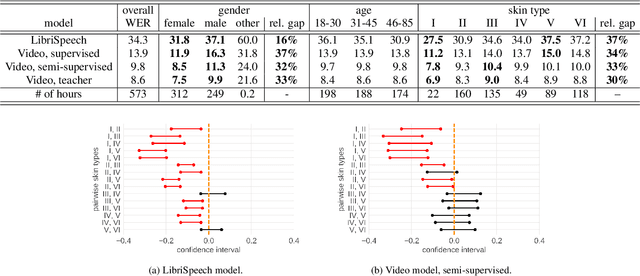

It is well known that many machine learning systems demonstrate bias towards specific groups of individuals. This problem has been studied extensively in the Facial Recognition area, but much less so in Automatic Speech Recognition (ASR). This paper presents initial Speech Recognition results on "Casual Conversations" -- a publicly released 846 hour corpus designed to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of metadata, including age, gender, and skin tone. The entire corpus has been manually transcribed, allowing for detailed ASR evaluations across these metadata. Multiple ASR models are evaluated, including models trained on LibriSpeech, 14,000 hour transcribed, and over 2 million hour untranscribed social media videos. Significant differences in word error rate across gender and skin tone are observed at times for all models. We are releasing human transcripts from the Casual Conversations dataset to encourage the community to develop a variety of techniques to reduce these statistical biases.
Cascaded Multilingual Audio-Visual Learning from Videos
Nov 08, 2021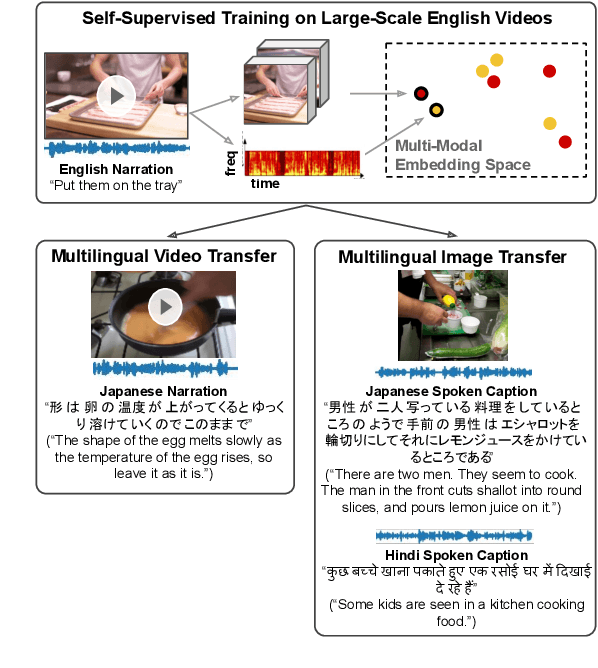
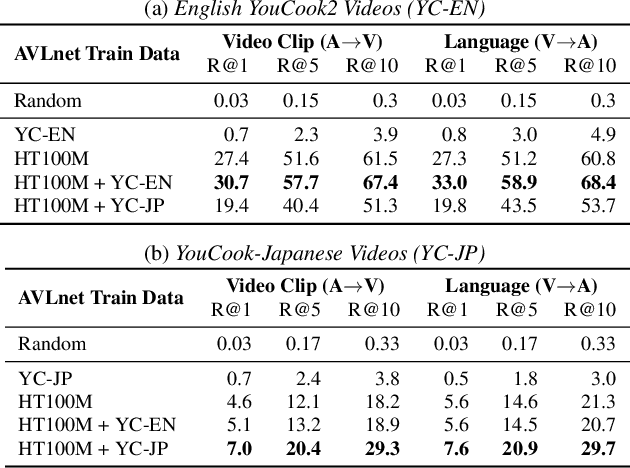

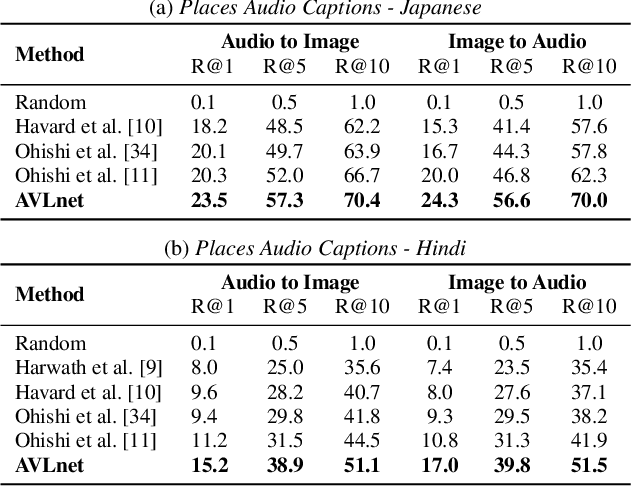
In this paper, we explore self-supervised audio-visual models that learn from instructional videos. Prior work has shown that these models can relate spoken words and sounds to visual content after training on a large-scale dataset of videos, but they were only trained and evaluated on videos in English. To learn multilingual audio-visual representations, we propose a cascaded approach that leverages a model trained on English videos and applies it to audio-visual data in other languages, such as Japanese videos. With our cascaded approach, we show an improvement in retrieval performance of nearly 10x compared to training on the Japanese videos solely. We also apply the model trained on English videos to Japanese and Hindi spoken captions of images, achieving state-of-the-art performance.
Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings
Oct 08, 2021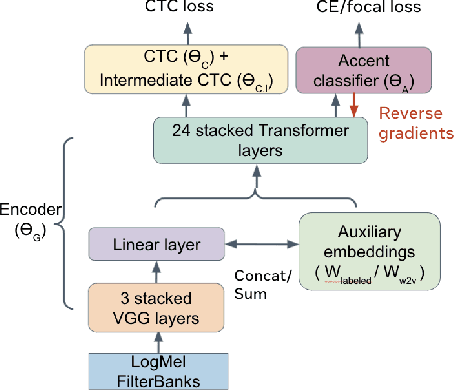
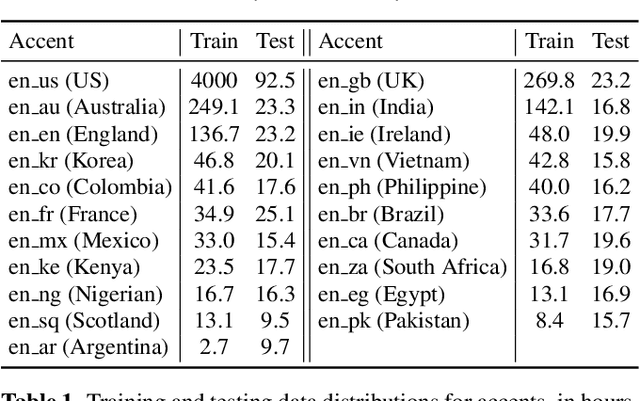
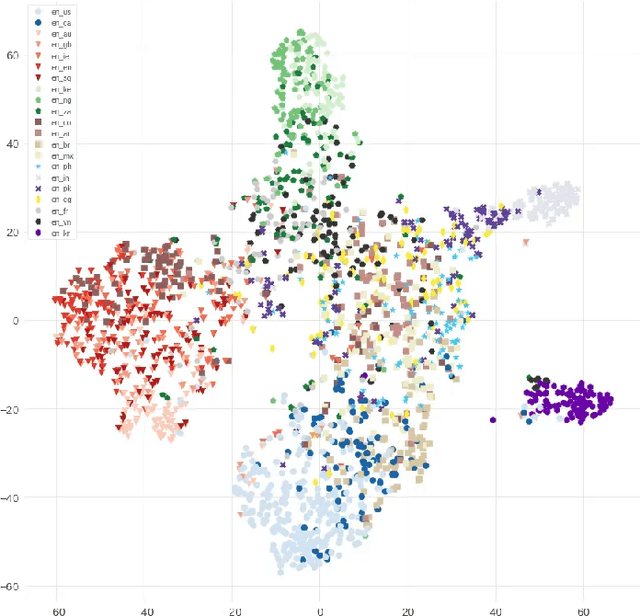

Speech recognition models often obtain degraded performance when tested on speech with unseen accents. Domain-adversarial training (DAT) and multi-task learning (MTL) are two common approaches for building accent-robust ASR models. ASR models using accent embeddings is another approach for improving robustness to accents. In this study, we perform systematic comparisons of DAT and MTL approaches using a large volume of English accent corpus (4000 hours of US English speech and 1244 hours of 20 non-US-English accents speech). We explore embeddings trained under supervised and unsupervised settings: a separate embedding matrix trained using accent labels, and embeddings extracted from a fine-tuned wav2vec model. We find that our DAT model trained with supervised embeddings achieves the best performance overall and consistently provides benefits for all testing datasets, and our MTL model trained with wav2vec embeddings are helpful learning accent-invariant features and improving novel/unseen accents. We also illustrate that wav2vec embeddings have more advantages for building accent-robust ASR when no accent labels are available for training supervised embeddings.
Multimodal Clustering Networks for Self-supervised Learning from Unlabeled Videos
May 05, 2021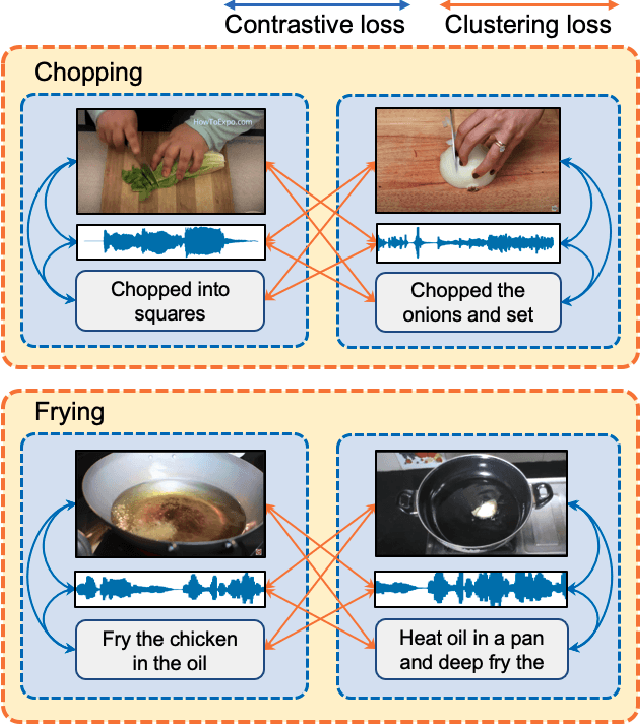
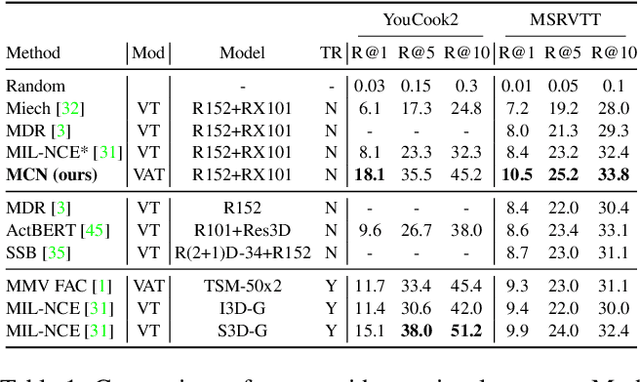
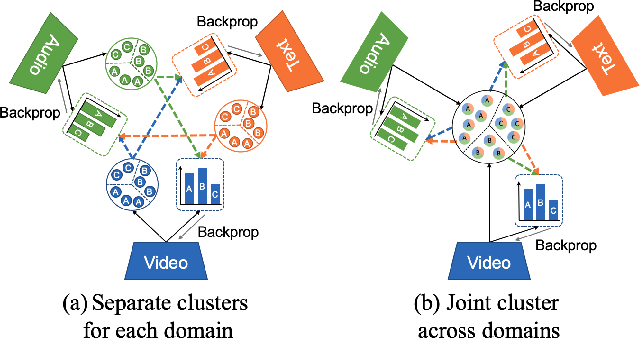
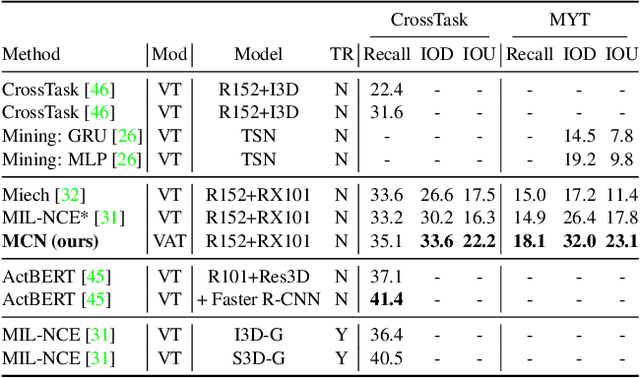
Multimodal self-supervised learning is getting more and more attention as it allows not only to train large networks without human supervision but also to search and retrieve data across various modalities. In this context, this paper proposes a self-supervised training framework that learns a common multimodal embedding space that, in addition to sharing representations across different modalities, enforces a grouping of semantically similar instances. To this end, we extend the concept of instance-level contrastive learning with a multimodal clustering step in the training pipeline to capture semantic similarities across modalities. The resulting embedding space enables retrieval of samples across all modalities, even from unseen datasets and different domains. To evaluate our approach, we train our model on the HowTo100M dataset and evaluate its zero-shot retrieval capabilities in two challenging domains, namely text-to-video retrieval, and temporal action localization, showing state-of-the-art results on four different datasets.
Accented Speech Recognition Inspired by Human Perception
Apr 09, 2021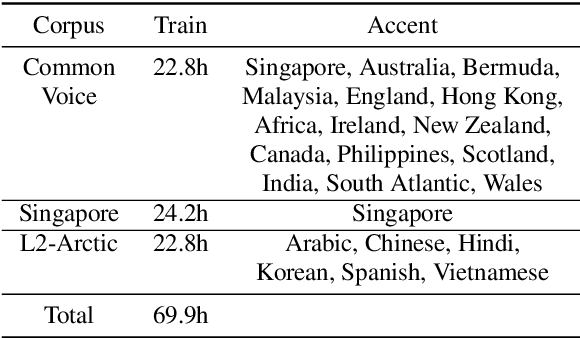
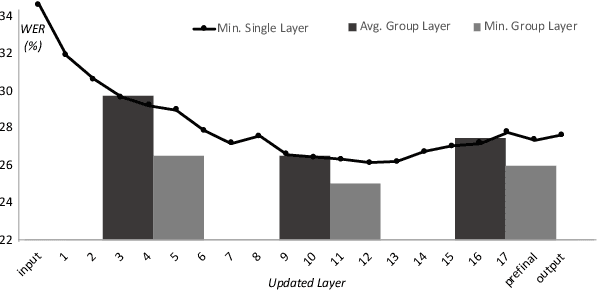
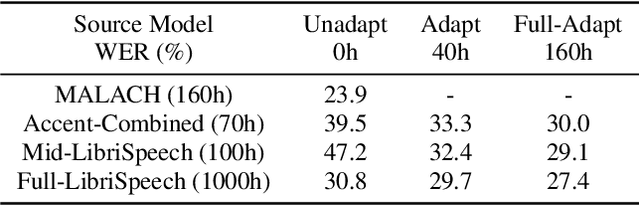
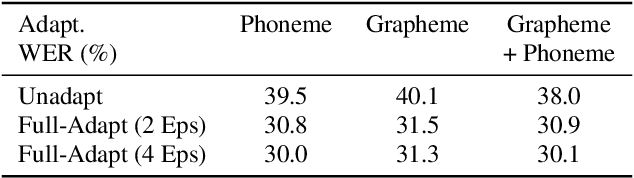
While improvements have been made in automatic speech recognition performance over the last several years, machines continue to have significantly lower performance on accented speech than humans. In addition, the most significant improvements on accented speech primarily arise by overwhelming the problem with hundreds or even thousands of hours of data. Humans typically require much less data to adapt to a new accent. This paper explores methods that are inspired by human perception to evaluate possible performance improvements for recognition of accented speech, with a specific focus on recognizing speech with a novel accent relative to that of the training data. Our experiments are run on small, accessible datasets that are available to the research community. We explore four methodologies: pre-exposure to multiple accents, grapheme and phoneme-based pronunciations, dropout (to improve generalization to a novel accent), and the identification of the layers in the neural network that can specifically be associated with accent modeling. Our results indicate that methods based on human perception are promising in reducing WER and understanding how accented speech is modeled in neural networks for novel accents.
Speak or Chat with Me: End-to-End Spoken Language Understanding System with Flexible Inputs
Apr 07, 2021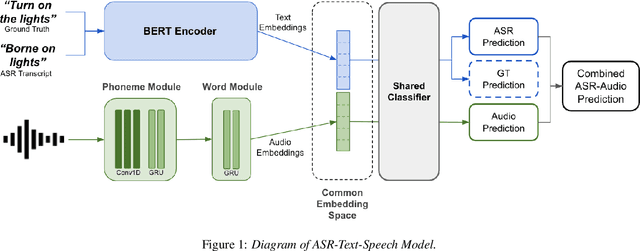
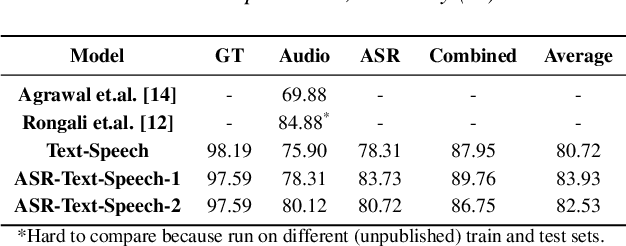
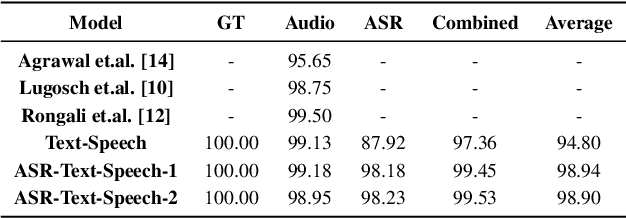
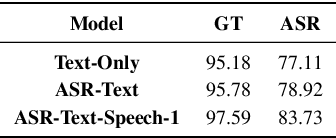
A major focus of recent research in spoken language understanding (SLU) has been on the end-to-end approach where a single model can predict intents directly from speech inputs without intermediate transcripts. However, this approach presents some challenges. First, since speech can be considered as personally identifiable information, in some cases only automatic speech recognition (ASR) transcripts are accessible. Second, intent-labeled speech data is scarce. To address the first challenge, we propose a novel system that can predict intents from flexible types of inputs: speech, ASR transcripts, or both. We demonstrate strong performance for either modality separately, and when both speech and ASR transcripts are available, through system combination, we achieve better results than using a single input modality. To address the second challenge, we leverage a semantically robust pre-trained BERT model and adopt a cross-modal system that co-trains text embeddings and acoustic embeddings in a shared latent space. We further enhance this system by utilizing an acoustic module pre-trained on LibriSpeech and domain-adapting the text module on our target datasets. Our experiments show significant advantages for these pre-training and fine-tuning strategies, resulting in a system that achieves competitive intent-classification performance on Snips SLU and Fluent Speech Commands datasets.