 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Fault-tolerant Control of Underwater Vehicles with Thruster Failures
Apr 22, 2025
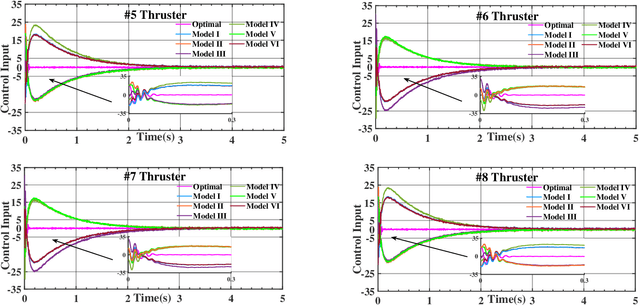
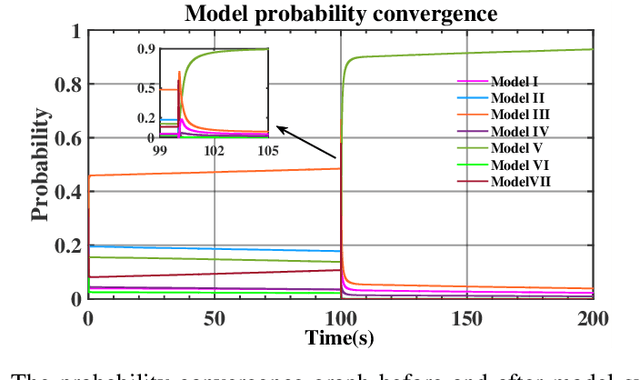
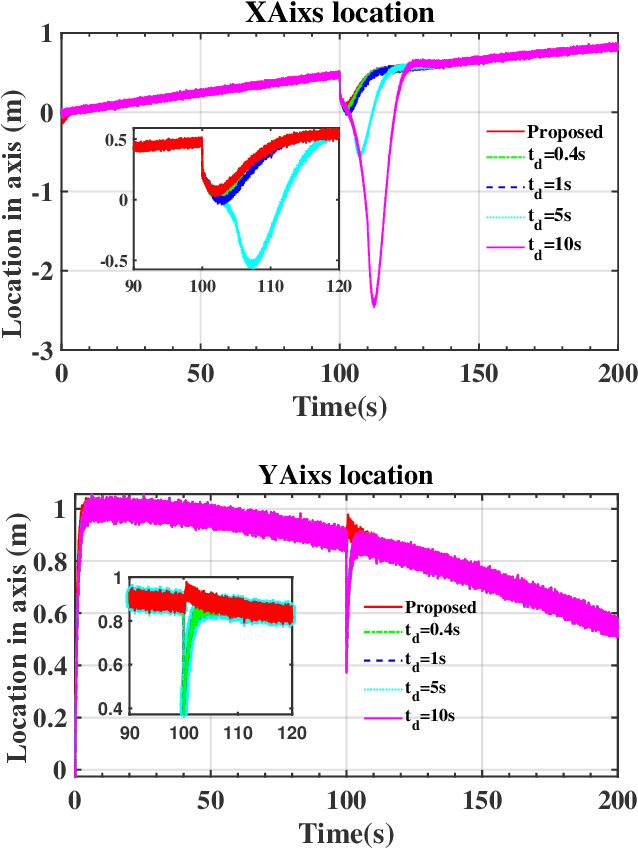
This paper presents a fault-tolerant control for the trajectory tracking of autonomous underwater vehicles (AUVs) against thruster failures. We formulate faults in AUV thrusters as discrete switching events during a UAV mission, and develop a soft-switching approach in facilitating shift of control strategies across fault scenarios. We mathematically define AUV thruster fault scenarios, and develop the fault-tolerant control that captures the fault scenario via Bayesian approach. Particularly, when the AUV fault type switches from one to another, the developed control captures the fault states and maintains the control by a linear quadratic tracking controller. With the captured fault states by Bayesian approach, we derive the control law by aggregating the control outputs for individual fault scenarios weighted by their Bayesian posterior probability. The developed fault-tolerant control works in an adaptive way and guarantees soft-switching across fault scenarios, and requires no complicated fault detection dedicated to different type of faults. The entailed soft-switching ensures stable AUV trajectory tracking when fault type shifts, which otherwise leads to reduced control under hard-switching control strategies. We conduct numerical simulations with diverse AUV thruster fault settings. The results demonstrate that the proposed control can provide smooth transition across thruster failures, and effectively sustain AUV trajectory tracking control in case of thruster failures and failure shifts.
Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
Feb 11, 2025The imitation of voice, targeted on specific speech attributes such as timbre and speaking style, is crucial in speech generation. However, existing methods rely heavily on annotated data, and struggle with effectively disentangling timbre and style, leading to challenges in achieving controllable generation, especially in zero-shot scenarios. To address these issues, we propose Vevo, a versatile zero-shot voice imitation framework with controllable timbre and style. Vevo operates in two core stages: (1) Content-Style Modeling: Given either text or speech's content tokens as input, we utilize an autoregressive transformer to generate the content-style tokens, which is prompted by a style reference; (2) Acoustic Modeling: Given the content-style tokens as input, we employ a flow-matching transformer to produce acoustic representations, which is prompted by a timbre reference. To obtain the content and content-style tokens of speech, we design a fully self-supervised approach that progressively decouples the timbre, style, and linguistic content of speech. Specifically, we adopt VQ-VAE as the tokenizer for the continuous hidden features of HuBERT. We treat the vocabulary size of the VQ-VAE codebook as the information bottleneck, and adjust it carefully to obtain the disentangled speech representations. Solely self-supervised trained on 60K hours of audiobook speech data, without any fine-tuning on style-specific corpora, Vevo matches or surpasses existing methods in accent and emotion conversion tasks. Additionally, Vevo's effectiveness in zero-shot voice conversion and text-to-speech tasks further demonstrates its strong generalization and versatility. Audio samples are available at https://versavoice.github.io.
Exploring the Generalizability of Geomagnetic Navigation: A Deep Reinforcement Learning approach with Policy Distillation
Feb 07, 2025



The advancement in autonomous vehicles has empowered navigation and exploration in unknown environments. Geomagnetic navigation for autonomous vehicles has drawn increasing attention with its independence from GPS or inertial navigation devices. While geomagnetic navigation approaches have been extensively investigated, the generalizability of learned geomagnetic navigation strategies remains unexplored. The performance of a learned strategy can degrade outside of its source domain where the strategy is learned, due to a lack of knowledge about the geomagnetic characteristics in newly entered areas. This paper explores the generalization of learned geomagnetic navigation strategies via deep reinforcement learning (DRL). Particularly, we employ DRL agents to learn multiple teacher models from distributed domains that represent dispersed navigation strategies, and amalgamate the teacher models for generalizability across navigation areas. We design a reward shaping mechanism in training teacher models where we integrate both potential-based and intrinsic-motivated rewards. The designed reward shaping can enhance the exploration efficiency of the DRL agent and improve the representation of the teacher models. Upon the gained teacher models, we employ multi-teacher policy distillation to merge the policies learned by individual teachers, leading to a navigation strategy with generalizability across navigation domains. We conduct numerical simulations, and the results demonstrate an effective transfer of the learned DRL model from a source domain to new navigation areas. Compared to existing evolutionary-based geomagnetic navigation methods, our approach provides superior performance in terms of navigation length, duration, heading deviation, and success rate in cross-domain navigation.
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024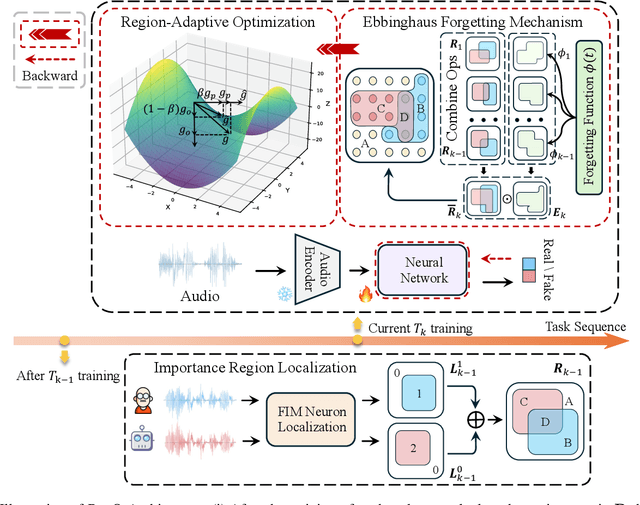
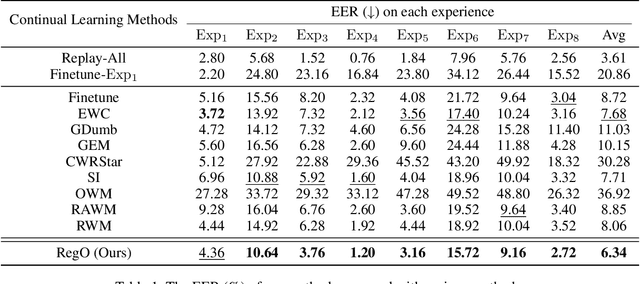
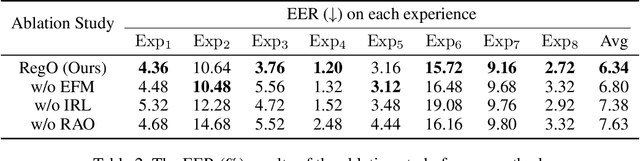
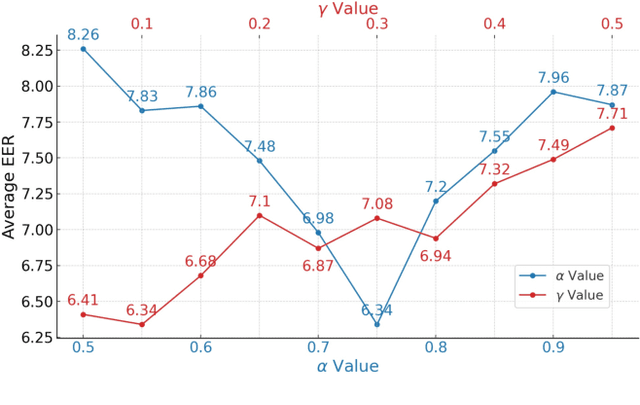
Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
Hardware-in-the-loop Simulation Testbed for Geomagnetic Navigation
Dec 16, 2024



Geomagnetic navigation leverages the ubiquitous Earth's magnetic signals to navigate missions, without dependence on GPS services or pre-stored geographic maps. It has drawn increasing attention and is promising particularly for long-range navigation into unexplored areas. Current geomagnetic navigation studies are still in the early stages with simulations and computational validations, without concrete efforts to develop cost-friendly test platforms that can empower deployment and experimental analysis of the developed approaches. This paper presents a hardware-in-the-loop simulation testbed to support geomagnetic navigation experimentation. Our testbed is dedicated to synthesizing geomagnetic field environment for the navigation. We develop the software in the testbed to simulate the dynamics of the navigation environment, and we build the hardware to generate the physical magnetic field, which follows and aligns with the simulated environment. The testbed aims to provide controllable magnetic field that can be used to experiment with geomagnetic navigation in labs, thus avoiding real and expensive navigation experiments, e.g., in the ocean, for validating navigation prototypes. We build the testbed with off-the-shelf hardware in an unshielded environment to reduce cost. We also develop the field generation control and hardware parameter optimization for quality magnetic field generation. We conduct a detailed performance analysis to show the quality of the field generation by the testbed, and we report the experimental results on performance indicators, including accuracy, uniformity, stability, and convergence of the generated field towards the target geomagnetic environment.
Long-distance Geomagnetic Navigation in GNSS-denied Environments with Deep Reinforcement Learning
Oct 21, 2024
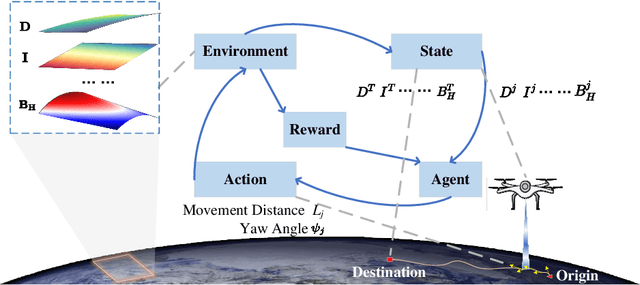
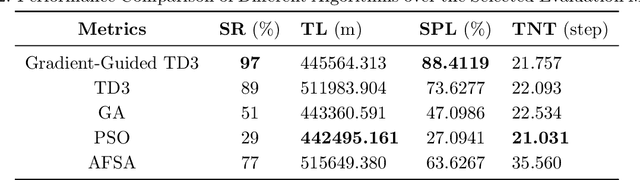
Geomagnetic navigation has drawn increasing attention with its capacity in navigating through complex environments and its independence from external navigation services like global navigation satellite systems (GNSS). Existing studies on geomagnetic navigation, i.e., matching navigation and bionic navigation, rely on pre-stored map or extensive searches, leading to limited applicability or reduced navigation efficiency in unexplored areas. To address the issues with geomagnetic navigation in areas where GNSS is unavailable, this paper develops a deep reinforcement learning (DRL)-based mechanism, especially for long-distance geomagnetic navigation. The designed mechanism trains an agent to learn and gain the magnetoreception capacity for geomagnetic navigation, rather than using any pre-stored map or extensive and expensive searching approaches. Particularly, we integrate the geomagnetic gradient-based parallel approach into geomagnetic navigation. This integration mitigates the over-exploration of the learning agent by adjusting the geomagnetic gradient, such that the obtained gradient is aligned towards the destination. We explore the effectiveness of the proposed approach via detailed numerical simulations, where we implement twin delayed deep deterministic policy gradient (TD3) in realizing the proposed approach. The results demonstrate that our approach outperforms existing metaheuristic and bionic navigation methods in long-distance missions under diverse navigation conditions.
Efficient Streaming LLM for Speech Recognition
Oct 02, 2024



Recent works have shown that prompting large language models with audio encodings can unlock speech recognition capabilities. However, existing techniques do not scale efficiently, especially while handling long form streaming audio inputs -- not only do they extrapolate poorly beyond the audio length seen during training, but they are also computationally inefficient due to the quadratic cost of attention. In this work, we introduce SpeechLLM-XL, a linear scaling decoder-only model for streaming speech recognition. We process audios in configurable chunks using limited attention window for reduced computation, and the text tokens for each audio chunk are generated auto-regressively until an EOS is predicted. During training, the transcript is segmented into chunks, using a CTC forced alignment estimated from encoder output. SpeechLLM-XL with 1.28 seconds chunk size achieves 2.7%/6.7% WER on LibriSpeech test clean/other, and it shows no quality degradation on long form utterances 10x longer than the training utterances.
Utilizing Speaker Profiles for Impersonation Audio Detection
Aug 30, 2024



Fake audio detection is an emerging active topic. A growing number of literatures have aimed to detect fake utterance, which are mostly generated by Text-to-speech (TTS) or voice conversion (VC). However, countermeasures against impersonation remain an underexplored area. Impersonation is a fake type that involves an imitator replicating specific traits and speech style of a target speaker. Unlike TTS and VC, which often leave digital traces or signal artifacts, impersonation involves live human beings producing entirely natural speech, rendering the detection of impersonation audio a challenging task. Thus, we propose a novel method that integrates speaker profiles into the process of impersonation audio detection. Speaker profiles are inherent characteristics that are challenging for impersonators to mimic accurately, such as speaker's age, job. We aim to leverage these features to extract discriminative information for detecting impersonation audio. Moreover, there is no large impersonated speech corpora available for quantitative study of impersonation impacts. To address this gap, we further design the first large-scale, diverse-speaker Chinese impersonation dataset, named ImPersonation Audio Detection (IPAD), to advance the community's research on impersonation audio detection. We evaluate several existing fake audio detection methods on our proposed dataset IPAD, demonstrating its necessity and the challenges. Additionally, our findings reveal that incorporating speaker profiles can significantly enhance the model's performance in detecting impersonation audio.
An Unsupervised Domain Adaptation Method for Locating Manipulated Region in partially fake Audio
Jul 11, 2024
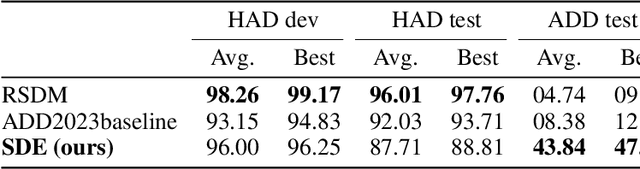
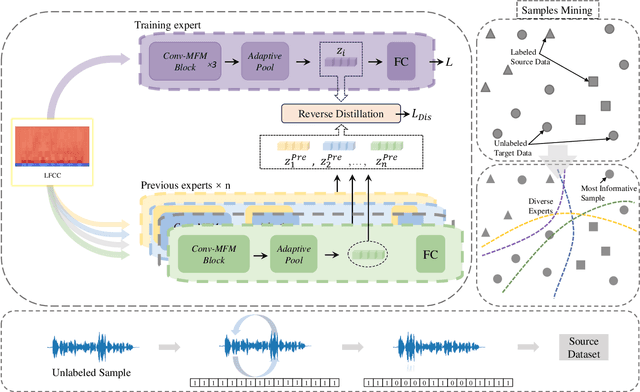
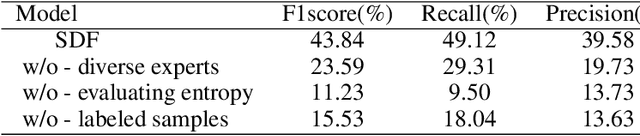
When the task of locating manipulation regions in partially-fake audio (PFA) involves cross-domain datasets, the performance of deep learning models drops significantly due to the shift between the source and target domains. To address this issue, existing approaches often employ data augmentation before training. However, they overlook the characteristics in target domain that are absent in source domain. Inspired by the mixture-of-experts model, we propose an unsupervised method named Samples mining with Diversity and Entropy (SDE). Our method first learns from a collection of diverse experts that achieve great performance from different perspectives in the source domain, but with ambiguity on target samples. We leverage these diverse experts to select the most informative samples by calculating their entropy. Furthermore, we introduced a label generation method tailored for these selected samples that are incorporated in the training process in source domain integrating the target domain information. We applied our method to a cross-domain partially fake audio detection dataset, ADD2023Track2. By introducing 10% of unknown samples from the target domain, we achieved an F1 score of 43.84%, which represents a relative increase of 77.2% compared to the second-best method.
Efficient Neural Common Neighbor for Temporal Graph Link Prediction
Jun 12, 2024
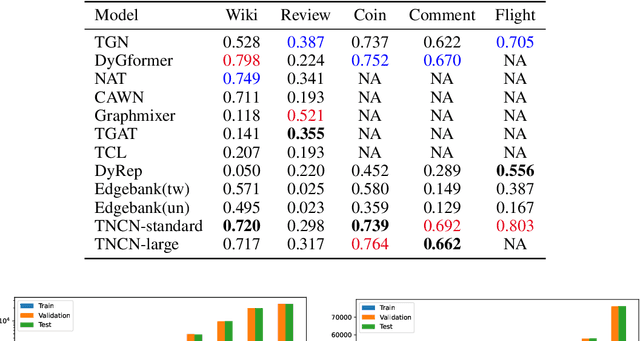


Temporal graphs are ubiquitous in real-world scenarios, such as social network, trade and transportation. Predicting dynamic links between nodes in a temporal graph is of vital importance. Traditional methods usually leverage the temporal neighborhood of interaction history to generate node embeddings first and then aggregate the source and target node embeddings to predict the link. However, such methods focus on learning individual node representations, but overlook the pairwise representation learning nature of link prediction and fail to capture the important pairwise features of links such as common neighbors (CN). Motivated by the success of Neural Common Neighbor (NCN) for static graph link prediction, we propose TNCN, a temporal version of NCN for link prediction in temporal graphs. TNCN dynamically updates a temporal neighbor dictionary for each node, and utilizes multi-hop common neighbors between the source and target node to learn a more effective pairwise representation. We validate our model on five large-scale real-world datasets from the Temporal Graph Benchmark (TGB), and find that it achieves new state-of-the-art performance on three of them. Additionally, TNCN demonstrates excellent scalability on large datasets, outperforming popular GNN baselines by up to 6.4 times in speed. Our code is available at https: //github.com/GraphPKU/TNCN.