 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection
Paper and Code



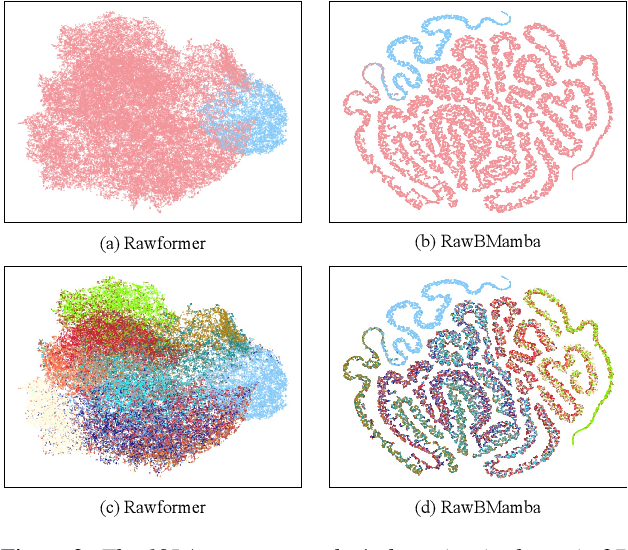
Fake artefacts for discriminating between bonafide and fake audio can exist in both short- and long-range segments. Therefore, combining local and global feature information can effectively discriminate between bonafide and fake audio. This paper proposes an end-to-end bidirectional state space model, named RawBMamba, to capture both short- and long-range discriminative information for audio deepfake detection. Specifically, we use sinc Layer and multiple convolutional layers to capture short-range features, and then design a bidirectional Mamba to address Mamba's unidirectional modelling problem and further capture long-range feature information. Moreover, we develop a bidirectional fusion module to integrate embeddings, enhancing audio context representation and combining short- and long-range information. The results show that our proposed RawBMamba achieves a 34.1\% improvement over Rawformer on ASVspoof2021 LA dataset, and demonstrates competitive performance on other datasets.