 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit Content, Preserve Acoustics: Imperceptible Text-Based Speech Editing via Self-Consistency Rewards
Jan 31, 2026Imperceptible text-based speech editing allows users to modify spoken content by altering the transcript. It demands that modified segments fuse seamlessly with the surrounding context. Prevalent methods operating in the acoustic space suffer from inherent content-style entanglement, leading to generation instability and boundary artifacts. In this paper, we propose a novel framework grounded in the principle of "Edit Content, Preserve Acoustics". Our approach relies on two core components: (1) Structural Foundations, which decouples editing into a stable semantic space while delegating acoustic reconstruction to a Flow Matching decoder; and (2) Perceptual Alignment, which employs a novel Self-Consistency Rewards Group Relative Policy Optimization. By leveraging a pre-trained Text-to-Speech model as an implicit critic -- complemented by strict intelligibility and duration constraints -- we effectively align the edited semantic token sequence with the original context. Empirical evaluations demonstrate that our method significantly outperforms state-of-the-art autoregressive and non-autoregressive baselines, achieving superior intelligibility, robustness, and perceptual quality.
OV-InstructTTS: Towards Open-Vocabulary Instruct Text-to-Speech
Jan 04, 2026Instruct Text-to-Speech (InstructTTS) leverages natural language descriptions as style prompts to guide speech synthesis. However, existing InstructTTS methods mainly rely on a direct combination of audio-related labels or their diverse rephrasings, making it difficult to handle flexible, high-level instructions. Such rigid control is insufficient for users such as content creators who wish to steer generation with descriptive instructions. To address these constraints, we introduce OV-InstructTTS, a new paradigm for open-vocabulary InstructTTS. We propose a comprehensive solution comprising a newly curated dataset, OV-Speech, and a novel reasoning-driven framework. The OV-Speech dataset pairs speech with open-vocabulary instructions, each augmented with a reasoning process that connects high-level instructions to acoustic features. The reasoning-driven framework infers emotional, acoustic, and paralinguistic information from open-vocabulary instructions before synthesizing speech. Evaluations show that this reasoning-driven approach significantly improves instruction-following fidelity and speech expressiveness. We believe this work can inspire the next user-friendly InstructTTS systems with stronger generalization and real-world applicability. The dataset and demos are publicly available on our project page.
$\mathcal{A}LLM4ADD$: Unlocking the Capabilities of Audio Large Language Models for Audio Deepfake Detection
May 16, 2025

Audio deepfake detection (ADD) has grown increasingly important due to the rise of high-fidelity audio generative models and their potential for misuse. Given that audio large language models (ALLMs) have made significant progress in various audio processing tasks, a heuristic question arises: Can ALLMs be leveraged to solve ADD?. In this paper, we first conduct a comprehensive zero-shot evaluation of ALLMs on ADD, revealing their ineffectiveness in detecting fake audio. To enhance their performance, we propose $\mathcal{A}LLM4ADD$, an ALLM-driven framework for ADD. Specifically, we reformulate ADD task as an audio question answering problem, prompting the model with the question: "Is this audio fake or real?". We then perform supervised fine-tuning to enable the ALLM to assess the authenticity of query audio. Extensive experiments are conducted to demonstrate that our ALLM-based method can achieve superior performance in fake audio detection, particularly in data-scarce scenarios. As a pioneering study, we anticipate that this work will inspire the research community to leverage ALLMs to develop more effective ADD systems.
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024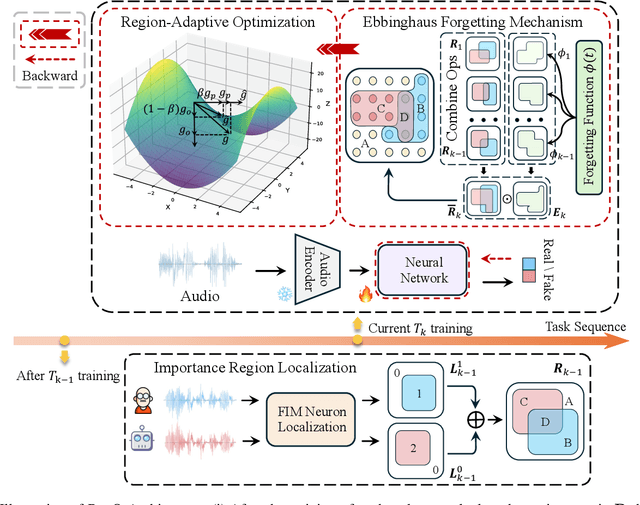
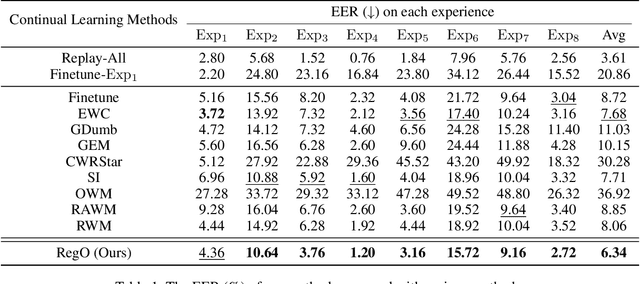
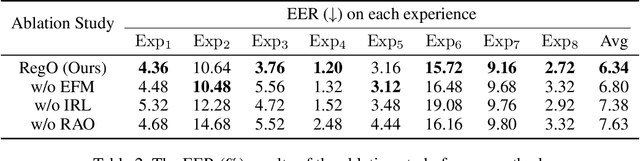
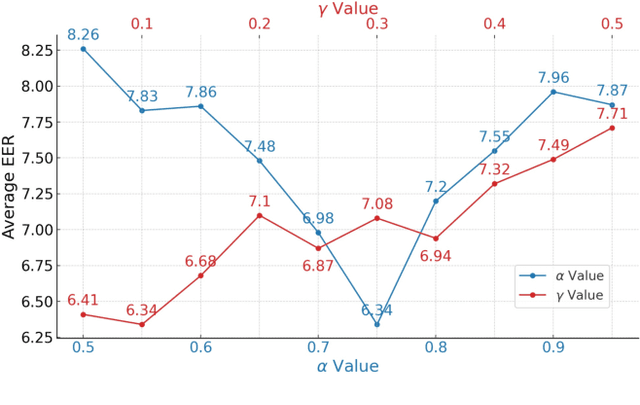
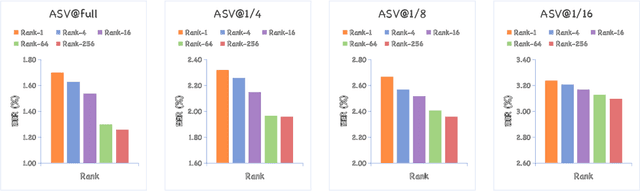
Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
Reject Threshold Adaptation for Open-Set Model Attribution of Deepfake Audio
Dec 02, 2024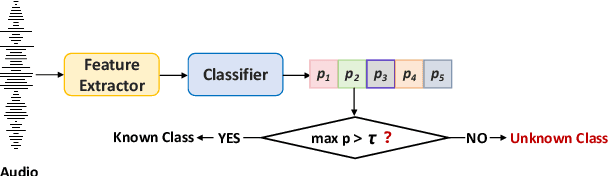

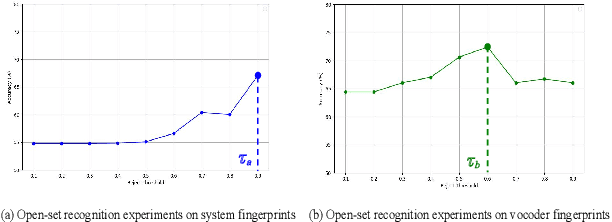

Open environment oriented open set model attribution of deepfake audio is an emerging research topic, aiming to identify the generation models of deepfake audio. Most previous work requires manually setting a rejection threshold for unknown classes to compare with predicted probabilities. However, models often overfit training instances and generate overly confident predictions. Moreover, thresholds that effectively distinguish unknown categories in the current dataset may not be suitable for identifying known and unknown categories in another data distribution. To address the issues, we propose a novel framework for open set model attribution of deepfake audio with rejection threshold adaptation (ReTA). Specifically, the reconstruction error learning module trains by combining the representation of system fingerprints with labels corresponding to either the target class or a randomly chosen other class label. This process generates matching and non-matching reconstructed samples, establishing the reconstruction error distributions for each class and laying the foundation for the reject threshold calculation module. The reject threshold calculation module utilizes gaussian probability estimation to fit the distributions of matching and non-matching reconstruction errors. It then computes adaptive reject thresholds for all classes through probability minimization criteria. The experimental results demonstrate the effectiveness of ReTA in improving the open set model attributes of deepfake audio.
Unification of Balti and trans-border sister dialects in the essence of LLMs and AI Technology
Nov 20, 2024The language called Balti belongs to the Sino-Tibetan, specifically the Tibeto-Burman language family. It is understood with variations, across populations in India, China, Pakistan, Nepal, Tibet, Burma, and Bhutan, influenced by local cultures and producing various dialects. Considering the diverse cultural, socio-political, religious, and geographical impacts, it is important to step forward unifying the dialects, the basis of common root, lexica, and phonological perspectives, is vital. In the era of globalization and the increasingly frequent developments in AI technology, understanding the diversity and the efforts of dialect unification is important to understanding commonalities and shortening the gaps impacted by unavoidable circumstances. This article analyzes and examines how artificial intelligence AI in the essence of Large Language Models LLMs, can assist in analyzing, documenting, and standardizing the endangered Balti Language, based on the efforts made in different dialects so far.
From Statistical Methods to Pre-Trained Models; A Survey on Automatic Speech Recognition for Resource Scarce Urdu Language
Nov 20, 2024



Automatic Speech Recognition (ASR) technology has witnessed significant advancements in recent years, revolutionizing human-computer interactions. While major languages have benefited from these developments, lesser-resourced languages like Urdu face unique challenges. This paper provides an extensive exploration of the dynamic landscape of ASR research, focusing particularly on the resource-constrained Urdu language, which is widely spoken across South Asian nations. It outlines current research trends, technological advancements, and potential directions for future studies in Urdu ASR, aiming to pave the way for forthcoming researchers interested in this domain. By leveraging contemporary technologies, analyzing existing datasets, and evaluating effective algorithms and tools, the paper seeks to shed light on the unique challenges and opportunities associated with Urdu language processing and its integration into the broader field of speech research.
WMCodec: End-to-End Neural Speech Codec with Deep Watermarking for Authenticity Verification
Sep 18, 2024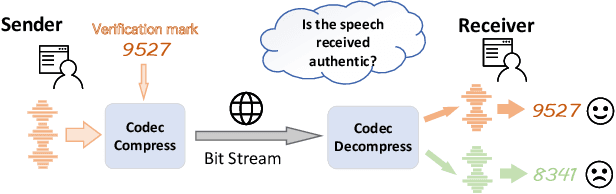
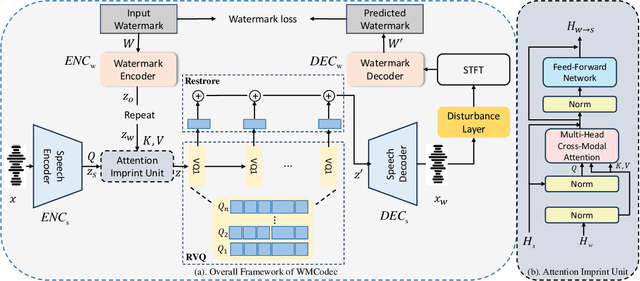
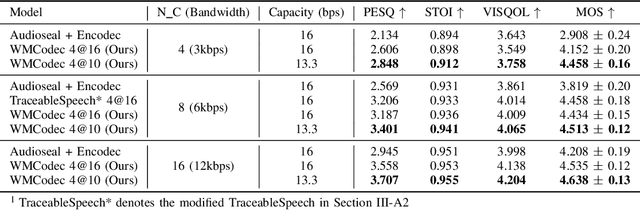
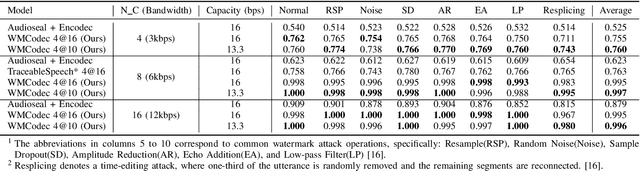
Recent advances in speech spoofing necessitate stronger verification mechanisms in neural speech codecs to ensure authenticity. Current methods embed numerical watermarks before compression and extract them from reconstructed speech for verification, but face limitations such as separate training processes for the watermark and codec, and insufficient cross-modal information integration, leading to reduced watermark imperceptibility, extraction accuracy, and capacity. To address these issues, we propose WMCodec, the first neural speech codec to jointly train compression-reconstruction and watermark embedding-extraction in an end-to-end manner, optimizing both imperceptibility and extractability of the watermark. Furthermore, We design an iterative Attention Imprint Unit (AIU) for deeper feature integration of watermark and speech, reducing the impact of quantization noise on the watermark. Experimental results show WMCodec outperforms AudioSeal with Encodec in most quality metrics for watermark imperceptibility and consistently exceeds both AudioSeal with Encodec and reinforced TraceableSpeech in extraction accuracy of watermark. At bandwidth of 6 kbps with a watermark capacity of 16 bps, WMCodec maintains over 99% extraction accuracy under common attacks, demonstrating strong robustness.
VQ-CTAP: Cross-Modal Fine-Grained Sequence Representation Learning for Speech Processing
Aug 11, 2024Deep learning has brought significant improvements to the field of cross-modal representation learning. For tasks such as text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), a cross-modal fine-grained (frame-level) sequence representation is desired, emphasizing the semantic content of the text modality while de-emphasizing the paralinguistic information of the speech modality. We propose a method called "Vector Quantized Contrastive Token-Acoustic Pre-training (VQ-CTAP)", which uses the cross-modal aligned sequence transcoder to bring text and speech into a joint multimodal space, learning how to connect text and speech at the frame level. The proposed VQ-CTAP is a paradigm for cross-modal sequence representation learning, offering a promising solution for fine-grained generation and recognition tasks in speech processing. The VQ-CTAP can be directly applied to VC and ASR tasks without fine-tuning or additional structures. We propose a sequence-aware semantic connector, which connects multiple frozen pre-trained modules for the TTS task, exhibiting a plug-and-play capability. We design a stepping optimization strategy to ensure effective model convergence by gradually injecting and adjusting the influence of various loss components. Furthermore, we propose a semantic-transfer-wise paralinguistic consistency loss to enhance representational capabilities, allowing the model to better generalize to unseen data and capture the nuances of paralinguistic information. In addition, VQ-CTAP achieves high-compression speech coding at a rate of 25Hz from 24kHz input waveforms, which is a 960-fold reduction in the sampling rate. The audio demo is available at https://qiangchunyu.github.io/VQCTAP/
ADD 2023: Towards Audio Deepfake Detection and Analysis in the Wild
Aug 09, 2024



The growing prominence of the field of audio deepfake detection is driven by its wide range of applications, notably in protecting the public from potential fraud and other malicious activities, prompting the need for greater attention and research in this area. The ADD 2023 challenge goes beyond binary real/fake classification by emulating real-world scenarios, such as the identification of manipulated intervals in partially fake audio and determining the source responsible for generating any fake audio, both with real-life implications, notably in audio forensics, law enforcement, and construction of reliable and trustworthy evidence. To further foster research in this area, in this article, we describe the dataset that was used in the fake game, manipulation region location and deepfake algorithm recognition tracks of the challenge. We also focus on the analysis of the technical methodologies by the top-performing participants in each task and note the commonalities and differences in their approaches. Finally, we discuss the current technical limitations as identified through the technical analysis, and provide a roadmap for future research directions. The dataset is available for download.