 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Code-Switching ASR with Mixture of Experts Enhanced Speech-Conditioned LLM
Sep 24, 2024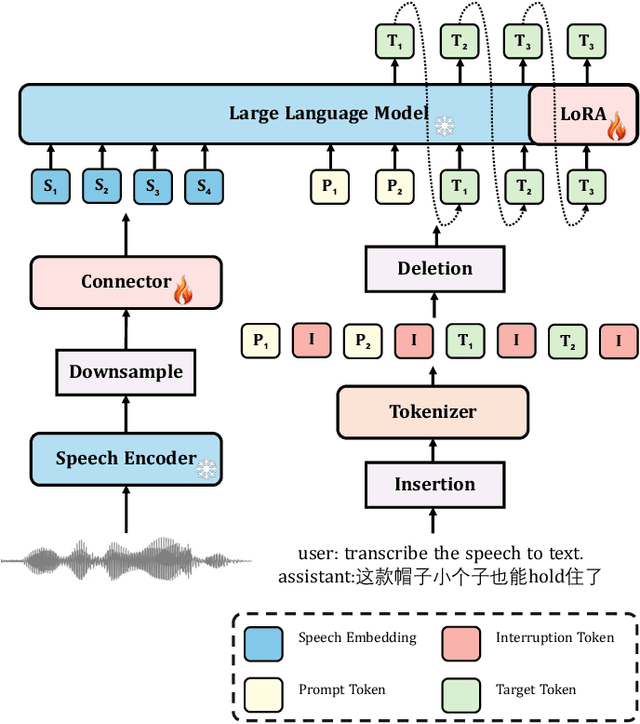
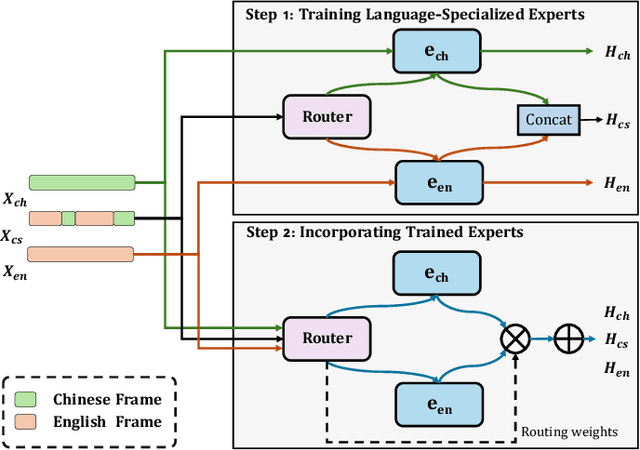
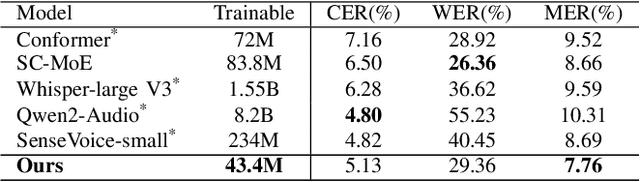

In this paper, we introduce a speech-conditioned Large Language Model (LLM) integrated with a Mixture of Experts (MoE) based connector to address the challenge of Code-Switching (CS) in Automatic Speech Recognition (ASR). Specifically, we propose an Insertion and Deletion of Interruption Token (IDIT) mechanism for better transfer text generation ability of LLM to speech recognition task. We also present a connecter with MoE architecture that manages multiple languages efficiently. To further enhance the collaboration of multiple experts and leverage the understanding capabilities of LLM, we propose a two-stage progressive training strategy: 1) The connector is unfrozen and trained with language-specialized experts to map speech representations to the text space. 2) The connector and LLM LoRA adaptor are trained with the proposed IDIT mechanism and all experts are activated to learn general representations. Experimental results demonstrate that our method significantly outperforms state-of-the-art models, including end-to-end and large-scale audio-language models.
Disentangling Age and Identity with a Mutual Information Minimization Approach for Cross-Age Speaker Verification
Sep 24, 2024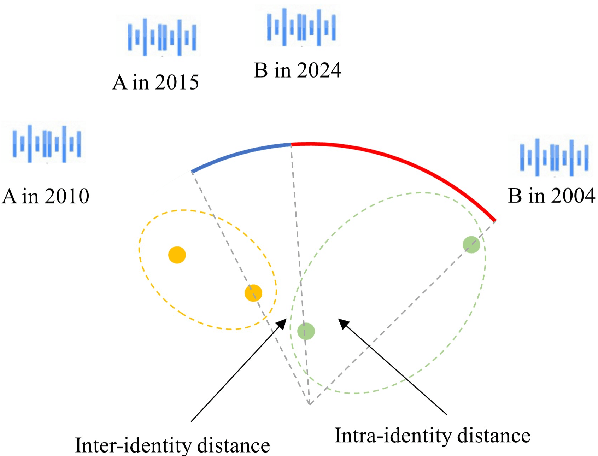
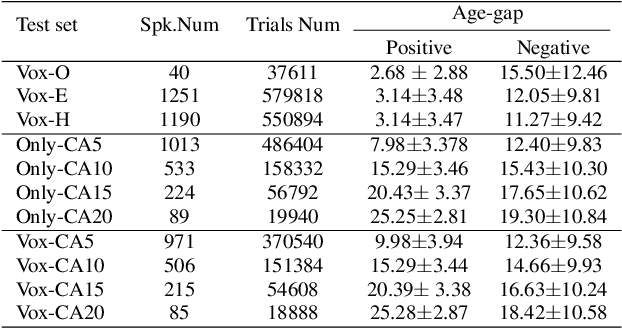
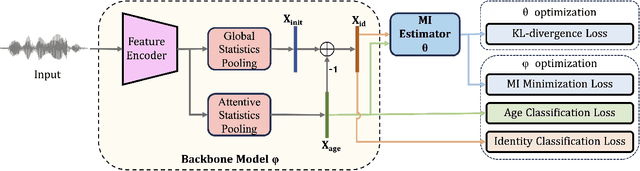

There has been an increasing research interest in cross-age speaker verification~(CASV). However, existing speaker verification systems perform poorly in CASV due to the great individual differences in voice caused by aging. In this paper, we propose a disentangled representation learning framework for CASV based on mutual information~(MI) minimization. In our method, a backbone model is trained to disentangle the identity- and age-related embeddings from speaker information, and an MI estimator is trained to minimize the correlation between age- and identity-related embeddings via MI minimization, resulting in age-invariant speaker embeddings. Furthermore, by using the age gaps between positive and negative samples, we propose an aging-aware MI minimization loss function that allows the backbone model to focus more on the vocal changes with large age gaps. Experimental results show that the proposed method outperforms other methods on multiple Cross-Age test sets of Vox-CA.
VQ-CTAP: Cross-Modal Fine-Grained Sequence Representation Learning for Speech Processing
Aug 11, 2024Deep learning has brought significant improvements to the field of cross-modal representation learning. For tasks such as text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), a cross-modal fine-grained (frame-level) sequence representation is desired, emphasizing the semantic content of the text modality while de-emphasizing the paralinguistic information of the speech modality. We propose a method called "Vector Quantized Contrastive Token-Acoustic Pre-training (VQ-CTAP)", which uses the cross-modal aligned sequence transcoder to bring text and speech into a joint multimodal space, learning how to connect text and speech at the frame level. The proposed VQ-CTAP is a paradigm for cross-modal sequence representation learning, offering a promising solution for fine-grained generation and recognition tasks in speech processing. The VQ-CTAP can be directly applied to VC and ASR tasks without fine-tuning or additional structures. We propose a sequence-aware semantic connector, which connects multiple frozen pre-trained modules for the TTS task, exhibiting a plug-and-play capability. We design a stepping optimization strategy to ensure effective model convergence by gradually injecting and adjusting the influence of various loss components. Furthermore, we propose a semantic-transfer-wise paralinguistic consistency loss to enhance representational capabilities, allowing the model to better generalize to unseen data and capture the nuances of paralinguistic information. In addition, VQ-CTAP achieves high-compression speech coding at a rate of 25Hz from 24kHz input waveforms, which is a 960-fold reduction in the sampling rate. The audio demo is available at https://qiangchunyu.github.io/VQCTAP/
Dynamic Multi-scale Convolution for Dialect Identification
Aug 02, 2021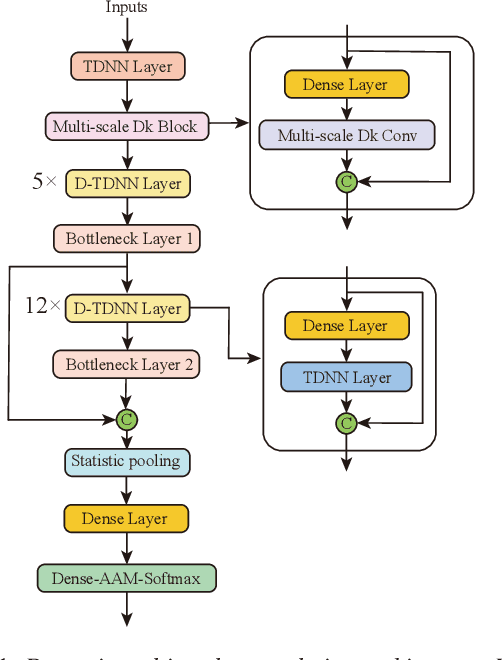

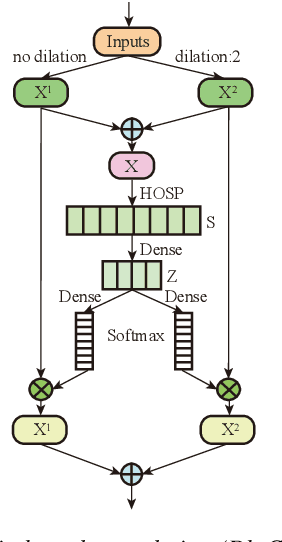

Time Delay Neural Networks (TDNN)-based methods are widely used in dialect identification. However, in previous work with TDNN application, subtle variant is being neglected in different feature scales. To address this issue, we propose a new architecture, named dynamic multi-scale convolution, which consists of dynamic kernel convolution, local multi-scale learning, and global multi-scale pooling. Dynamic kernel convolution captures features between short-term and long-term context adaptively. Local multi-scale learning, which represents multi-scale features at a granular level, is able to increase the range of receptive fields for convolution operation. Besides, global multi-scale pooling is applied to aggregate features from different bottleneck layers in order to collect information from multiple aspects. The proposed architecture significantly outperforms state-of-the-art system on the AP20-OLR-dialect-task of oriental language recognition (OLR) challenge 2020, with the best average cost performance (Cavg) of 0.067 and the best equal error rate (EER) of 6.52%. Compared with the known best results, our method achieves 9% of Cavg and 45% of EER relative improvement, respectively. Furthermore, the parameters of proposed model are 91% fewer than the best known model.