 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-Codec: Dual-Stage Training with Mirror-to-NonMirror Architecture Switching for Speech Codec
May 30, 2025Neural speech codecs are essential for advancing text-to-speech (TTS) systems. With the recent success of large language models in text generation, developing high-quality speech tokenizers has become increasingly important. This paper introduces DS-Codec, a novel neural speech codec featuring a dual-stage training framework with mirror and non-mirror architectures switching, designed to achieve superior speech reconstruction. We conduct extensive experiments and ablation studies to evaluate the effectiveness of our training strategy and compare the performance of the two architectures. Our results show that the mirrored structure significantly enhances the robustness of the learned codebooks, and the training strategy balances the advantages between mirrored and non-mirrored structures, leading to improved high-fidelity speech reconstruction.
Discl-VC: Disentangled Discrete Tokens and In-Context Learning for Controllable Zero-Shot Voice Conversion
May 30, 2025Currently, zero-shot voice conversion systems are capable of synthesizing the voice of unseen speakers. However, most existing approaches struggle to accurately replicate the speaking style of the source speaker or mimic the distinctive speaking style of the target speaker, thereby limiting the controllability of voice conversion. In this work, we propose Discl-VC, a novel voice conversion framework that disentangles content and prosody information from self-supervised speech representations and synthesizes the target speaker's voice through in-context learning with a flow matching transformer. To enable precise control over the prosody of generated speech, we introduce a mask generative transformer that predicts discrete prosody tokens in a non-autoregressive manner based on prompts. Experimental results demonstrate the superior performance of Discl-VC in zero-shot voice conversion and its remarkable accuracy in prosody control for synthesized speech.
Boosting Code-Switching ASR with Mixture of Experts Enhanced Speech-Conditioned LLM
Sep 24, 2024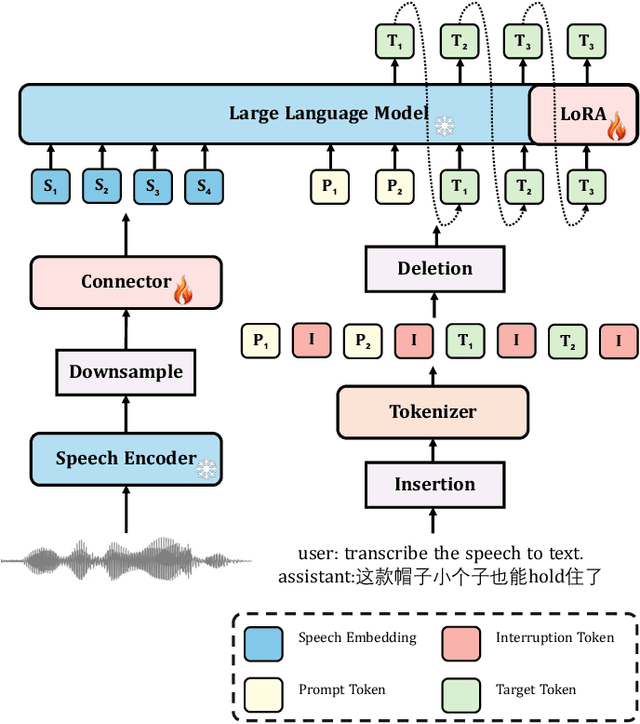
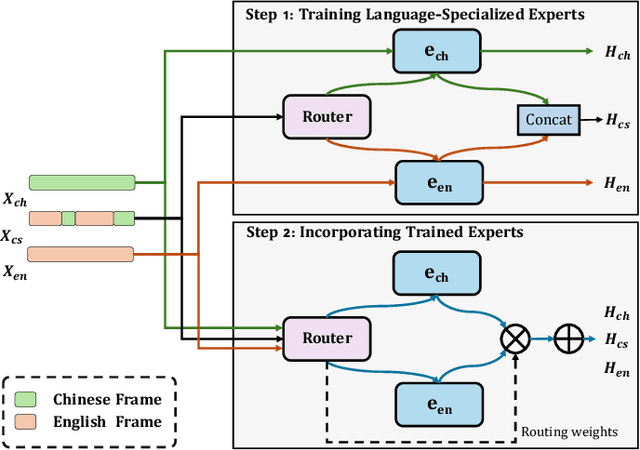
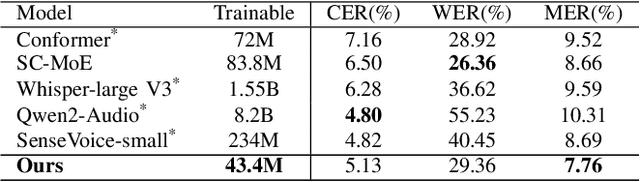

In this paper, we introduce a speech-conditioned Large Language Model (LLM) integrated with a Mixture of Experts (MoE) based connector to address the challenge of Code-Switching (CS) in Automatic Speech Recognition (ASR). Specifically, we propose an Insertion and Deletion of Interruption Token (IDIT) mechanism for better transfer text generation ability of LLM to speech recognition task. We also present a connecter with MoE architecture that manages multiple languages efficiently. To further enhance the collaboration of multiple experts and leverage the understanding capabilities of LLM, we propose a two-stage progressive training strategy: 1) The connector is unfrozen and trained with language-specialized experts to map speech representations to the text space. 2) The connector and LLM LoRA adaptor are trained with the proposed IDIT mechanism and all experts are activated to learn general representations. Experimental results demonstrate that our method significantly outperforms state-of-the-art models, including end-to-end and large-scale audio-language models.
Dynamic Language Group-Based MoE: Enhancing Efficiency and Flexibility for Code-Switching Speech Recognition
Jul 26, 2024



The Mixture of Experts (MoE) approach is ideally suited for tackling multilingual and code-switching (CS) challenges due to its multi-expert architecture. This work introduces the DLG-MoE, which is optimized for bilingual and CS scenarios. Our novel Dynamic Language Group-based MoE layer features a language router with shared weights for explicit language modeling, while independent unsupervised routers within the language group handle attributes beyond language. This structure not only enhances expert extension capabilities but also supports dynamic top-k training, allowing for flexible inference across various top-k values and improving overall performance. The model requires no pre-training and supports streaming recognition, achieving state-of-the-art (SOTA) results with unmatched flexibility compared to other methods. The Code will be released.
MM-TTS: Multi-modal Prompt based Style Transfer for Expressive Text-to-Speech Synthesis
Dec 28, 2023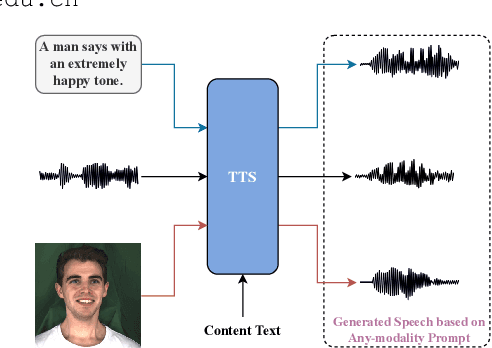
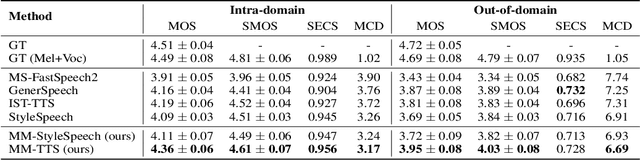
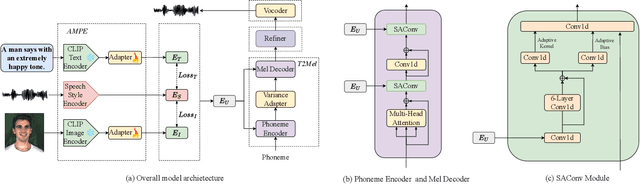
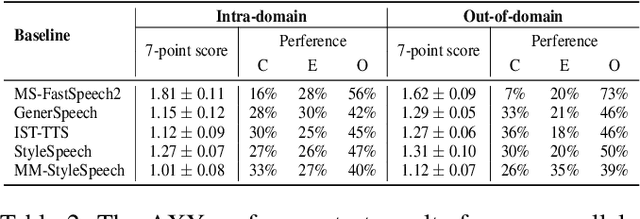
The style transfer task in Text-to-Speech refers to the process of transferring style information into text content to generate corresponding speech with a specific style. However, most existing style transfer approaches are either based on fixed emotional labels or reference speech clips, which cannot achieve flexible style transfer. Recently, some methods have adopted text descriptions to guide style transfer. In this paper, we propose a more flexible multi-modal and style controllable TTS framework named MM-TTS. It can utilize any modality as the prompt in unified multi-modal prompt space, including reference speech, emotional facial images, and text descriptions, to control the style of the generated speech in a system. The challenges of modeling such a multi-modal style controllable TTS mainly lie in two aspects:1)aligning the multi-modal information into a unified style space to enable the input of arbitrary modality as the style prompt in a single system, and 2)efficiently transferring the unified style representation into the given text content, thereby empowering the ability to generate prompt style-related voice. To address these problems, we propose an aligned multi-modal prompt encoder that embeds different modalities into a unified style space, supporting style transfer for different modalities. Additionally, we present a new adaptive style transfer method named Style Adaptive Convolutions to achieve a better style representation. Furthermore, we design a Rectified Flow based Refiner to solve the problem of over-smoothing Mel-spectrogram and generate audio of higher fidelity. Since there is no public dataset for multi-modal TTS, we construct a dataset named MEAD-TTS, which is related to the field of expressive talking head. Our experiments on the MEAD-TTS dataset and out-of-domain datasets demonstrate that MM-TTS can achieve satisfactory results based on multi-modal prompts.
Interpretable Style Transfer for Text-to-Speech with ControlVAE and Diffusion Bridge
Jun 07, 2023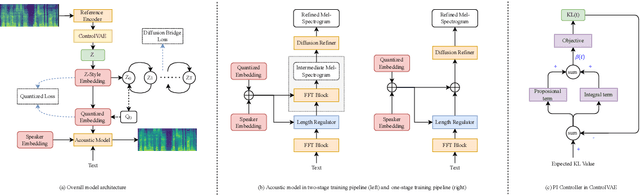
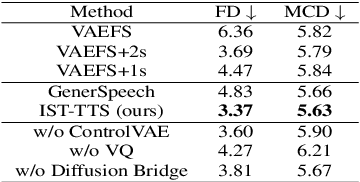
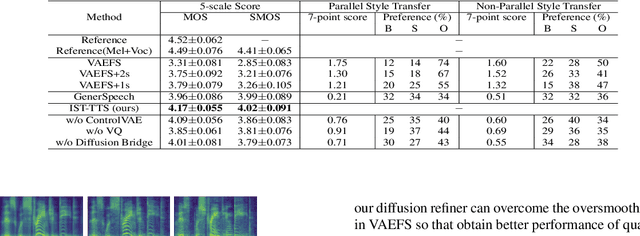
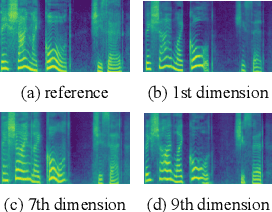
With the demand for autonomous control and personalized speech generation, the style control and transfer in Text-to-Speech (TTS) is becoming more and more important. In this paper, we propose a new TTS system that can perform style transfer with interpretability and high fidelity. Firstly, we design a TTS system that combines variational autoencoder (VAE) and diffusion refiner to get refined mel-spectrograms. Specifically, a two-stage and a one-stage system are designed respectively, to improve the audio quality and the performance of style transfer. Secondly, a diffusion bridge of quantized VAE is designed to efficiently learn complex discrete style representations and improve the performance of style transfer. To have a better ability of style transfer, we introduce ControlVAE to improve the reconstruction quality and have good interpretability simultaneously. Experiments on LibriTTS dataset demonstrate that our method is more effective than baseline models.