 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliDubber: Holistic Video Dubbing for Complex Acoustic Scenes via Text-Guided Audio Synthesis
Jun 08, 2026Video dubbing is a cornerstone of multimedia content creation, aiming to synthesize synchronized acoustic sequences for visual streams. While Text-to-Speech (TTS) and Text-to-Audio (TTA) generation have each achieved remarkable progress, existing dubbing systems remain confined to isolated speech synthesis without incorporating sound effects and ambient audio, forcing practitioners to rely on fragmented workflows and laborious manual post-mixing. To address this limitation, we present HoliDubber, a holistic video dubbing framework that moves beyond speech-only generation by enabling the joint synthesis of speech and sound effects from a single text prompt. Specifically, HoliDubber adopts a patch-based autoregressive diffusion transformer architecture, where a causal language model autoregressively models aggregated patch embeddings to capture global temporal structure, and a Diffusion Transformer decoder generates high-fidelity continuous tokens within each patch, following a divide-and-conquer strategy. To achieve cross-modal alignment, visual features are encoded into patch-level representations and fused with audio patches via cross-attention, enabling the model to ground speech generation in the speaker's visual articulation dynamics. In addition, we introduce HoliDub-Bench, a benchmark curated from established datasets with synchronized video-text-audio triplets designed for holistic dubbing evaluation. Extensive experiments demonstrate that HoliDubber significantly outperforms existing methods across multiple benchmarks in speech quality, synchronization, and speaker similarity. Furthermore, results on HoliDub-Bench validate the effectiveness of joint speech-and-sound generation, establishing a new paradigm for holistic video dubbing in complex acoustic scenes. \footnote{The demo page of the project is https://holidubber.github.io}
AlphaFlowTSE: One-Step Generative Target Speaker Extraction via Conditional AlphaFlow
Mar 11, 2026In target speaker extraction (TSE), we aim to recover target speech from a multi-talker mixture using a short enrollment utterance as reference. Recent studies on diffusion and flow-matching generators have improved target-speech fidelity. However, multi-step sampling increases latency, and one-step solutions often rely on a mixture-dependent time coordinate that can be unreliable for real-world conversations. We present AlphaFlowTSE, a one-step conditional generative model trained with a Jacobian-vector product (JVP)-free AlphaFlow objective. AlphaFlowTSE learns mean-velocity transport along a mixture-to-target trajectory starting from the observed mixture, eliminating auxiliary mixing-ratio prediction, and stabilizes training by combining flow matching with an interval-consistency teacher-student target. Experiments on Libri2Mix and REAL-T confirm that AlphaFlowTSE improves target-speaker similarity and real-mixture generalization for downstream automatic speech recognition (ASR).
UniVoice: Unifying Autoregressive ASR and Flow-Matching based TTS with Large Language Models
Oct 06, 2025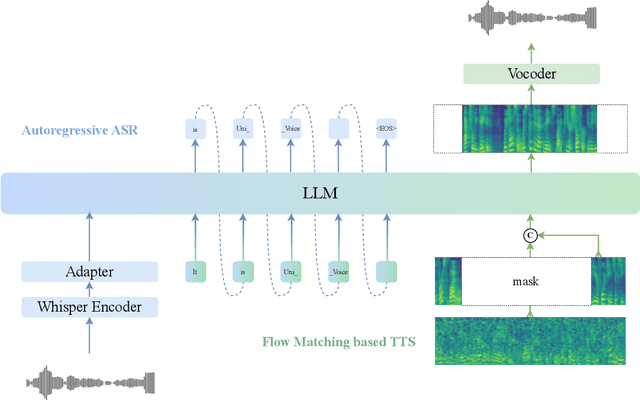
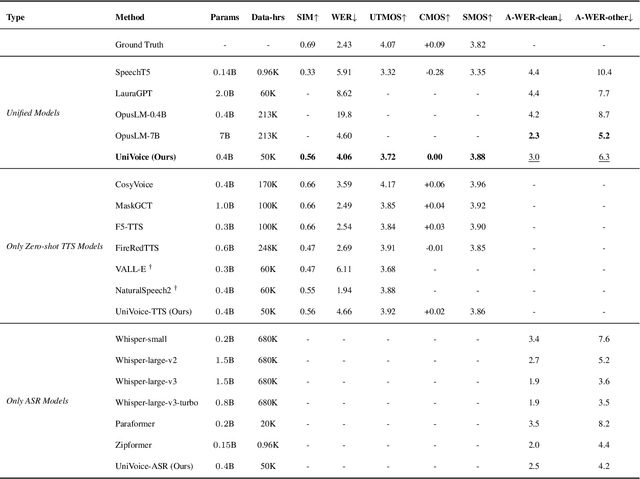
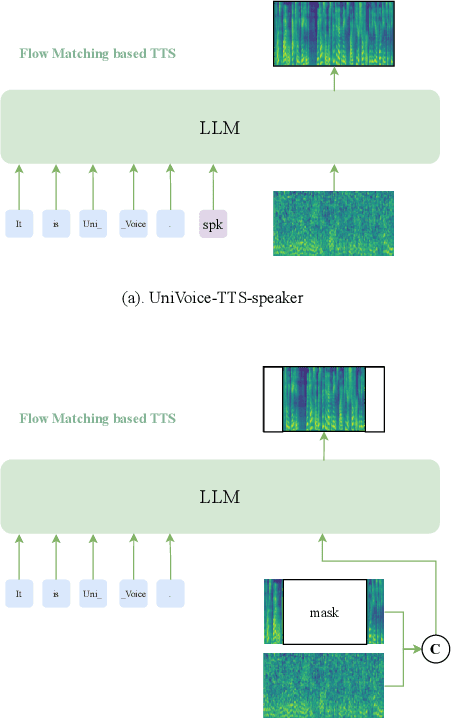

Large language models (LLMs) have demonstrated promising performance in both automatic speech recognition (ASR) and text-to-speech (TTS) systems, gradually becoming the mainstream approach. However, most current approaches address these tasks separately rather than through a unified framework. This work aims to integrate these two tasks into one unified model. Although discrete speech tokenization enables joint modeling, its inherent information loss limits performance in both recognition and generation. In this work, we present UniVoice, a unified LLM framework through continuous representations that seamlessly integrates speech recognition and synthesis within a single model. Our approach combines the strengths of autoregressive modeling for speech recognition with flow matching for high-quality generation. To mitigate the inherent divergence between autoregressive and flow-matching models, we further design a dual attention mechanism, which switches between a causal mask for recognition and a bidirectional attention mask for synthesis. Furthermore, the proposed text-prefix-conditioned speech infilling method enables high-fidelity zero-shot voice cloning. Experimental results demonstrate that our method can achieve or exceed current single-task modeling methods in both ASR and zero-shot TTS tasks. This work explores new possibilities for end-to-end speech understanding and generation.
MeanFlowSE: one-step generative speech enhancement via conditional mean flow
Sep 18, 2025


Multistep inference is a bottleneck for real-time generative speech enhancement because flow- and diffusion-based systems learn an instantaneous velocity field and therefore rely on iterative ordinary differential equation (ODE) solvers. We introduce MeanFlowSE, a conditional generative model that learns the average velocity over finite intervals along a trajectory. Using a Jacobian-vector product (JVP) to instantiate the MeanFlow identity, we derive a local training objective that directly supervises finite-interval displacement while remaining consistent with the instantaneous-field constraint on the diagonal. At inference, MeanFlowSE performs single-step generation via a backward-in-time displacement, removing the need for multistep solvers; an optional few-step variant offers additional refinement. On VoiceBank-DEMAND, the single-step model achieves strong intelligibility, fidelity, and perceptual quality with substantially lower computational cost than multistep baselines. The method requires no knowledge distillation or external teachers, providing an efficient, high-fidelity framework for real-time generative speech enhancement.
SuPseudo: A Pseudo-supervised Learning Method for Neural Speech Enhancement in Far-field Speech Recognition
May 30, 2025Due to the lack of target speech annotations in real-recorded far-field conversational datasets, speech enhancement (SE) models are typically trained on simulated data. However, the trained models often perform poorly in real-world conditions, hindering their application in far-field speech recognition. To address the issue, we (a) propose direct sound estimation (DSE) to estimate the oracle direct sound of real-recorded data for SE; and (b) present a novel pseudo-supervised learning method, SuPseudo, which leverages DSE-estimates as pseudo-labels and enables SE models to directly learn from and adapt to real-recorded data, thereby improving their generalization capability. Furthermore, an SE model called FARNET is designed to fully utilize SuPseudo. Experiments on the MISP2023 corpus demonstrate the effectiveness of SuPseudo, and our system significantly outperforms the previous state-of-the-art. A demo of our method can be found at https://EeLLJ.github.io/SuPseudo/.
Pseudo Labels-based Neural Speech Enhancement for the AVSR Task in the MISP-Meeting Challenge
May 30, 2025This paper presents our system for the MISP-Meeting Challenge Track 2. The primary difficulty lies in the dataset, which contains strong background noise, reverberation, overlapping speech, and diverse meeting topics. To address these issues, we (a) designed G-SpatialNet, a speech enhancement (SE) model to improve Guided Source Separation (GSS) signals; (b) proposed TLS, a framework comprising time alignment, level alignment, and signal-to-noise ratio filtering, to generate signal-level pseudo labels for real-recorded far-field audio data, thereby facilitating SE models' training; and (c) explored fine-tuning strategies, data augmentation, and multimodal information to enhance the performance of pre-trained Automatic Speech Recognition (ASR) models in meeting scenarios. Finally, our system achieved character error rates (CERs) of 5.44% and 9.52% on the Dev and Eval sets, respectively, with relative improvements of 64.8% and 52.6% over the baseline, securing second place.
Discl-VC: Disentangled Discrete Tokens and In-Context Learning for Controllable Zero-Shot Voice Conversion
May 30, 2025Currently, zero-shot voice conversion systems are capable of synthesizing the voice of unseen speakers. However, most existing approaches struggle to accurately replicate the speaking style of the source speaker or mimic the distinctive speaking style of the target speaker, thereby limiting the controllability of voice conversion. In this work, we propose Discl-VC, a novel voice conversion framework that disentangles content and prosody information from self-supervised speech representations and synthesizes the target speaker's voice through in-context learning with a flow matching transformer. To enable precise control over the prosody of generated speech, we introduce a mask generative transformer that predicts discrete prosody tokens in a non-autoregressive manner based on prompts. Experimental results demonstrate the superior performance of Discl-VC in zero-shot voice conversion and its remarkable accuracy in prosody control for synthesized speech.
DS-Codec: Dual-Stage Training with Mirror-to-NonMirror Architecture Switching for Speech Codec
May 30, 2025Neural speech codecs are essential for advancing text-to-speech (TTS) systems. With the recent success of large language models in text generation, developing high-quality speech tokenizers has become increasingly important. This paper introduces DS-Codec, a novel neural speech codec featuring a dual-stage training framework with mirror and non-mirror architectures switching, designed to achieve superior speech reconstruction. We conduct extensive experiments and ablation studies to evaluate the effectiveness of our training strategy and compare the performance of the two architectures. Our results show that the mirrored structure significantly enhances the robustness of the learned codebooks, and the training strategy balances the advantages between mirrored and non-mirrored structures, leading to improved high-fidelity speech reconstruction.
SlimSpeech: Lightweight and Efficient Text-to-Speech with Slim Rectified Flow
Apr 10, 2025Recently, flow matching based speech synthesis has significantly enhanced the quality of synthesized speech while reducing the number of inference steps. In this paper, we introduce SlimSpeech, a lightweight and efficient speech synthesis system based on rectified flow. We have built upon the existing speech synthesis method utilizing the rectified flow model, modifying its structure to reduce parameters and serve as a teacher model. By refining the reflow operation, we directly derive a smaller model with a more straight sampling trajectory from the larger model, while utilizing distillation techniques to further enhance the model performance. Experimental results demonstrate that our proposed method, with significantly reduced model parameters, achieves comparable performance to larger models through one-step sampling.
Dynamic Language Group-Based MoE: Enhancing Efficiency and Flexibility for Code-Switching Speech Recognition
Jul 26, 2024



The Mixture of Experts (MoE) approach is ideally suited for tackling multilingual and code-switching (CS) challenges due to its multi-expert architecture. This work introduces the DLG-MoE, which is optimized for bilingual and CS scenarios. Our novel Dynamic Language Group-based MoE layer features a language router with shared weights for explicit language modeling, while independent unsupervised routers within the language group handle attributes beyond language. This structure not only enhances expert extension capabilities but also supports dynamic top-k training, allowing for flexible inference across various top-k values and improving overall performance. The model requires no pre-training and supports streaming recognition, achieving state-of-the-art (SOTA) results with unmatched flexibility compared to other methods. The Code will be released.