 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscl-VC: Disentangled Discrete Tokens and In-Context Learning for Controllable Zero-Shot Voice Conversion
May 30, 2025Currently, zero-shot voice conversion systems are capable of synthesizing the voice of unseen speakers. However, most existing approaches struggle to accurately replicate the speaking style of the source speaker or mimic the distinctive speaking style of the target speaker, thereby limiting the controllability of voice conversion. In this work, we propose Discl-VC, a novel voice conversion framework that disentangles content and prosody information from self-supervised speech representations and synthesizes the target speaker's voice through in-context learning with a flow matching transformer. To enable precise control over the prosody of generated speech, we introduce a mask generative transformer that predicts discrete prosody tokens in a non-autoregressive manner based on prompts. Experimental results demonstrate the superior performance of Discl-VC in zero-shot voice conversion and its remarkable accuracy in prosody control for synthesized speech.
DS-Codec: Dual-Stage Training with Mirror-to-NonMirror Architecture Switching for Speech Codec
May 30, 2025Neural speech codecs are essential for advancing text-to-speech (TTS) systems. With the recent success of large language models in text generation, developing high-quality speech tokenizers has become increasingly important. This paper introduces DS-Codec, a novel neural speech codec featuring a dual-stage training framework with mirror and non-mirror architectures switching, designed to achieve superior speech reconstruction. We conduct extensive experiments and ablation studies to evaluate the effectiveness of our training strategy and compare the performance of the two architectures. Our results show that the mirrored structure significantly enhances the robustness of the learned codebooks, and the training strategy balances the advantages between mirrored and non-mirrored structures, leading to improved high-fidelity speech reconstruction.
InstructSAM: A Training-Free Framework for Instruction-Oriented Remote Sensing Object Recognition
May 21, 2025Language-Guided object recognition in remote sensing imagery is crucial for large-scale mapping and automated data annotation. However, existing open-vocabulary and visual grounding methods rely on explicit category cues, limiting their ability to handle complex or implicit queries that require advanced reasoning. To address this issue, we introduce a new suite of tasks, including Instruction-Oriented Object Counting, Detection, and Segmentation (InstructCDS), covering open-vocabulary, open-ended, and open-subclass scenarios. We further present EarthInstruct, the first InstructCDS benchmark for earth observation. It is constructed from two diverse remote sensing datasets with varying spatial resolutions and annotation rules across 20 categories, necessitating models to interpret dataset-specific instructions. Given the scarcity of semantically rich labeled data in remote sensing, we propose InstructSAM, a training-free framework for instruction-driven object recognition. InstructSAM leverages large vision-language models to interpret user instructions and estimate object counts, employs SAM2 for mask proposal, and formulates mask-label assignment as a binary integer programming problem. By integrating semantic similarity with counting constraints, InstructSAM efficiently assigns categories to predicted masks without relying on confidence thresholds. Experiments demonstrate that InstructSAM matches or surpasses specialized baselines across multiple tasks while maintaining near-constant inference time regardless of object count, reducing output tokens by 89% and overall runtime by over 32% compared to direct generation approaches. We believe the contributions of the proposed tasks, benchmark, and effective approach will advance future research in developing versatile object recognition systems.
When SAM Meets Sonar Images
Jun 25, 2023Segment Anything Model (SAM) has revolutionized the way of segmentation. However, SAM's performance may decline when applied to tasks involving domains that differ from natural images. Nonetheless, by employing fine-tuning techniques, SAM exhibits promising capabilities in specific domains, such as medicine and planetary science. Notably, there is a lack of research on the application of SAM to sonar imaging. In this paper, we aim to address this gap by conducting a comprehensive investigation of SAM's performance on sonar images. Specifically, we evaluate SAM using various settings on sonar images. Additionally, we fine-tune SAM using effective methods both with prompts and for semantic segmentation, thereby expanding its applicability to tasks requiring automated segmentation. Experimental results demonstrate a significant improvement in the performance of the fine-tuned SAM.
Cheap-fake Detection with LLM using Prompt Engineering
Jun 05, 2023The misuse of real photographs with conflicting image captions in news items is an example of the out-of-context (OOC) misuse of media. In order to detect OOC media, individuals must determine the accuracy of the statement and evaluate whether the triplet (~\textit{i.e.}, the image and two captions) relates to the same event. This paper presents a novel learnable approach for detecting OOC media in ICME'23 Grand Challenge on Detecting Cheapfakes. The proposed method is based on the COSMOS structure, which assesses the coherence between an image and captions, as well as between two captions. We enhance the baseline algorithm by incorporating a Large Language Model (LLM), GPT3.5, as a feature extractor. Specifically, we propose an innovative approach to feature extraction utilizing prompt engineering to develop a robust and reliable feature extractor with GPT3.5 model. The proposed method captures the correlation between two captions and effectively integrates this module into the COSMOS baseline model, which allows for a deeper understanding of the relationship between captions. By incorporating this module, we demonstrate the potential for significant improvements in cheap-fakes detection performance. The proposed methodology holds promising implications for various applications such as natural language processing, image captioning, and text-to-image synthesis. Docker for submission is available at https://hub.docker.com/repository/docker/mulns/ acmmmcheapfakes.
A Lightweight Reconstruction Network for Surface Defect Inspection
Dec 25, 2022Currently, most deep learning methods cannot solve the problem of scarcity of industrial product defect samples and significant differences in characteristics. This paper proposes an unsupervised defect detection algorithm based on a reconstruction network, which is realized using only a large number of easily obtained defect-free sample data. The network includes two parts: image reconstruction and surface defect area detection. The reconstruction network is designed through a fully convolutional autoencoder with a lightweight structure. Only a small number of normal samples are used for training so that the reconstruction network can be A defect-free reconstructed image is generated. A function combining structural loss and $\mathit{L}1$ loss is proposed as the loss function of the reconstruction network to solve the problem of poor detection of irregular texture surface defects. Further, the residual of the reconstructed image and the image to be tested is used as the possible region of the defect, and conventional image operations can realize the location of the fault. The unsupervised defect detection algorithm of the proposed reconstruction network is used on multiple defect image sample sets. Compared with other similar algorithms, the results show that the unsupervised defect detection algorithm of the reconstructed network has strong robustness and accuracy.
* Journal of Mathematical Imaging and Vision(JMIV)
IDMS: Instance Depth for Multi-scale Monocular 3D Object Detection
Dec 03, 2022Due to the lack of depth information of images and poor detection accuracy in monocular 3D object detection, we proposed the instance depth for multi-scale monocular 3D object detection method. Firstly, to enhance the model's processing ability for different scale targets, a multi-scale perception module based on dilated convolution is designed, and the depth features containing multi-scale information are re-refined from both spatial and channel directions considering the inconsistency between feature maps of different scales. Firstly, we designed a multi-scale perception module based on dilated convolution to enhance the model's processing ability for different scale targets. The depth features containing multi-scale information are re-refined from spatial and channel directions considering the inconsistency between feature maps of different scales. Secondly, so as to make the model obtain better 3D perception, this paper proposed to use the instance depth information as an auxiliary learning task to enhance the spatial depth feature of the 3D target and use the sparse instance depth to supervise the auxiliary task. Finally, by verifying the proposed algorithm on the KITTI test set and evaluation set, the experimental results show that compared with the baseline method, the proposed method improves by 5.27\% in AP40 in the car category, effectively improving the detection performance of the monocular 3D object detection algorithm.
* Journal of Machine Learning Research
Data Augmentation Vision Transformer for Fine-grained Image Classification
Nov 24, 2022Recently, the vision transformer (ViT) has made breakthroughs in image recognition. Its self-attention mechanism (MSA) can extract discriminative labeling information of different pixel blocks to improve image classification accuracy. However, the classification marks in their deep layers tend to ignore local features between layers. In addition, the embedding layer will be fixed-size pixel blocks. Input network Inevitably introduces additional image noise. To this end, we study a data augmentation vision transformer (DAVT) based on data augmentation and proposes a data augmentation method for attention cropping, which uses attention weights as the guide to crop images and improve the ability of the network to learn critical features. Secondly, we also propose a hierarchical attention selection (HAS) method, which improves the ability of discriminative markers between levels of learning by filtering and fusing labels between levels. Experimental results show that the accuracy of this method on the two general datasets, CUB-200-2011, and Stanford Dogs, is better than the existing mainstream methods, and its accuracy is 1.4\% and 1.6\% higher than the original ViT, respectively
* IEEE Signal Processing Letters
Spatio-Temporal-based Context Fusion for Video Anomaly Detection
Oct 18, 2022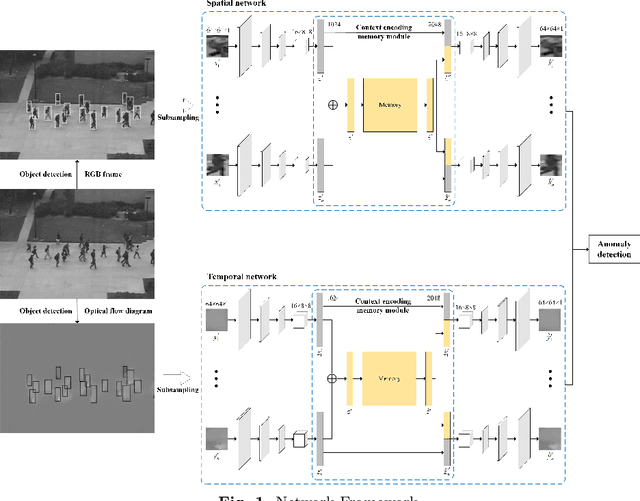
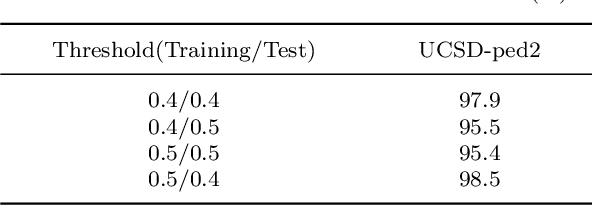
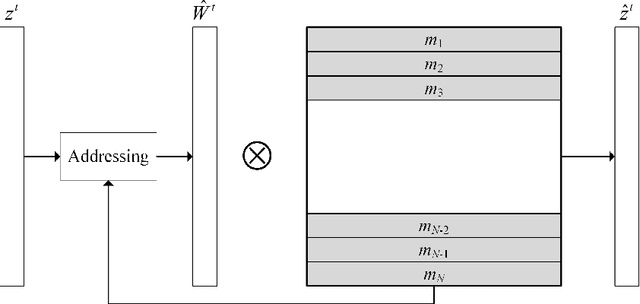
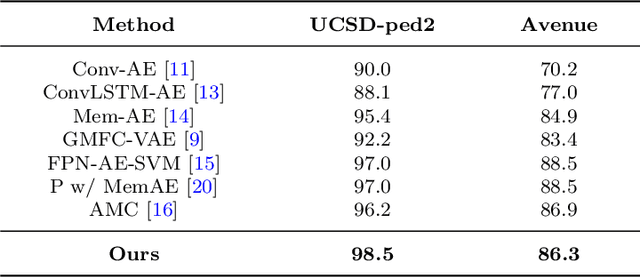
Video anomaly detection aims to discover abnormal events in videos, and the principal objects are target objects such as people and vehicles. Each target in the video data has rich spatio-temporal context information. Most existing methods only focus on the temporal context, ignoring the role of the spatial context in anomaly detection. The spatial context information represents the relationship between the detection target and surrounding targets. Anomaly detection makes a lot of sense. To this end, a video anomaly detection algorithm based on target spatio-temporal context fusion is proposed. Firstly, the target in the video frame is extracted through the target detection network to reduce background interference. Then the optical flow map of two adjacent frames is calculated. Motion features are used multiple targets in the video frame to construct spatial context simultaneously, re-encoding the target appearance and motion features, and finally reconstructing the above features through the spatio-temporal dual-stream network, and using the reconstruction error to represent the abnormal score. The algorithm achieves frame-level AUCs of 98.5% and 86.3% on the UCSDped2 and Avenue datasets, respectively. On the UCSDped2 dataset, the spatio-temporal dual-stream network improves frames by 5.1% and 0.3%, respectively, compared to the temporal and spatial stream networks. After using spatial context encoding, the frame-level AUC is enhanced by 1%, which verifies the method's effectiveness.
Normal Learning in Videos with Attention Prototype Network
Aug 25, 2021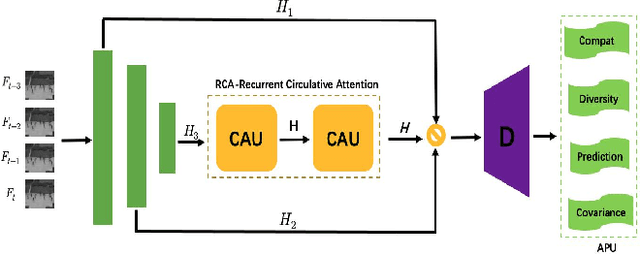
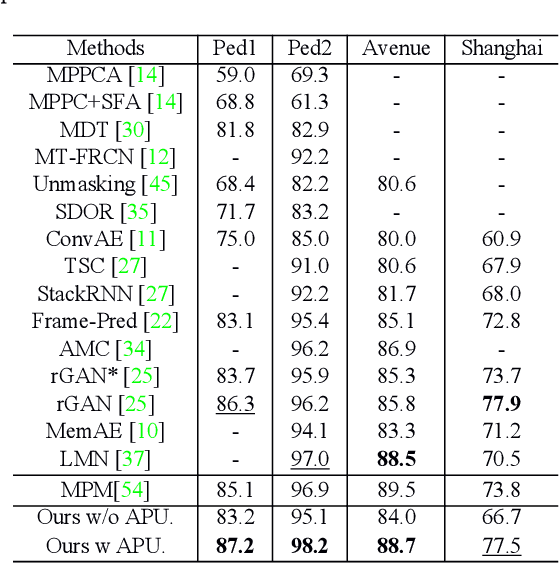
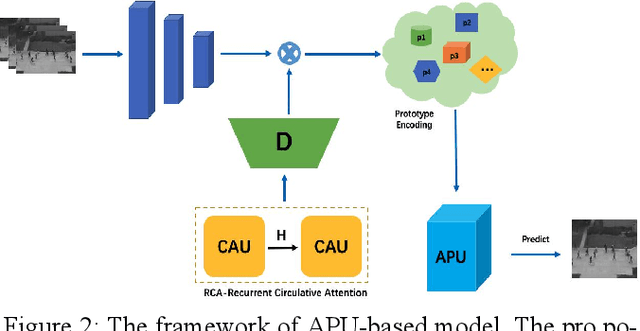
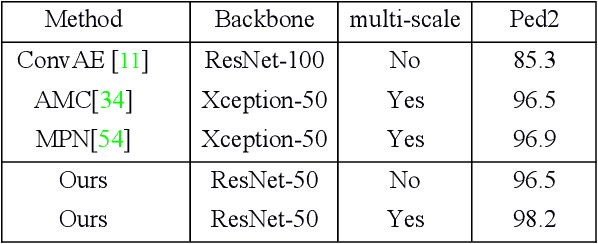
Frame reconstruction (current or future frame) based on Auto-Encoder (AE) is a popular method for video anomaly detection. With models trained on the normal data, the reconstruction errors of anomalous scenes are usually much larger than those of normal ones. Previous methods introduced the memory bank into AE, for encoding diverse normal patterns across the training videos. However, they are memory consuming and cannot cope with unseen new scenarios in the testing data. In this work, we propose a self-attention prototype unit (APU) to encode the normal latent space as prototypes in real time, free from extra memory cost. In addition, we introduce circulative attention mechanism to our backbone to form a novel feature extracting learner, namely Circulative Attention Unit (CAU). It enables the fast adaption capability on new scenes by only consuming a few iterations of update. Extensive experiments are conducted on various benchmarks. The superior performance over the state-of-the-art demonstrates the effectiveness of our method. Our code is available at https://github.com/huchao-AI/APN/.