 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOS-Symphony: A Holistic Framework for Robust and Generalist Computer-Using Agent
Jan 12, 2026While Vision-Language Models (VLMs) have significantly advanced Computer-Using Agents (CUAs), current frameworks struggle with robustness in long-horizon workflows and generalization in novel domains. These limitations stem from a lack of granular control over historical visual context curation and the absence of visual-aware tutorial retrieval. To bridge these gaps, we introduce OS-Symphony, a holistic framework that comprises an Orchestrator coordinating two key innovations for robust automation: (1) a Reflection-Memory Agent that utilizes milestone-driven long-term memory to enable trajectory-level self-correction, effectively mitigating visual context loss in long-horizon tasks; (2) Versatile Tool Agents featuring a Multimodal Searcher that adopts a SeeAct paradigm to navigate a browser-based sandbox to synthesize live, visually aligned tutorials, thereby resolving fidelity issues in unseen scenarios. Experimental results demonstrate that OS-Symphony delivers substantial performance gains across varying model scales, establishing new state-of-the-art results on three online benchmarks, notably achieving 65.84% on OSWorld.
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Sep 18, 2025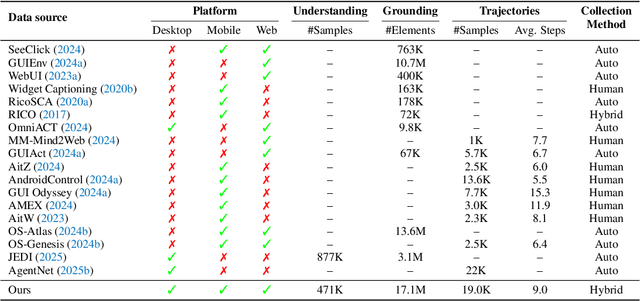
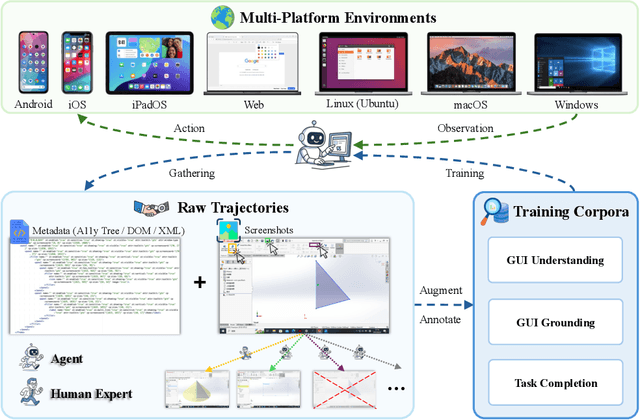
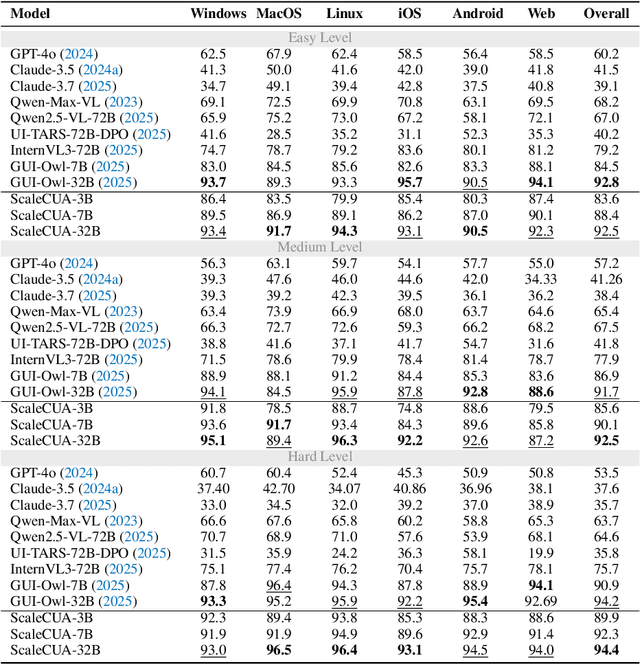
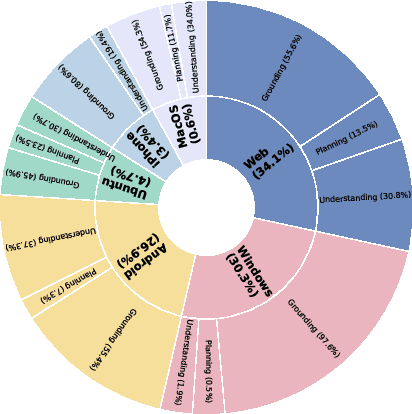
Vision-Language Models (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously, showing great potential, yet progress is limited by the lack of large-scale, open-source computer use data and foundation models. In this work, we introduce ScaleCUA, a step toward scaling open-source CUAs. It offers a large-scale dataset spanning 6 operating systems and 3 task domains, built via a closed-loop pipeline uniting automated agents with human experts. Trained on this scaled-up data, ScaleCUA can operate seamlessly across platforms. Specifically, it delivers strong gains over baselines (+26.6 on WebArena-Lite-v2, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art results (94.4% on MMBench-GUI L1-Hard, 60.6% on OSWorld-G, 47.4% on WebArena-Lite-v2). These findings underscore the power of data-driven scaling for general-purpose computer use agents. We will release data, models, and code to advance future research: https://github.com/OpenGVLab/ScaleCUA.
Tool-R1: Sample-Efficient Reinforcement Learning for Agentic Tool Use
Sep 16, 2025Large language models (LLMs) have demonstrated strong capabilities in language understanding and reasoning, yet they remain limited when tackling real-world tasks that require up-to-date knowledge, precise operations, or specialized tool use. To address this, we propose Tool-R1, a reinforcement learning framework that enables LLMs to perform general, compositional, and multi-step tool use by generating executable Python code. Tool-R1 supports integration of user-defined tools and standard libraries, with variable sharing across steps to construct coherent workflows. An outcome-based reward function, combining LLM-based answer judgment and code execution success, guides policy optimization. To improve training efficiency, we maintain a dynamic sample queue to cache and reuse high-quality trajectories, reducing the overhead of costly online sampling. Experiments on the GAIA benchmark show that Tool-R1 substantially improves both accuracy and robustness, achieving about 10\% gain over strong baselines, with larger improvements on complex multi-step tasks. These results highlight the potential of Tool-R1 for enabling reliable and efficient tool-augmented reasoning in real-world applications. Our code will be available at https://github.com/YBYBZhang/Tool-R1.
GLEAM: Learning to Match and Explain in Cross-View Geo-Localization
Sep 09, 2025Cross-View Geo-Localization (CVGL) focuses on identifying correspondences between images captured from distinct perspectives of the same geographical location. However, existing CVGL approaches are typically restricted to a single view or modality, and their direct visual matching strategy lacks interpretability: they merely predict whether two images correspond, without explaining the rationale behind the match. In this paper, we present GLEAM-C, a foundational CVGL model that unifies multiple views and modalities-including UAV imagery, street maps, panoramic views, and ground photographs-by aligning them exclusively with satellite imagery. Our framework enhances training efficiency through optimized implementation while achieving accuracy comparable to prior modality-specific CVGL models through a two-phase training strategy. Moreover, to address the lack of interpretability in traditional CVGL methods, we leverage the reasoning capabilities of multimodal large language models (MLLMs) to propose a new task, GLEAM-X, which combines cross-view correspondence prediction with explainable reasoning. To support this task, we construct a bilingual benchmark using GPT-4o and Doubao-1.5-Thinking-Vision-Pro to generate training and testing data. The test set is further refined through detailed human revision, enabling systematic evaluation of explainable cross-view reasoning and advancing transparency and scalability in geo-localization. Together, GLEAM-C and GLEAM-X form a comprehensive CVGL pipeline that integrates multi-modal, multi-view alignment with interpretable correspondence analysis, unifying accurate cross-view matching with explainable reasoning and advancing Geo-Localization by enabling models to better Explain And Match. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/GLEAM.
InstructSAM: A Training-Free Framework for Instruction-Oriented Remote Sensing Object Recognition
May 21, 2025Language-Guided object recognition in remote sensing imagery is crucial for large-scale mapping and automated data annotation. However, existing open-vocabulary and visual grounding methods rely on explicit category cues, limiting their ability to handle complex or implicit queries that require advanced reasoning. To address this issue, we introduce a new suite of tasks, including Instruction-Oriented Object Counting, Detection, and Segmentation (InstructCDS), covering open-vocabulary, open-ended, and open-subclass scenarios. We further present EarthInstruct, the first InstructCDS benchmark for earth observation. It is constructed from two diverse remote sensing datasets with varying spatial resolutions and annotation rules across 20 categories, necessitating models to interpret dataset-specific instructions. Given the scarcity of semantically rich labeled data in remote sensing, we propose InstructSAM, a training-free framework for instruction-driven object recognition. InstructSAM leverages large vision-language models to interpret user instructions and estimate object counts, employs SAM2 for mask proposal, and formulates mask-label assignment as a binary integer programming problem. By integrating semantic similarity with counting constraints, InstructSAM efficiently assigns categories to predicted masks without relying on confidence thresholds. Experiments demonstrate that InstructSAM matches or surpasses specialized baselines across multiple tasks while maintaining near-constant inference time regardless of object count, reducing output tokens by 89% and overall runtime by over 32% compared to direct generation approaches. We believe the contributions of the proposed tasks, benchmark, and effective approach will advance future research in developing versatile object recognition systems.
Keeping Yourself is Important in Downstream Tuning Multimodal Large Language Model
Mar 06, 2025Multi-modal Large Language Models (MLLMs) integrate visual and linguistic reasoning to address complex tasks such as image captioning and visual question answering. While MLLMs demonstrate remarkable versatility, MLLMs appears limited performance on special applications. But tuning MLLMs for downstream tasks encounters two key challenges: Task-Expert Specialization, where distribution shifts between pre-training and target datasets constrain target performance, and Open-World Stabilization, where catastrophic forgetting erases the model general knowledge. In this work, we systematically review recent advancements in MLLM tuning methodologies, classifying them into three paradigms: (I) Selective Tuning, (II) Additive Tuning, and (III) Reparameterization Tuning. Furthermore, we benchmark these tuning strategies across popular MLLM architectures and diverse downstream tasks to establish standardized evaluation analysis and systematic tuning principles. Finally, we highlight several open challenges in this domain and propose future research directions. To facilitate ongoing progress in this rapidly evolving field, we provide a public repository that continuously tracks developments: https://github.com/WenkeHuang/Awesome-MLLM-Tuning.
EgoTextVQA: Towards Egocentric Scene-Text Aware Video Question Answering
Feb 11, 2025We introduce EgoTextVQA, a novel and rigorously constructed benchmark for egocentric QA assistance involving scene text. EgoTextVQA contains 1.5K ego-view videos and 7K scene-text aware questions that reflect real-user needs in outdoor driving and indoor house-keeping activities. The questions are designed to elicit identification and reasoning on scene text in an egocentric and dynamic environment. With EgoTextVQA, we comprehensively evaluate 10 prominent multimodal large language models. Currently, all models struggle, and the best results (Gemini 1.5 Pro) are around 33% accuracy, highlighting the severe deficiency of these techniques in egocentric QA assistance. Our further investigations suggest that precise temporal grounding and multi-frame reasoning, along with high resolution and auxiliary scene-text inputs, are key for better performance. With thorough analyses and heuristic suggestions, we hope EgoTextVQA can serve as a solid testbed for research in egocentric scene-text QA assistance.
PointOBB-v3: Expanding Performance Boundaries of Single Point-Supervised Oriented Object Detection
Jan 23, 2025



With the growing demand for oriented object detection (OOD), recent studies on point-supervised OOD have attracted significant interest. In this paper, we propose PointOBB-v3, a stronger single point-supervised OOD framework. Compared to existing methods, it generates pseudo rotated boxes without additional priors and incorporates support for the end-to-end paradigm. PointOBB-v3 functions by integrating three unique image views: the original view, a resized view, and a rotated/flipped (rot/flp) view. Based on the views, a scale augmentation module and an angle acquisition module are constructed. In the first module, a Scale-Sensitive Consistency (SSC) loss and a Scale-Sensitive Feature Fusion (SSFF) module are introduced to improve the model's ability to estimate object scale. To achieve precise angle predictions, the second module employs symmetry-based self-supervised learning. Additionally, we introduce an end-to-end version that eliminates the pseudo-label generation process by integrating a detector branch and introduces an Instance-Aware Weighting (IAW) strategy to focus on high-quality predictions. We conducted extensive experiments on the DIOR-R, DOTA-v1.0/v1.5/v2.0, FAIR1M, STAR, and RSAR datasets. Across all these datasets, our method achieves an average improvement in accuracy of 3.56% in comparison to previous state-of-the-art methods. The code will be available at https://github.com/ZpyWHU/PointOBB-v3.
A Simple Aerial Detection Baseline of Multimodal Language Models
Jan 16, 2025



The multimodal language models (MLMs) based on generative pre-trained Transformer are considered powerful candidates for unifying various domains and tasks. MLMs developed for remote sensing (RS) have demonstrated outstanding performance in multiple tasks, such as visual question answering and visual grounding. In addition to visual grounding that detects specific objects corresponded to given instruction, aerial detection, which detects all objects of multiple categories, is also a valuable and challenging task for RS foundation models. However, aerial detection has not been explored by existing RS MLMs because the autoregressive prediction mechanism of MLMs differs significantly from the detection outputs. In this paper, we present a simple baseline for applying MLMs to aerial detection for the first time, named LMMRotate. Specifically, we first introduce a normalization method to transform detection outputs into textual outputs to be compatible with the MLM framework. Then, we propose a evaluation method, which ensures a fair comparison between MLMs and conventional object detection models. We construct the baseline by fine-tuning open-source general-purpose MLMs and achieve impressive detection performance comparable to conventional detector. We hope that this baseline will serve as a reference for future MLM development, enabling more comprehensive capabilities for understanding RS images. Code is available at https://github.com/Li-Qingyun/mllm-mmrotate.
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
Dec 06, 2024



We introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality. In this work, we delve into the relationship between model scaling and performance, systematically exploring the performance trends in vision encoders, language models, dataset sizes, and test-time configurations. Through extensive evaluations on a wide range of benchmarks, including multi-discipline reasoning, document understanding, multi-image / video understanding, real-world comprehension, multimodal hallucination detection, visual grounding, multilingual capabilities, and pure language processing, InternVL 2.5 exhibits competitive performance, rivaling leading commercial models such as GPT-4o and Claude-3.5-Sonnet. Notably, our model is the first open-source MLLMs to surpass 70% on the MMMU benchmark, achieving a 3.7-point improvement through Chain-of-Thought (CoT) reasoning and showcasing strong potential for test-time scaling. We hope this model contributes to the open-source community by setting new standards for developing and applying multimodal AI systems. HuggingFace demo see https://huggingface.co/spaces/OpenGVLab/InternVL