 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multi-Robot Global Localization with Unknown Initial Pose based on Neighbor Constraints
Jun 27, 2024
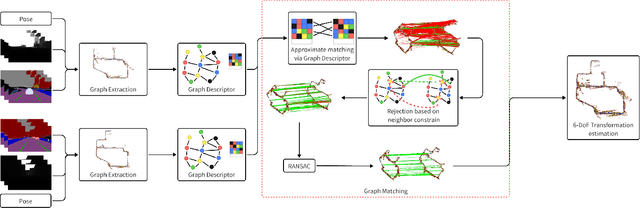

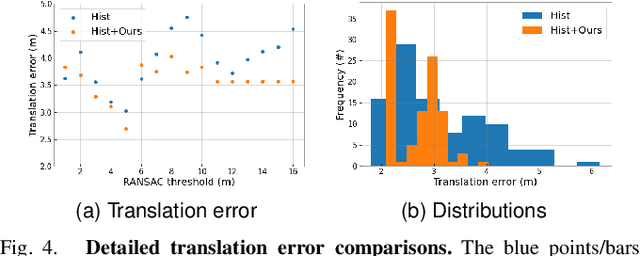
Multi-robot global localization (MR-GL) with unknown initial positions in a large scale environment is a challenging task. The key point is the data association between different robots' viewpoints. It also makes traditional Appearance-based localization methods unusable. Recently, researchers have utilized the object's semantic invariance to generate a semantic graph to address this issue. However, previous works lack robustness and are sensitive to overlap rate of maps, resulting in unpredictable performance in real-world environments. In this paper, we propose a data association algorithm based on neighbor constraints to improve the robustness of the system. We demonstrate the effectiveness of our method on three different datasets, indicating a significant improvement in robustness compared to previous works.
Physics-aware Hand-object Interaction Denoising
May 19, 2024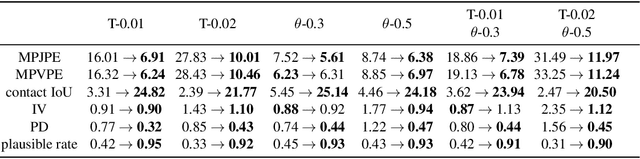
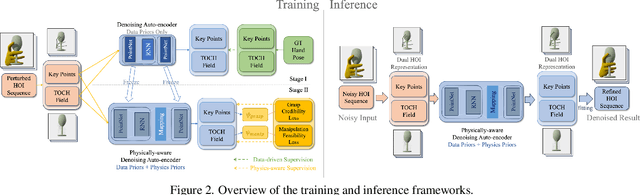


The credibility and practicality of a reconstructed hand-object interaction sequence depend largely on its physical plausibility. However, due to high occlusions during hand-object interaction, physical plausibility remains a challenging criterion for purely vision-based tracking methods. To address this issue and enhance the results of existing hand trackers, this paper proposes a novel physically-aware hand motion de-noising method. Specifically, we introduce two learned loss terms that explicitly capture two crucial aspects of physical plausibility: grasp credibility and manipulation feasibility. These terms are used to train a physically-aware de-noising network. Qualitative and quantitative experiments demonstrate that our approach significantly improves both fine-grained physical plausibility and overall pose accuracy, surpassing current state-of-the-art de-noising methods.
The All-Seeing Project V2: Towards General Relation Comprehension of the Open World
Feb 29, 2024



We present the All-Seeing Project V2: a new model and dataset designed for understanding object relations in images. Specifically, we propose the All-Seeing Model V2 (ASMv2) that integrates the formulation of text generation, object localization, and relation comprehension into a relation conversation (ReC) task. Leveraging this unified task, our model excels not only in perceiving and recognizing all objects within the image but also in grasping the intricate relation graph between them, diminishing the relation hallucination often encountered by Multi-modal Large Language Models (MLLMs). To facilitate training and evaluation of MLLMs in relation understanding, we created the first high-quality ReC dataset ({AS-V2) which is aligned with the format of standard instruction tuning data. In addition, we design a new benchmark, termed Circular-based Relation Probing Evaluation (CRPE) for comprehensively evaluating the relation comprehension capabilities of MLLMs. Notably, our ASMv2 achieves an overall accuracy of 52.04 on this relation-aware benchmark, surpassing the 43.14 of LLaVA-1.5 by a large margin. We hope that our work can inspire more future research and contribute to the evolution towards artificial general intelligence. Our project is released at https://github.com/OpenGVLab/all-seeing.
Active Ensemble Deep Learning for Polarimetric Synthetic Aperture Radar Image Classification
Jun 29, 2020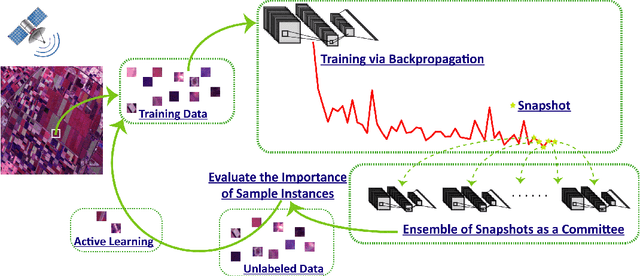

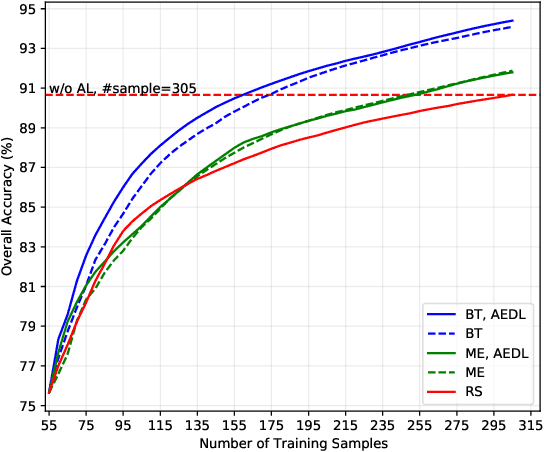

Although deep learning has achieved great success in image classification tasks, its performance is subject to the quantity and quality of training samples. For classification of polarimetric synthetic aperture radar (PolSAR) images, it is nearly impossible to annotate the images from visual interpretation. Therefore, it is urgent for remote sensing scientists to develop new techniques for PolSAR image classification under the condition of very few training samples. In this letter, we take the advantage of active learning and propose active ensemble deep learning (AEDL) for PolSAR image classification. We first show that only 35\% of the predicted labels of a deep learning model's snapshots near its convergence were exactly the same. The disagreement between snapshots is non-negligible. From the perspective of multiview learning, the snapshots together serve as a good committee to evaluate the importance of unlabeled instances. Using the snapshots committee to give out the informativeness of unlabeled data, the proposed AEDL achieved better performance on two real PolSAR images compared with standard active learning strategies. It achieved the same classification accuracy with only 86% and 55% of the training samples compared with breaking ties active learning and random selection for the Flevoland dataset.
Shorten Spatial-spectral RNN with Parallel-GRU for Hyperspectral Image Classification
Oct 30, 2018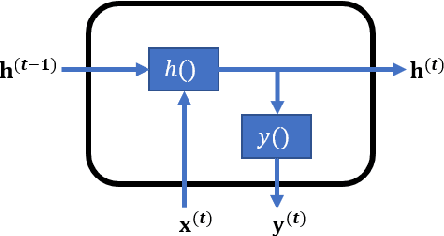
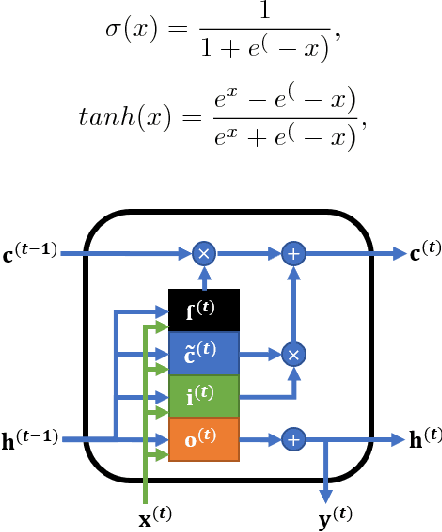
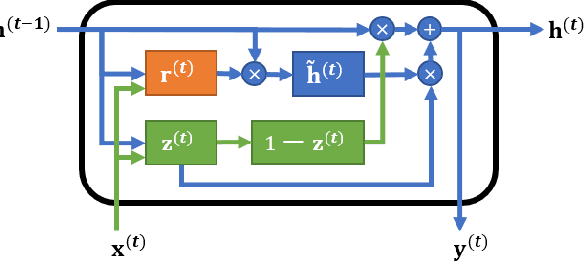
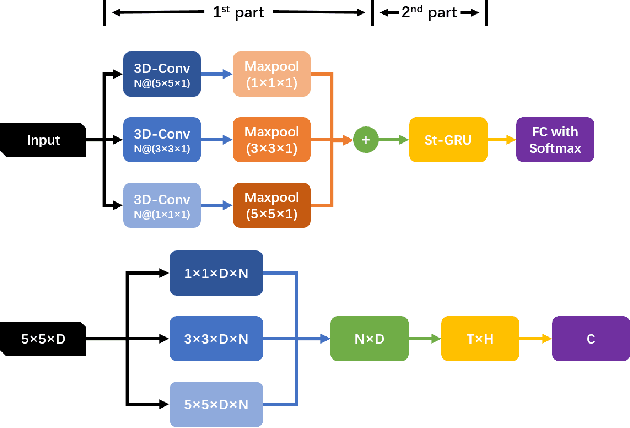
Convolutional neural networks (CNNs) attained a good performance in hyperspectral sensing image (HSI) classification, but CNNs consider spectra as orderless vectors. Therefore, considering the spectra as sequences, recurrent neural networks (RNNs) have been applied in HSI classification, for RNNs is skilled at dealing with sequential data. However, for a long-sequence task, RNNs is difficult for training and not as effective as we expected. Besides, spatial contextual features are not considered in RNNs. In this study, we propose a Shorten Spatial-spectral RNN with Parallel-GRU (St-SS-pGRU) for HSI classification. A shorten RNN is more efficient and easier for training than band-by-band RNN. By combining converlusion layer, the St-SSpGRU model considers not only spectral but also spatial feature, which results in a better performance. An architecture named parallel-GRU is also proposed and applied in St-SS-pGRU. With this architecture, the model gets a better performance and is more robust.