 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
Dec 30, 2025While Vision-Language Models (VLMs) can solve complex tasks through agentic reasoning, their capabilities remain largely constrained to text-oriented chain-of-thought or isolated tool invocation. They fail to exhibit the human-like proficiency required to seamlessly interleave dynamic tool manipulation with continuous reasoning, particularly in knowledge-intensive and visually complex scenarios that demand coordinated external tools such as search and image cropping. In this work, we introduce SenseNova-MARS, a novel Multimodal Agentic Reasoning and Search framework that empowers VLMs with interleaved visual reasoning and tool-use capabilities via reinforcement learning (RL). Specifically, SenseNova-MARS dynamically integrates the image search, text search, and image crop tools to tackle fine-grained and knowledge-intensive visual understanding challenges. In the RL stage, we propose the Batch-Normalized Group Sequence Policy Optimization (BN-GSPO) algorithm to improve the training stability and advance the model's ability to invoke tools and reason effectively. To comprehensively evaluate the agentic VLMs on complex visual tasks, we introduce the HR-MMSearch benchmark, the first search-oriented benchmark composed of high-resolution images with knowledge-intensive and search-driven questions. Experiments demonstrate that SenseNova-MARS achieves state-of-the-art performance on open-source search and fine-grained image understanding benchmarks. Specifically, on search-oriented benchmarks, SenseNova-MARS-8B scores 67.84 on MMSearch and 41.64 on HR-MMSearch, surpassing proprietary models such as Gemini-3-Flash and GPT-5. SenseNova-MARS represents a promising step toward agentic VLMs by providing effective and robust tool-use capabilities. To facilitate further research in this field, we will release all code, models, and datasets.
Towards Fine-Grained Recognition with Large Visual Language Models: Benchmark and Optimization Strategies
Dec 11, 2025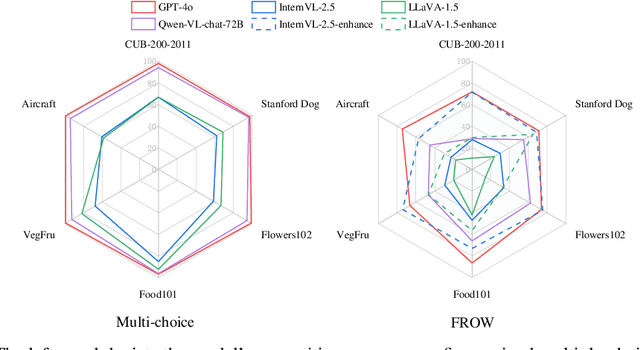



Large Vision Language Models (LVLMs) have made remarkable progress, enabling sophisticated vision-language interaction and dialogue applications. However, existing benchmarks primarily focus on reasoning tasks, often neglecting fine-grained recognition, which is crucial for practical application scenarios. To address this gap, we introduce the Fine-grained Recognition Open World (FROW) benchmark, designed for detailed evaluation of LVLMs with GPT-4o. On the basis of that, we propose a novel optimization strategy from two perspectives: \textit{data construction} and \textit{training process}, to improve the performance of LVLMs. Our dataset includes mosaic data, which combines multiple short-answer responses, and open-world data, generated from real-world questions and answers using GPT-4o, creating a comprehensive framework for evaluating fine-grained recognition in LVLMs. Experiments show that mosaic data improves category recognition accuracy by 1\% and open-world data boosts FROW benchmark accuracy by 10\%-20\% and content accuracy by 6\%-12\%. Meanwhile, incorporating fine-grained data into the pre-training phase can improve the model's category recognition accuracy by up to 10\%. The benchmark will be available at https://github.com/pc-inno/FROW.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
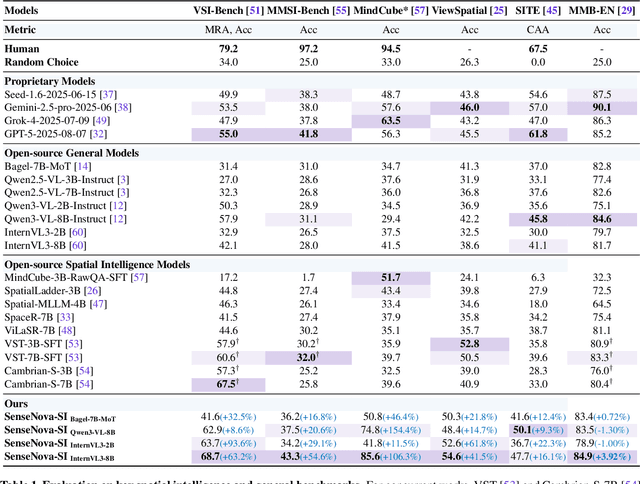


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
Enhancing the Outcome Reward-based RL Training of MLLMs with Self-Consistency Sampling
Nov 13, 2025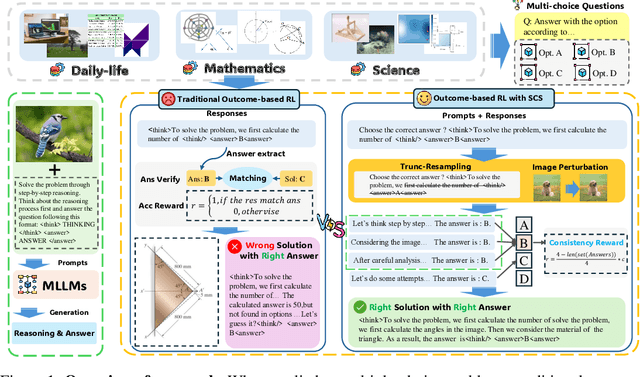
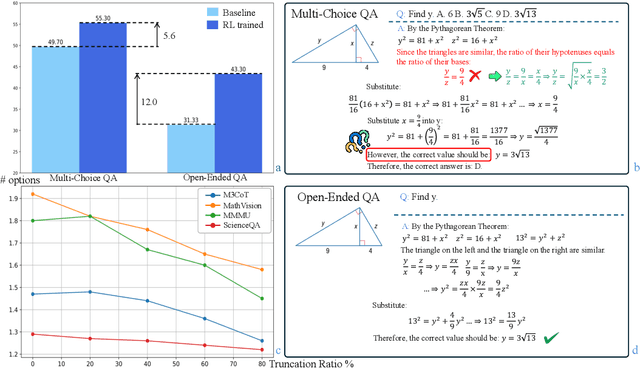
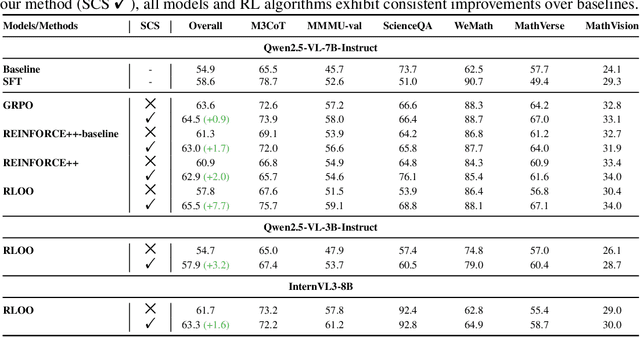
Outcome-reward reinforcement learning (RL) is a common and increasingly significant way to refine the step-by-step reasoning of multimodal large language models (MLLMs). In the multiple-choice setting - a dominant format for multimodal reasoning benchmarks - the paradigm faces a significant yet often overlooked obstacle: unfaithful trajectories that guess the correct option after a faulty chain of thought receive the same reward as genuine reasoning, which is a flaw that cannot be ignored. We propose Self-Consistency Sampling (SCS) to correct this issue. For each question, SCS (i) introduces small visual perturbations and (ii) performs repeated truncation and resampling of an initial trajectory; agreement among the resulting trajectories yields a differentiable consistency score that down-weights unreliable traces during policy updates. Based on Qwen2.5-VL-7B-Instruct, plugging SCS into RLOO, GRPO, and REINFORCE++ series improves accuracy by up to 7.7 percentage points on six multimodal benchmarks with negligible extra computation. SCS also yields notable gains on both Qwen2.5-VL-3B-Instruct and InternVL3-8B, offering a simple, general remedy for outcome-reward RL in MLLMs.
From Pixels to Words -- Towards Native Vision-Language Primitives at Scale
Oct 16, 2025The edifice of native Vision-Language Models (VLMs) has emerged as a rising contender to typical modular VLMs, shaped by evolving model architectures and training paradigms. Yet, two lingering clouds cast shadows over its widespread exploration and promotion: (-) What fundamental constraints set native VLMs apart from modular ones, and to what extent can these barriers be overcome? (-) How to make research in native VLMs more accessible and democratized, thereby accelerating progress in the field. In this paper, we clarify these challenges and outline guiding principles for constructing native VLMs. Specifically, one native VLM primitive should: (i) effectively align pixel and word representations within a shared semantic space; (ii) seamlessly integrate the strengths of formerly separate vision and language modules; (iii) inherently embody various cross-modal properties that support unified vision-language encoding, aligning, and reasoning. Hence, we launch NEO, a novel family of native VLMs built from first principles, capable of rivaling top-tier modular counterparts across diverse real-world scenarios. With only 390M image-text examples, NEO efficiently develops visual perception from scratch while mitigating vision-language conflicts inside a dense and monolithic model crafted from our elaborate primitives. We position NEO as a cornerstone for scalable and powerful native VLMs, paired with a rich set of reusable components that foster a cost-effective and extensible ecosystem. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
Spatial Preference Rewarding for MLLMs Spatial Understanding
Oct 16, 2025Multimodal large language models~(MLLMs) have demonstrated promising spatial understanding capabilities, such as referencing and grounding object descriptions. Despite their successes, MLLMs still fall short in fine-grained spatial perception abilities, such as generating detailed region descriptions or accurately localizing objects. Additionally, they often fail to respond to the user's requirements for desired fine-grained spatial understanding. This issue might arise because existing approaches primarily focus on tuning MLLMs to model pre-annotated instruction data to inject spatial knowledge, without direct supervision of MLLMs' actual responses. We address this issue by SPR, a Spatial Preference Rewarding~(SPR) approach that enhances MLLMs' spatial capabilities by rewarding MLLMs' detailed responses with precise object localization over vague or inaccurate responses. With randomly selected image regions and region descriptions from MLLMs, SPR introduces semantic and localization scores to comprehensively evaluate the text quality and localization quality in MLLM-generated descriptions. We also refine the MLLM descriptions with better localization accuracy and pair the best-scored refinement with the initial descriptions of the lowest score for direct preference optimization, thereby enhancing fine-grained alignment with visual input. Extensive experiments over standard referring and grounding benchmarks show that SPR improves MLLM spatial understanding capabilities effectively with minimal overhead in training. Data and code will be released at https://github.com/hanqiu-hq/SPR
CVD-STORM: Cross-View Video Diffusion with Spatial-Temporal Reconstruction Model for Autonomous Driving
Oct 09, 2025Generative models have been widely applied to world modeling for environment simulation and future state prediction. With advancements in autonomous driving, there is a growing demand not only for high-fidelity video generation under various controls, but also for producing diverse and meaningful information such as depth estimation. To address this, we propose CVD-STORM, a cross-view video diffusion model utilizing a spatial-temporal reconstruction Variational Autoencoder (VAE) that generates long-term, multi-view videos with 4D reconstruction capabilities under various control inputs. Our approach first fine-tunes the VAE with an auxiliary 4D reconstruction task, enhancing its ability to encode 3D structures and temporal dynamics. Subsequently, we integrate this VAE into the video diffusion process to significantly improve generation quality. Experimental results demonstrate that our model achieves substantial improvements in both FID and FVD metrics. Additionally, the jointly-trained Gaussian Splatting Decoder effectively reconstructs dynamic scenes, providing valuable geometric information for comprehensive scene understanding.
ELV-Halluc: Benchmarking Semantic Aggregation Hallucinations in Long Video Understanding
Aug 29, 2025

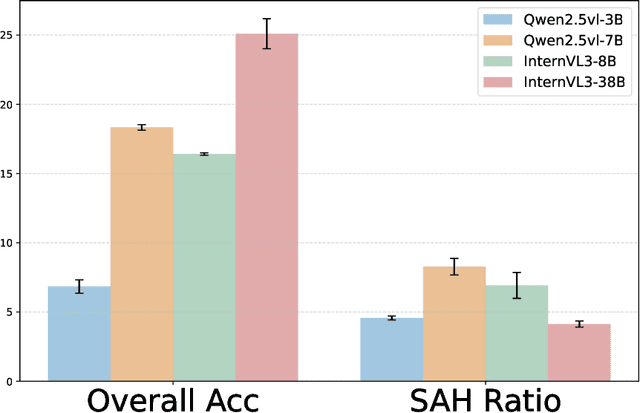
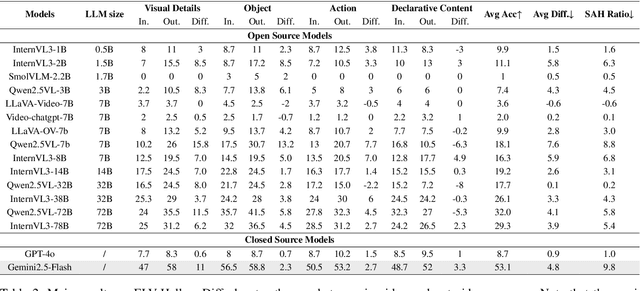
Video multimodal large language models (Video-MLLMs) have achieved remarkable progress in video understanding. However, they remain vulnerable to hallucination-producing content inconsistent with or unrelated to video inputs. Previous video hallucination benchmarks primarily focus on short-videos. They attribute hallucinations to factors such as strong language priors, missing frames, or vision-language biases introduced by the visual encoder. While these causes indeed account for most hallucinations in short videos, they still oversimplify the cause of hallucinations. Sometimes, models generate incorrect outputs but with correct frame-level semantics. We refer to this type of hallucination as Semantic Aggregation Hallucination (SAH), which arises during the process of aggregating frame-level semantics into event-level semantic groups. Given that SAH becomes particularly critical in long videos due to increased semantic complexity across multiple events, it is essential to separate and thoroughly investigate the causes of this type of hallucination. To address the above issues, we introduce ELV-Halluc, the first benchmark dedicated to long-video hallucination, enabling a systematic investigation of SAH. Our experiments confirm the existence of SAH and show that it increases with semantic complexity. Additionally, we find that models are more prone to SAH on rapidly changing semantics. Moreover, we discuss potential approaches to mitigate SAH. We demonstrate that positional encoding strategy contributes to alleviating SAH, and further adopt DPO strategy to enhance the model's ability to distinguish semantics within and across events. To support this, we curate a dataset of 8K adversarial data pairs and achieve improvements on both ELV-Halluc and Video-MME, including a substantial 27.7% reduction in SAH ratio.
Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
Aug 18, 2025Multi-modal models have achieved remarkable progress in recent years. Nevertheless, they continue to exhibit notable limitations in spatial understanding and reasoning, which are fundamental capabilities to achieving artificial general intelligence. With the recent release of GPT-5, allegedly the most powerful AI model to date, it is timely to examine where the leading models stand on the path toward spatial intelligence. First, we propose a comprehensive taxonomy of spatial tasks that unifies existing benchmarks and discuss the challenges in ensuring fair evaluation. We then evaluate state-of-the-art proprietary and open-source models on eight key benchmarks, at a cost exceeding one billion total tokens. Our empirical study reveals that (1) GPT-5 demonstrates unprecedented strength in spatial intelligence, yet (2) still falls short of human performance across a broad spectrum of tasks. Moreover, we (3) identify the more challenging spatial intelligence problems for multi-modal models, and (4) proprietary models do not exhibit a decisive advantage when facing the most difficult problems. In addition, we conduct a qualitative evaluation across a diverse set of scenarios that are intuitive for humans yet fail even the most advanced multi-modal models.
GUI-Reflection: Empowering Multimodal GUI Models with Self-Reflection Behavior
Jun 09, 2025



Multimodal Large Language Models (MLLMs) have shown great potential in revolutionizing Graphical User Interface (GUI) automation. However, existing GUI models mostly rely on learning from nearly error-free offline trajectories, thus lacking reflection and error recovery capabilities. To bridge this gap, we propose GUI-Reflection, a novel framework that explicitly integrates self-reflection and error correction capabilities into end-to-end multimodal GUI models throughout dedicated training stages: GUI-specific pre-training, offline supervised fine-tuning (SFT), and online reflection tuning. GUI-reflection enables self-reflection behavior emergence with fully automated data generation and learning processes without requiring any human annotation. Specifically, 1) we first propose scalable data pipelines to automatically construct reflection and error correction data from existing successful trajectories. While existing GUI models mainly focus on grounding and UI understanding ability, we propose the GUI-Reflection Task Suite to learn and evaluate reflection-oriented abilities explicitly. 2) Furthermore, we built a diverse and efficient environment for online training and data collection of GUI models on mobile devices. 3) We also present an iterative online reflection tuning algorithm leveraging the proposed environment, enabling the model to continuously enhance its reflection and error correction abilities. Our framework equips GUI agents with self-reflection and correction capabilities, paving the way for more robust, adaptable, and intelligent GUI automation, with all data, models, environments, and tools to be released publicly.