 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Rethinking with Latent Thought Vectors for Math Reasoning
Feb 06, 2026Standard chain-of-thought reasoning generates a solution in a single forward pass, committing irrevocably to each token and lacking a mechanism to recover from early errors. We introduce Inference-Time Rethinking, a generative framework that enables iterative self-correction by decoupling declarative latent thought vectors from procedural generation. We factorize reasoning into a continuous latent thought vector (what to reason about) and a decoder that verbalizes the trace conditioned on this vector (how to reason). Beyond serving as a declarative buffer, latent thought vectors compress the reasoning structure into a continuous representation that abstracts away surface-level token variability, making gradient-based optimization over reasoning strategies well-posed. Our prior model maps unstructured noise to a learned manifold of valid reasoning patterns, and at test time we employ a Gibbs-style procedure that alternates between generating a candidate trace and optimizing the latent vector to better explain that trace, effectively navigating the latent manifold to refine the reasoning strategy. Training a 0.2B-parameter model from scratch on GSM8K, our method with 30 rethinking iterations surpasses baselines with 10 to 15 times more parameters, including a 3B counterpart. This result demonstrates that effective mathematical reasoning can emerge from sophisticated inference-time computation rather than solely from massive parameter counts.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
CheXWorld: Exploring Image World Modeling for Radiograph Representation Learning
Apr 18, 2025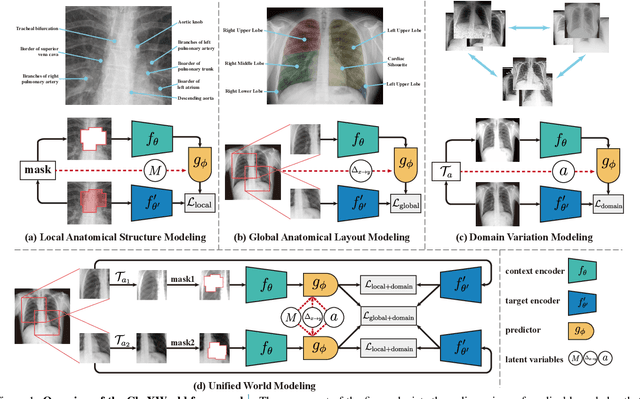
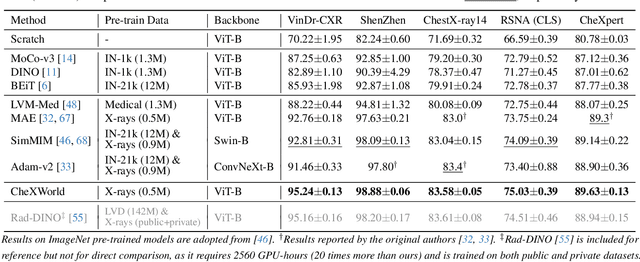
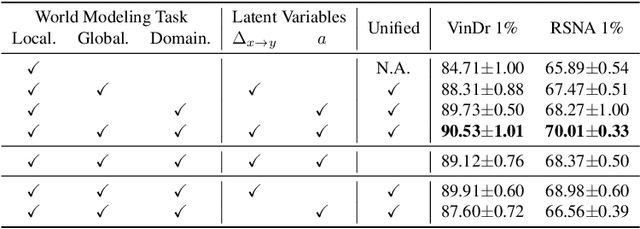

Humans can develop internal world models that encode common sense knowledge, telling them how the world works and predicting the consequences of their actions. This concept has emerged as a promising direction for establishing general-purpose machine-learning models in recent preliminary works, e.g., for visual representation learning. In this paper, we present CheXWorld, the first effort towards a self-supervised world model for radiographic images. Specifically, our work develops a unified framework that simultaneously models three aspects of medical knowledge essential for qualified radiologists, including 1) local anatomical structures describing the fine-grained characteristics of local tissues (e.g., architectures, shapes, and textures); 2) global anatomical layouts describing the global organization of the human body (e.g., layouts of organs and skeletons); and 3) domain variations that encourage CheXWorld to model the transitions across different appearance domains of radiographs (e.g., varying clarity, contrast, and exposure caused by collecting radiographs from different hospitals, devices, or patients). Empirically, we design tailored qualitative and quantitative analyses, revealing that CheXWorld successfully captures these three dimensions of medical knowledge. Furthermore, transfer learning experiments across eight medical image classification and segmentation benchmarks showcase that CheXWorld significantly outperforms existing SSL methods and large-scale medical foundation models. Code & pre-trained models are available at https://github.com/LeapLabTHU/CheXWorld.
HoVLE: Unleashing the Power of Monolithic Vision-Language Models with Holistic Vision-Language Embedding
Dec 20, 2024The rapid advance of Large Language Models (LLMs) has catalyzed the development of Vision-Language Models (VLMs). Monolithic VLMs, which avoid modality-specific encoders, offer a promising alternative to the compositional ones but face the challenge of inferior performance. Most existing monolithic VLMs require tuning pre-trained LLMs to acquire vision abilities, which may degrade their language capabilities. To address this dilemma, this paper presents a novel high-performance monolithic VLM named HoVLE. We note that LLMs have been shown capable of interpreting images, when image embeddings are aligned with text embeddings. The challenge for current monolithic VLMs actually lies in the lack of a holistic embedding module for both vision and language inputs. Therefore, HoVLE introduces a holistic embedding module that converts visual and textual inputs into a shared space, allowing LLMs to process images in the same way as texts. Furthermore, a multi-stage training strategy is carefully designed to empower the holistic embedding module. It is first trained to distill visual features from a pre-trained vision encoder and text embeddings from the LLM, enabling large-scale training with unpaired random images and text tokens. The whole model further undergoes next-token prediction on multi-modal data to align the embeddings. Finally, an instruction-tuning stage is incorporated. Our experiments show that HoVLE achieves performance close to leading compositional models on various benchmarks, outperforming previous monolithic models by a large margin. Model available at https://huggingface.co/OpenGVLab/HoVLE.
Learning 1D Causal Visual Representation with De-focus Attention Networks
Jun 06, 2024Modality differences have led to the development of heterogeneous architectures for vision and language models. While images typically require 2D non-causal modeling, texts utilize 1D causal modeling. This distinction poses significant challenges in constructing unified multi-modal models. This paper explores the feasibility of representing images using 1D causal modeling. We identify an "over-focus" issue in existing 1D causal vision models, where attention overly concentrates on a small proportion of visual tokens. The issue of "over-focus" hinders the model's ability to extract diverse visual features and to receive effective gradients for optimization. To address this, we propose De-focus Attention Networks, which employ learnable bandpass filters to create varied attention patterns. During training, large and scheduled drop path rates, and an auxiliary loss on globally pooled features for global understanding tasks are introduced. These two strategies encourage the model to attend to a broader range of tokens and enhance network optimization. Extensive experiments validate the efficacy of our approach, demonstrating that 1D causal visual representation can perform comparably to 2D non-causal representation in tasks such as global perception, dense prediction, and multi-modal understanding. Code is released at https://github.com/OpenGVLab/De-focus-Attention-Networks.
ADDP: Learning General Representations for Image Recognition and Generation with Alternating Denoising Diffusion Process
Jun 08, 2023Image recognition and generation have long been developed independently of each other. With the recent trend towards general-purpose representation learning, the development of general representations for both recognition and generation tasks is also promoted. However, preliminary attempts mainly focus on generation performance, but are still inferior on recognition tasks. These methods are modeled in the vector-quantized (VQ) space, whereas leading recognition methods use pixels as inputs. Our key insights are twofold: (1) pixels as inputs are crucial for recognition tasks; (2) VQ tokens as reconstruction targets are beneficial for generation tasks. These observations motivate us to propose an Alternating Denoising Diffusion Process (ADDP) that integrates these two spaces within a single representation learning framework. In each denoising step, our method first decodes pixels from previous VQ tokens, then generates new VQ tokens from the decoded pixels. The diffusion process gradually masks out a portion of VQ tokens to construct the training samples. The learned representations can be used to generate diverse high-fidelity images and also demonstrate excellent transfer performance on recognition tasks. Extensive experiments show that our method achieves competitive performance on unconditional generation, ImageNet classification, COCO detection, and ADE20k segmentation. Importantly, our method represents the first successful development of general representations applicable to both generation and dense recognition tasks. Code shall be released.
Ghost in the Minecraft: Generally Capable Agents for Open-World Environments via Large Language Models with Text-based Knowledge and Memory
Jun 01, 2023The captivating realm of Minecraft has attracted substantial research interest in recent years, serving as a rich platform for developing intelligent agents capable of functioning in open-world environments. However, the current research landscape predominantly focuses on specific objectives, such as the popular "ObtainDiamond" task, and has not yet shown effective generalization to a broader spectrum of tasks. Furthermore, the current leading success rate for the "ObtainDiamond" task stands at around 20%, highlighting the limitations of Reinforcement Learning (RL) based controllers used in existing methods. To tackle these challenges, we introduce Ghost in the Minecraft (GITM), a novel framework integrates Large Language Models (LLMs) with text-based knowledge and memory, aiming to create Generally Capable Agents (GCAs) in Minecraft. These agents, equipped with the logic and common sense capabilities of LLMs, can skillfully navigate complex, sparse-reward environments with text-based interactions. We develop a set of structured actions and leverage LLMs to generate action plans for the agents to execute. The resulting LLM-based agent markedly surpasses previous methods, achieving a remarkable improvement of +47.5% in success rate on the "ObtainDiamond" task, demonstrating superior robustness compared to traditional RL-based controllers. Notably, our agent is the first to procure all items in the Minecraft Overworld technology tree, demonstrating its extensive capabilities. GITM does not need any GPU for training, but a single CPU node with 32 CPU cores is enough. This research shows the potential of LLMs in developing capable agents for handling long-horizon, complex tasks and adapting to uncertainties in open-world environments. See the project website at https://github.com/OpenGVLab/GITM.
Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information
Nov 21, 2022



To effectively exploit the potential of large-scale models, various pre-training strategies supported by massive data from different sources are proposed, including supervised pre-training, weakly-supervised pre-training, and self-supervised pre-training. It has been proved that combining multiple pre-training strategies and data from various modalities/sources can greatly boost the training of large-scale models. However, current works adopt a multi-stage pre-training system, where the complex pipeline may increase the uncertainty and instability of the pre-training. It is thus desirable that these strategies can be integrated in a single-stage manner. In this paper, we first propose a general multi-modal mutual information formula as a unified optimization target and demonstrate that all existing approaches are special cases of our framework. Under this unified perspective, we propose an all-in-one single-stage pre-training approach, named Maximizing Multi-modal Mutual Information Pre-training (M3I Pre-training). Our approach achieves better performance than previous pre-training methods on various vision benchmarks, including ImageNet classification, COCO object detection, LVIS long-tailed object detection, and ADE20k semantic segmentation. Notably, we successfully pre-train a billion-level parameter image backbone and achieve state-of-the-art performance on various benchmarks. Code shall be released at https://github.com/OpenGVLab/M3I-Pretraining.
BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision
Nov 18, 2022We present a novel bird's-eye-view (BEV) detector with perspective supervision, which converges faster and better suits modern image backbones. Existing state-of-the-art BEV detectors are often tied to certain depth pre-trained backbones like VoVNet, hindering the synergy between booming image backbones and BEV detectors. To address this limitation, we prioritize easing the optimization of BEV detectors by introducing perspective space supervision. To this end, we propose a two-stage BEV detector, where proposals from the perspective head are fed into the bird's-eye-view head for final predictions. To evaluate the effectiveness of our model, we conduct extensive ablation studies focusing on the form of supervision and the generality of the proposed detector. The proposed method is verified with a wide spectrum of traditional and modern image backbones and achieves new SoTA results on the large-scale nuScenes dataset. The code shall be released soon.
Siamese Image Modeling for Self-Supervised Vision Representation Learning
Jun 02, 2022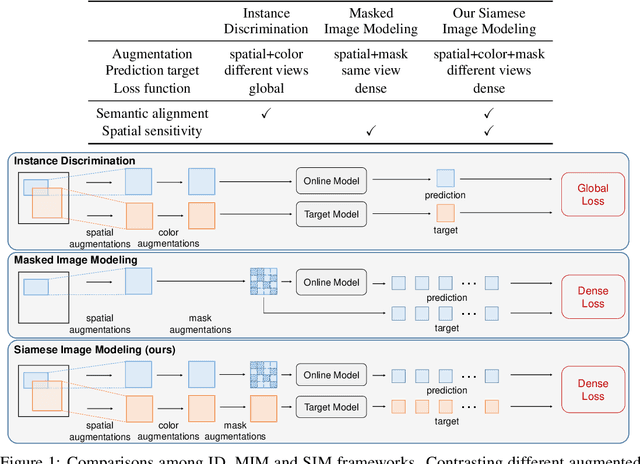

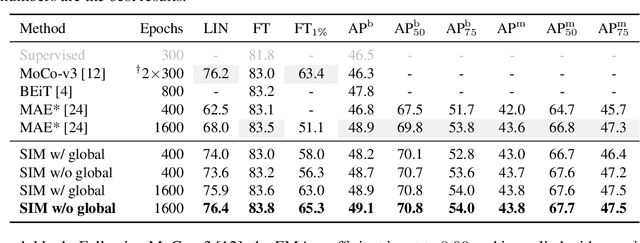
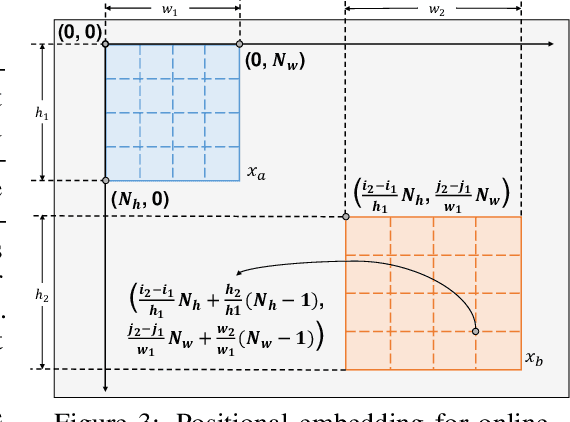
Self-supervised learning (SSL) has delivered superior performance on a variety of downstream vision tasks. Two main-stream SSL frameworks have been proposed, i.e., Instance Discrimination (ID) and Masked Image Modeling (MIM). ID pulls together the representations of different views from the same image, while avoiding feature collapse. It does well on linear probing but is inferior in detection performance. On the other hand, MIM reconstructs the original content given a masked image. It excels at dense prediction but fails to perform well on linear probing. Their distinctions are caused by neglecting the representation requirements of either semantic alignment or spatial sensitivity. Specifically, we observe that (1) semantic alignment demands semantically similar views to be projected into nearby representation, which can be achieved by contrasting different views with strong augmentations; (2) spatial sensitivity requires to model the local structure within an image. Predicting dense representations with masked image is therefore beneficial because it models the conditional distribution of image content. Driven by these analysis, we propose Siamese Image Modeling (SIM), which predicts the dense representations of an augmented view, based on another masked view from the same image but with different augmentations. Our method uses a Siamese network with two branches. The online branch encodes the first view, and predicts the second view's representation according to the relative positions between these two views. The target branch produces the target by encoding the second view. In this way, we are able to achieve comparable linear probing and dense prediction performances with ID and MIM, respectively. We also demonstrate that decent linear probing result can be obtained without a global loss. Code shall be released.