 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Visual Environment Structure Correlates with Control Performance
Feb 04, 2026The choice of visual representation is key to scaling generalist robot policies. However, direct evaluation via policy rollouts is expensive, even in simulation. Existing proxy metrics focus on the representation's capacity to capture narrow aspects of the visual world, like object shape, limiting generalization across environments. In this paper, we take an analytical perspective: we probe pretrained visual encoders by measuring how well they support decoding of environment state -- including geometry, object structure, and physical attributes -- from images. Leveraging simulation environments with access to ground-truth state, we show that this probing accuracy strongly correlates with downstream policy performance across diverse environments and learning settings, significantly outperforming prior metrics and enabling efficient representation selection. More broadly, our study provides insight into the representational properties that support generalizable manipulation, suggesting that learning to encode the latent physical state of the environment is a promising objective for control.
3DGS-Drag: Dragging Gaussians for Intuitive Point-Based 3D Editing
Jan 12, 2026The transformative potential of 3D content creation has been progressively unlocked through advancements in generative models. Recently, intuitive drag editing with geometric changes has attracted significant attention in 2D editing yet remains challenging for 3D scenes. In this paper, we introduce 3DGS-Drag -- a point-based 3D editing framework that provides efficient, intuitive drag manipulation of real 3D scenes. Our approach bridges the gap between deformation-based and 2D-editing-based 3D editing methods, addressing their limitations to geometry-related content editing. We leverage two key innovations: deformation guidance utilizing 3D Gaussian Splatting for consistent geometric modifications and diffusion guidance for content correction and visual quality enhancement. A progressive editing strategy further supports aggressive 3D drag edits. Our method enables a wide range of edits, including motion change, shape adjustment, inpainting, and content extension. Experimental results demonstrate the effectiveness of 3DGS-Drag in various scenes, achieving state-of-the-art performance in geometry-related 3D content editing. Notably, the editing is efficient, taking 10 to 20 minutes on a single RTX 4090 GPU.
SeqWalker: Sequential-Horizon Vision-and-Language Navigation with Hierarchical Planning
Jan 08, 2026Sequential-Horizon Vision-and-Language Navigation (SH-VLN) presents a challenging scenario where agents should sequentially execute multi-task navigation guided by complex, long-horizon language instructions. Current vision-and-language navigation models exhibit significant performance degradation with such multi-task instructions, as information overload impairs the agent's ability to attend to observationally relevant details. To address this problem, we propose SeqWalker, a navigation model built on a hierarchical planning framework. Our SeqWalker features: i) A High-Level Planner that dynamically selects global instructions into contextually relevant sub-instructions based on the agent's current visual observations, thus reducing cognitive load; ii) A Low-Level Planner incorporating an Exploration-Verification strategy that leverages the inherent logical structure of instructions for trajectory error correction. To evaluate SH-VLN performance, we also extend the IVLN dataset and establish a new benchmark. Extensive experiments are performed to demonstrate the superiority of the proposed SeqWalker.
Uncertainty-Gated Deformable Network for Breast Tumor Segmentation in MR Images
Sep 19, 2025



Accurate segmentation of breast tumors in magnetic resonance images (MRI) is essential for breast cancer diagnosis, yet existing methods face challenges in capturing irregular tumor shapes and effectively integrating local and global features. To address these limitations, we propose an uncertainty-gated deformable network to leverage the complementary information from CNN and Transformers. Specifically, we incorporates deformable feature modeling into both convolution and attention modules, enabling adaptive receptive fields for irregular tumor contours. We also design an Uncertainty-Gated Enhancing Module (U-GEM) to selectively exchange complementary features between CNN and Transformer based on pixel-wise uncertainty, enhancing both local and global representations. Additionally, a Boundary-sensitive Deep Supervision Loss is introduced to further improve tumor boundary delineation. Comprehensive experiments on two clinical breast MRI datasets demonstrate that our method achieves superior segmentation performance compared with state-of-the-art methods, highlighting its clinical potential for accurate breast tumor delineation.
MedKGent: A Large Language Model Agent Framework for Constructing Temporally Evolving Medical Knowledge Graph
Aug 17, 2025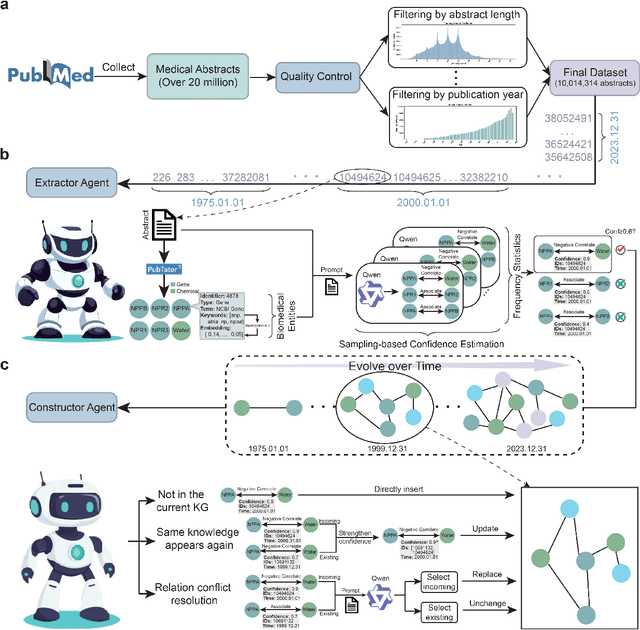
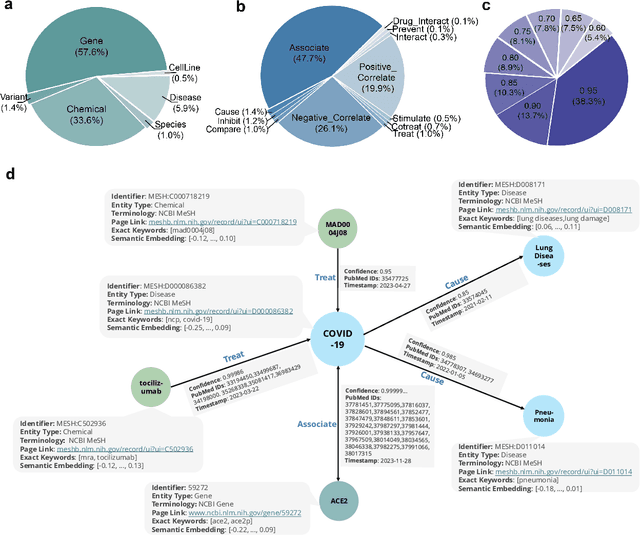
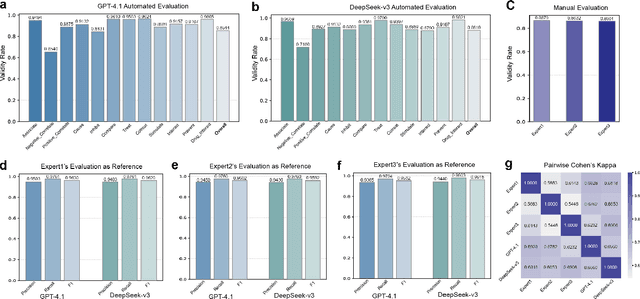
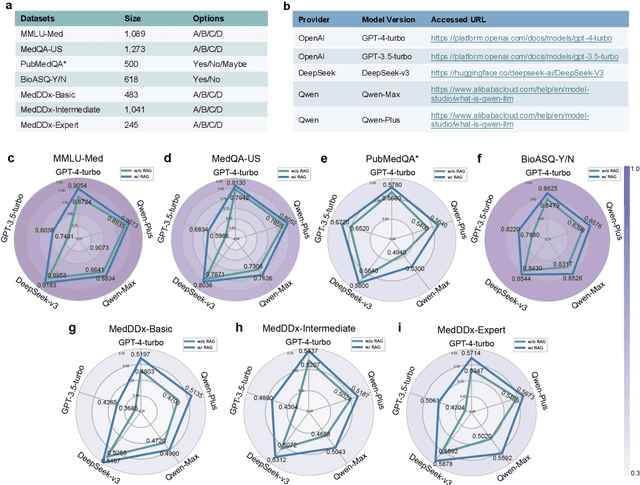
The rapid expansion of medical literature presents growing challenges for structuring and integrating domain knowledge at scale. Knowledge Graphs (KGs) offer a promising solution by enabling efficient retrieval, automated reasoning, and knowledge discovery. However, current KG construction methods often rely on supervised pipelines with limited generalizability or naively aggregate outputs from Large Language Models (LLMs), treating biomedical corpora as static and ignoring the temporal dynamics and contextual uncertainty of evolving knowledge. To address these limitations, we introduce MedKGent, a LLM agent framework for constructing temporally evolving medical KGs. Leveraging over 10 million PubMed abstracts published between 1975 and 2023, we simulate the emergence of biomedical knowledge via a fine-grained daily time series. MedKGent incrementally builds the KG in a day-by-day manner using two specialized agents powered by the Qwen2.5-32B-Instruct model. The Extractor Agent identifies knowledge triples and assigns confidence scores via sampling-based estimation, which are used to filter low-confidence extractions and inform downstream processing. The Constructor Agent incrementally integrates the retained triples into a temporally evolving graph, guided by confidence scores and timestamps to reinforce recurring knowledge and resolve conflicts. The resulting KG contains 156,275 entities and 2,971,384 relational triples. Quality assessments by two SOTA LLMs and three domain experts demonstrate an accuracy approaching 90\%, with strong inter-rater agreement. To evaluate downstream utility, we conduct RAG across seven medical question answering benchmarks using five leading LLMs, consistently observing significant improvements over non-augmented baselines. Case studies further demonstrate the KG's value in literature-based drug repurposing via confidence-aware causal inference.
CRISP: Contrastive Residual Injection and Semantic Prompting for Continual Video Instance Segmentation
Aug 14, 2025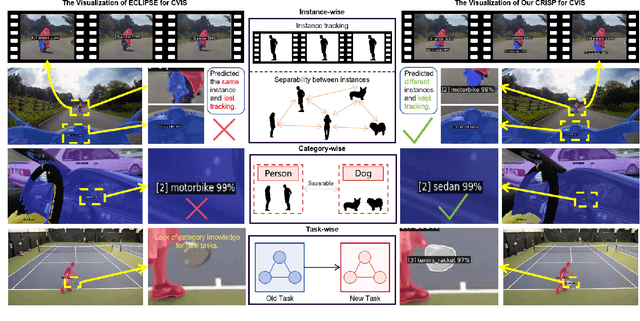
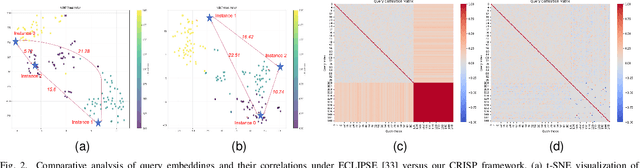
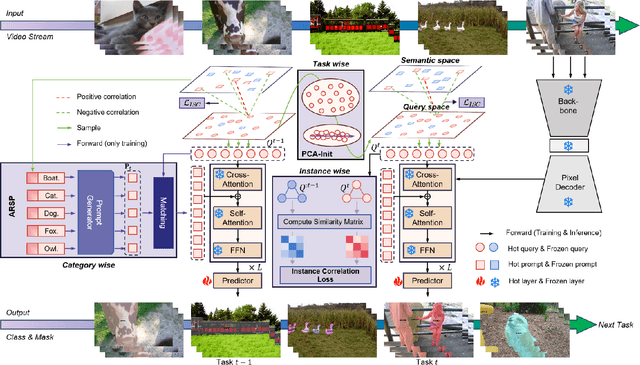
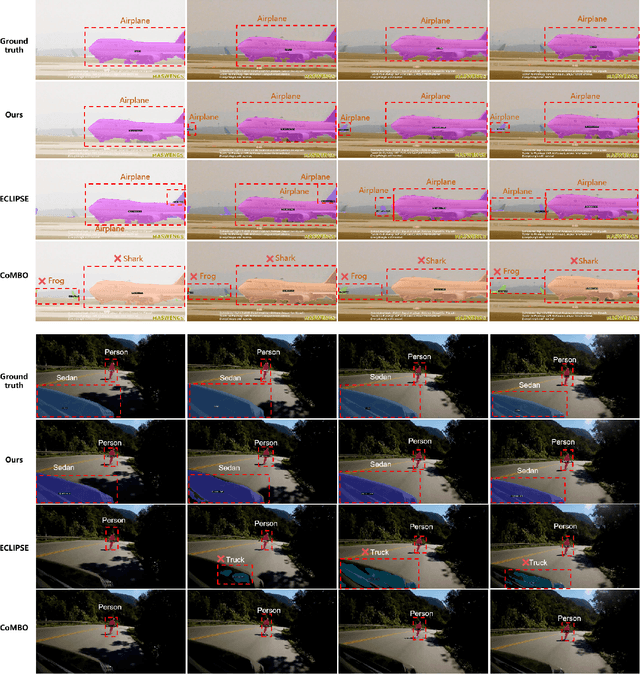
Continual video instance segmentation demands both the plasticity to absorb new object categories and the stability to retain previously learned ones, all while preserving temporal consistency across frames. In this work, we introduce Contrastive Residual Injection and Semantic Prompting (CRISP), an earlier attempt tailored to address the instance-wise, category-wise, and task-wise confusion in continual video instance segmentation. For instance-wise learning, we model instance tracking and construct instance correlation loss, which emphasizes the correlation with the prior query space while strengthening the specificity of the current task query. For category-wise learning, we build an adaptive residual semantic prompt (ARSP) learning framework, which constructs a learnable semantic residual prompt pool generated by category text and uses an adjustive query-prompt matching mechanism to build a mapping relationship between the query of the current task and the semantic residual prompt. Meanwhile, a semantic consistency loss based on the contrastive learning is introduced to maintain semantic coherence between object queries and residual prompts during incremental training. For task-wise learning, to ensure the correlation at the inter-task level within the query space, we introduce a concise yet powerful initialization strategy for incremental prompts. Extensive experiments on YouTube-VIS-2019 and YouTube-VIS-2021 datasets demonstrate that CRISP significantly outperforms existing continual segmentation methods in the long-term continual video instance segmentation task, avoiding catastrophic forgetting and effectively improving segmentation and classification performance. The code is available at https://github.com/01upup10/CRISP.
Hierarchical Visual Prompt Learning for Continual Video Instance Segmentation
Aug 12, 2025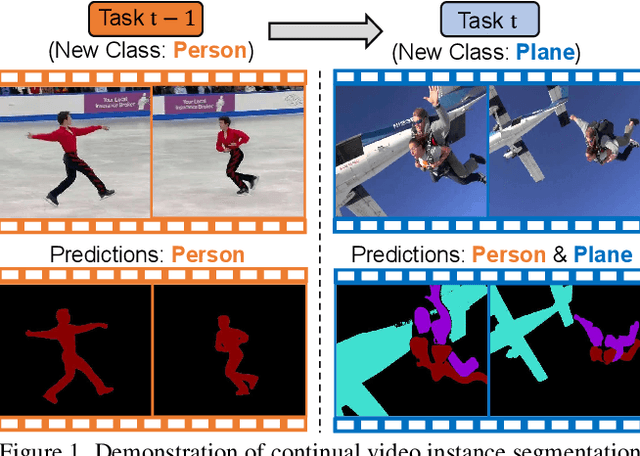
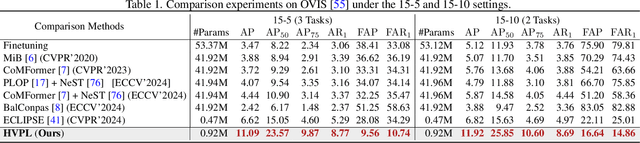
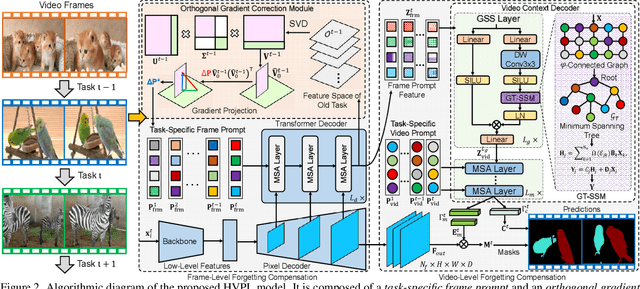
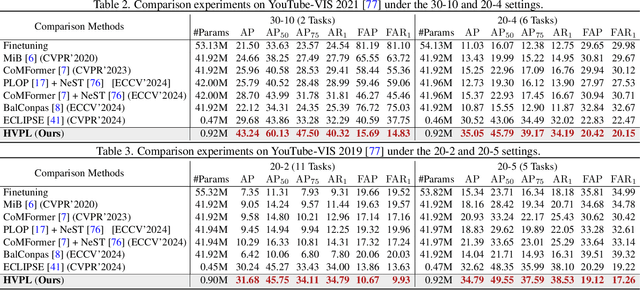
Video instance segmentation (VIS) has gained significant attention for its capability in tracking and segmenting object instances across video frames. However, most of the existing VIS approaches unrealistically assume that the categories of object instances remain fixed over time. Moreover, they experience catastrophic forgetting of old classes when required to continuously learn object instances belonging to new categories. To resolve these challenges, we develop a novel Hierarchical Visual Prompt Learning (HVPL) model that overcomes catastrophic forgetting of previous categories from both frame-level and video-level perspectives. Specifically, to mitigate forgetting at the frame level, we devise a task-specific frame prompt and an orthogonal gradient correction (OGC) module. The OGC module helps the frame prompt encode task-specific global instance information for new classes in each individual frame by projecting its gradients onto the orthogonal feature space of old classes. Furthermore, to address forgetting at the video level, we design a task-specific video prompt and a video context decoder. This decoder first embeds structural inter-class relationships across frames into the frame prompt features, and then propagates task-specific global video contexts from the frame prompt features to the video prompt. Through rigorous comparisons, our HVPL model proves to be more effective than baseline approaches. The code is available at https://github.com/JiahuaDong/HVPL.
Accurate Tracking of Arabidopsis Root Cortex Cell Nuclei in 3D Time-Lapse Microscopy Images Based on Genetic Algorithm
Apr 17, 2025Arabidopsis is a widely used model plant to gain basic knowledge on plant physiology and development. Live imaging is an important technique to visualize and quantify elemental processes in plant development. To uncover novel theories underlying plant growth and cell division, accurate cell tracking on live imaging is of utmost importance. The commonly used cell tracking software, TrackMate, adopts tracking-by-detection fashion, which applies Laplacian of Gaussian (LoG) for blob detection, and Linear Assignment Problem (LAP) tracker for tracking. However, they do not perform sufficiently when cells are densely arranged. To alleviate the problems mentioned above, we propose an accurate tracking method based on Genetic algorithm (GA) using knowledge of Arabidopsis root cellular patterns and spatial relationship among volumes. Our method can be described as a coarse-to-fine method, in which we first conducted relatively easy line-level tracking of cell nuclei, then performed complicated nuclear tracking based on known linear arrangement of cell files and their spatial relationship between nuclei. Our method has been evaluated on a long-time live imaging dataset of Arabidopsis root tips, and with minor manual rectification, it accurately tracks nuclei. To the best of our knowledge, this research represents the first successful attempt to address a long-standing problem in the field of time-lapse microscopy in the root meristem by proposing an accurate tracking method for Arabidopsis root nuclei.
IAP: Improving Continual Learning of Vision-Language Models via Instance-Aware Prompting
Mar 26, 2025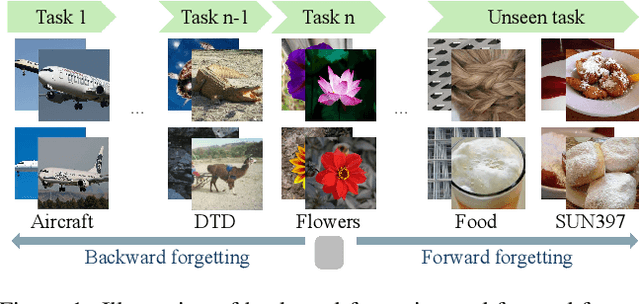
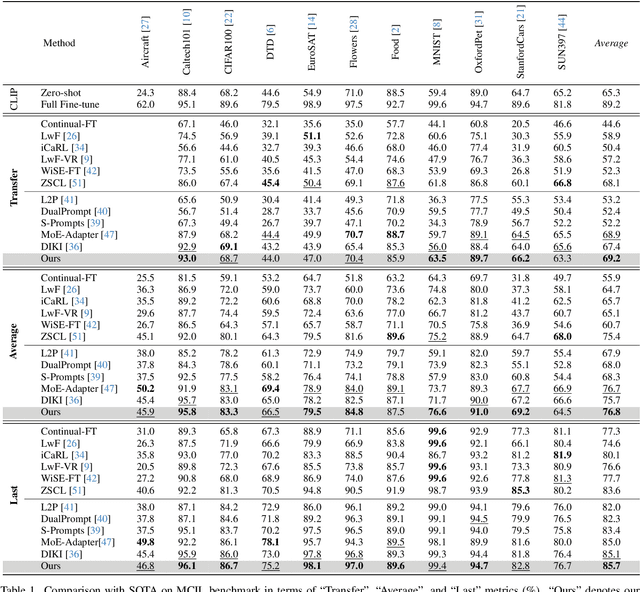
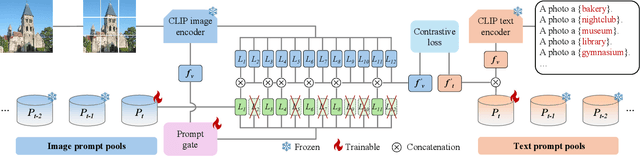
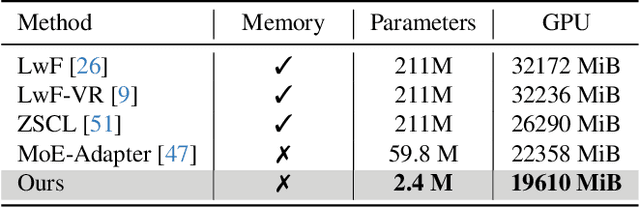
Recent pre-trained vision-language models (PT-VLMs) often face a Multi-Domain Class-Incremental Learning (MCIL) scenario in practice, where several classes and domains of multi-modal tasks are incrementally arrived. Without access to previously learned tasks and unseen tasks, memory-constrained MCIL suffers from forward and backward forgetting. To alleviate the above challenges, parameter-efficient fine-tuning techniques (PEFT), such as prompt tuning, are employed to adapt the PT-VLM to the diverse incrementally learned tasks. To achieve effective new task adaptation, existing methods only consider the effect of PEFT strategy selection, but neglect the influence of PEFT parameter setting (e.g., prompting). In this paper, we tackle the challenge of optimizing prompt designs for diverse tasks in MCIL and propose an Instance-Aware Prompting (IAP) framework. Specifically, our Instance-Aware Gated Prompting (IA-GP) module enhances adaptation to new tasks while mitigating forgetting by dynamically assigning prompts across transformer layers at the instance level. Our Instance-Aware Class-Distribution-Driven Prompting (IA-CDDP) improves the task adaptation process by determining an accurate task-label-related confidence score for each instance. Experimental evaluations across 11 datasets, using three performance metrics, demonstrate the effectiveness of our proposed method. Code can be found at https://github.com/FerdinandZJU/IAP.
Video SimpleQA: Towards Factuality Evaluation in Large Video Language Models
Mar 24, 2025



Recent advancements in Large Video Language Models (LVLMs) have highlighted their potential for multi-modal understanding, yet evaluating their factual grounding in video contexts remains a critical unsolved challenge. To address this gap, we introduce Video SimpleQA, the first comprehensive benchmark tailored for factuality evaluation of LVLMs. Our work distinguishes from existing video benchmarks through the following key features: 1) Knowledge required: demanding integration of external knowledge beyond the explicit narrative; 2) Fact-seeking question: targeting objective, undisputed events or relationships, avoiding subjective interpretation; 3) Definitive & short-form answer: Answers are crafted as unambiguous and definitively correct in a short format, enabling automated evaluation through LLM-as-a-judge frameworks with minimal scoring variance; 4) External-source verified: All annotations undergo rigorous validation against authoritative external references to ensure the reliability; 5) Temporal reasoning required: The annotated question types encompass both static single-frame understanding and dynamic temporal reasoning, explicitly evaluating LVLMs factuality under the long-context dependencies. We extensively evaluate 41 state-of-the-art LVLMs and summarize key findings as follows: 1) Current LVLMs exhibit notable deficiencies in factual adherence, particularly for open-source models. The best-performing model Gemini-1.5-Pro achieves merely an F-score of 54.4%; 2) Test-time compute paradigms show insignificant performance gains, revealing fundamental constraints for enhancing factuality through post-hoc computation; 3) Retrieval-Augmented Generation demonstrates consistent improvements at the cost of additional inference time overhead, presenting a critical efficiency-performance trade-off.