 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyChemVL: Advancing Chemical Vision-Language Models via Efficient Visual Token Reduction and Complex Reaction Tasks
Nov 09, 2025While Vision Language Models (VLMs) have demonstrated remarkable capabilities in general visual understanding, their application in the chemical domain has been limited, with previous works predominantly focusing on text and thus overlooking critical visual information, such as molecular structures. Current approaches that directly adopt standard VLMs for chemical tasks suffer from two primary issues: (i) computational inefficiency of processing entire chemical images with non-informative backgrounds. (ii) a narrow scope on molecular-level tasks that restricts progress in chemical reasoning. In this work, we propose \textbf{TinyChemVL}, an efficient and powerful chemical VLM that leverages visual token reduction and reaction-level tasks to improve model efficiency and reasoning capacity. Also, we propose \textbf{ChemRxn-V}, a reaction-level benchmark for assessing vision-based reaction recognition and prediction tasks. Directly predicting reaction products from molecular images poses a non-trivial challenge, as it requires models to integrate both recognition and reasoning capacities. Our results demonstrate that with only 4B parameters, TinyChemVL achieves superior performance on both molecular and reaction tasks while demonstrating faster inference and training speeds compared to existing models. Notably, TinyChemVL outperforms ChemVLM while utilizing only 1/16th of the visual tokens. This work builds efficient yet powerful VLMs for chemical domains by co-designing model architecture and task complexity.
From System 1 to System 2: A Survey of Reasoning Large Language Models
Feb 25, 2025Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI's o1/o3 and DeepSeek's R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
Chain of Tools: Large Language Model is an Automatic Multi-tool Learner
May 26, 2024Augmenting large language models (LLMs) with external tools has emerged as a promising approach to extend their utility, empowering them to solve practical tasks. Existing work typically empowers LLMs as tool users with a manually designed workflow, where the LLM plans a series of tools in a step-by-step manner, and sequentially executes each tool to obtain intermediate results until deriving the final answer. However, they suffer from two challenges in realistic scenarios: (1) The handcrafted control flow is often ad-hoc and constraints the LLM to local planning; (2) The LLM is instructed to use only manually demonstrated tools or well-trained Python functions, which limits its generalization to new tools. In this work, we first propose Automatic Tool Chain (ATC), a framework that enables the LLM to act as a multi-tool user, which directly utilizes a chain of tools through programming. To scale up the scope of the tools, we next propose a black-box probing method. This further empowers the LLM as a tool learner that can actively discover and document tool usages, teaching themselves to properly master new tools. For a comprehensive evaluation, we build a challenging benchmark named ToolFlow, which diverges from previous benchmarks by its long-term planning scenarios and complex toolset. Experiments on both existing datasets and ToolFlow illustrate the superiority of our framework. Analysis on different settings also validates the effectiveness and the utility of our black-box probing algorithm.
Learning to Use Tools via Cooperative and Interactive Agents
Mar 05, 2024



Tool learning empowers large language models (LLMs) as agents to use external tools to extend their capability. Existing methods employ one single LLM-based agent to iteratively select and execute tools, thereafter incorporating the result into the next action prediction. However, they still suffer from potential performance degradation when addressing complex tasks due to: (1) the limitation of the inherent capability of a single LLM to perform diverse actions, and (2) the struggle to adaptively correct mistakes when the task fails. To mitigate these problems, we propose the ConAgents, a Cooperative and interactive Agents framework, which modularizes the workflow of tool learning into Grounding, Execution, and Observing agents. We also introduce an iterative calibration (IterCali) method, enabling the agents to adapt themselves based on the feedback from the tool environment. Experiments conducted on three datasets demonstrate the superiority of our ConAgents (e.g., 6 point improvement over the SOTA baseline). We further provide fine-granularity analysis for the efficiency and consistency of our framework.
Continual Named Entity Recognition without Catastrophic Forgetting
Oct 23, 2023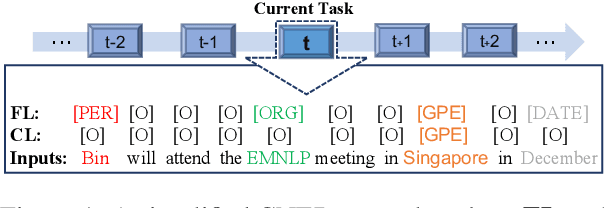
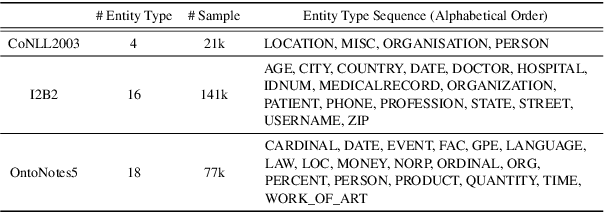
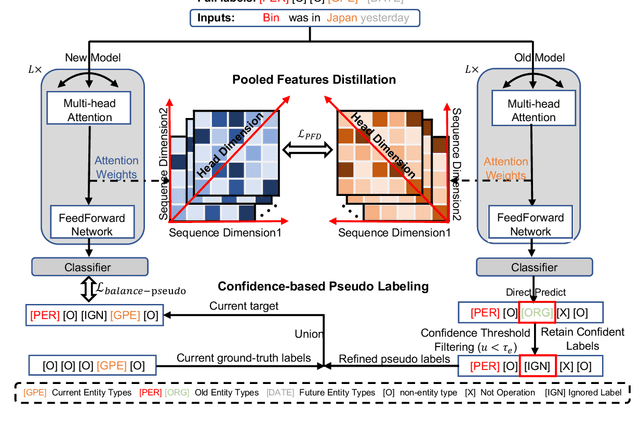
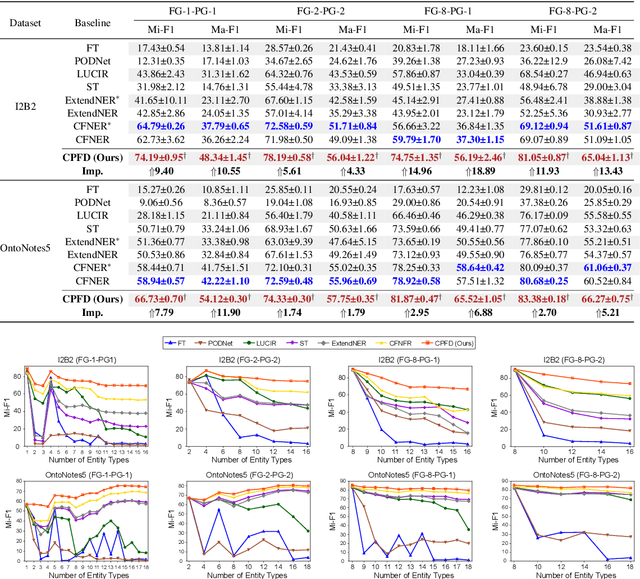
Continual Named Entity Recognition (CNER) is a burgeoning area, which involves updating an existing model by incorporating new entity types sequentially. Nevertheless, continual learning approaches are often severely afflicted by catastrophic forgetting. This issue is intensified in CNER due to the consolidation of old entity types from previous steps into the non-entity type at each step, leading to what is known as the semantic shift problem of the non-entity type. In this paper, we introduce a pooled feature distillation loss that skillfully navigates the trade-off between retaining knowledge of old entity types and acquiring new ones, thereby more effectively mitigating the problem of catastrophic forgetting. Additionally, we develop a confidence-based pseudo-labeling for the non-entity type, \emph{i.e.,} predicting entity types using the old model to handle the semantic shift of the non-entity type. Following the pseudo-labeling process, we suggest an adaptive re-weighting type-balanced learning strategy to handle the issue of biased type distribution. We carried out comprehensive experiments on ten CNER settings using three different datasets. The results illustrate that our method significantly outperforms prior state-of-the-art approaches, registering an average improvement of $6.3$\% and $8.0$\% in Micro and Macro F1 scores, respectively.
Task Relation Distillation and Prototypical Pseudo Label for Incremental Named Entity Recognition
Aug 17, 2023Incremental Named Entity Recognition (INER) involves the sequential learning of new entity types without accessing the training data of previously learned types. However, INER faces the challenge of catastrophic forgetting specific for incremental learning, further aggravated by background shift (i.e., old and future entity types are labeled as the non-entity type in the current task). To address these challenges, we propose a method called task Relation Distillation and Prototypical pseudo label (RDP) for INER. Specifically, to tackle catastrophic forgetting, we introduce a task relation distillation scheme that serves two purposes: 1) ensuring inter-task semantic consistency across different incremental learning tasks by minimizing inter-task relation distillation loss, and 2) enhancing the model's prediction confidence by minimizing intra-task self-entropy loss. Simultaneously, to mitigate background shift, we develop a prototypical pseudo label strategy that distinguishes old entity types from the current non-entity type using the old model. This strategy generates high-quality pseudo labels by measuring the distances between token embeddings and type-wise prototypes. We conducted extensive experiments on ten INER settings of three benchmark datasets (i.e., CoNLL2003, I2B2, and OntoNotes5). The results demonstrate that our method achieves significant improvements over the previous state-of-the-art methods, with an average increase of 6.08% in Micro F1 score and 7.71% in Macro F1 score.
Matching-based Term Semantics Pre-training for Spoken Patient Query Understanding
Mar 02, 2023
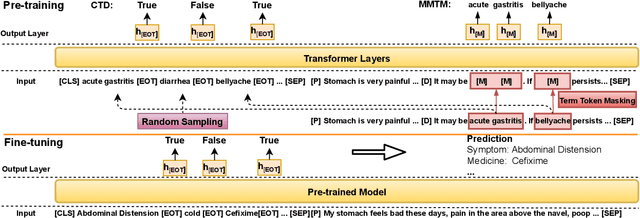
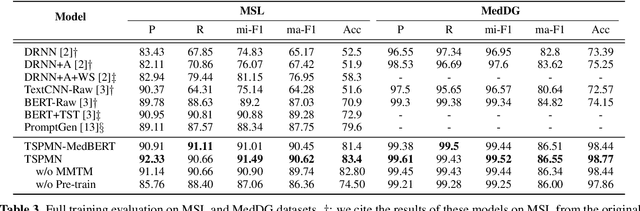
Medical Slot Filling (MSF) task aims to convert medical queries into structured information, playing an essential role in diagnosis dialogue systems. However, the lack of sufficient term semantics learning makes existing approaches hard to capture semantically identical but colloquial expressions of terms in medical conversations. In this work, we formalize MSF into a matching problem and propose a Term Semantics Pre-trained Matching Network (TSPMN) that takes both terms and queries as input to model their semantic interaction. To learn term semantics better, we further design two self-supervised objectives, including Contrastive Term Discrimination (CTD) and Matching-based Mask Term Modeling (MMTM). CTD determines whether it is the masked term in the dialogue for each given term, while MMTM directly predicts the masked ones. Experimental results on two Chinese benchmarks show that TSPMN outperforms strong baselines, especially in few-shot settings.
Crucial Semantic Classifier-based Adversarial Learning for Unsupervised Domain Adaptation
Feb 03, 2023



Unsupervised Domain Adaptation (UDA), which aims to explore the transferrable features from a well-labeled source domain to a related unlabeled target domain, has been widely progressed. Nevertheless, as one of the mainstream, existing adversarial-based methods neglect to filter the irrelevant semantic knowledge, hindering adaptation performance improvement. Besides, they require an additional domain discriminator that strives extractor to generate confused representations, but discrete designing may cause model collapse. To tackle the above issues, we propose Crucial Semantic Classifier-based Adversarial Learning (CSCAL), which pays more attention to crucial semantic knowledge transferring and leverages the classifier to implicitly play the role of domain discriminator without extra network designing. Specifically, in intra-class-wise alignment, a Paired-Level Discrepancy (PLD) is designed to transfer crucial semantic knowledge. Additionally, based on classifier predictions, a Nuclear Norm-based Discrepancy (NND) is formed that considers inter-class-wise information and improves the adaptation performance. Moreover, CSCAL can be effortlessly merged into different UDA methods as a regularizer and dramatically promote their performance.
Consecutive Knowledge Meta-Adaptation Learning for Unsupervised Medical Diagnosis
Sep 21, 2022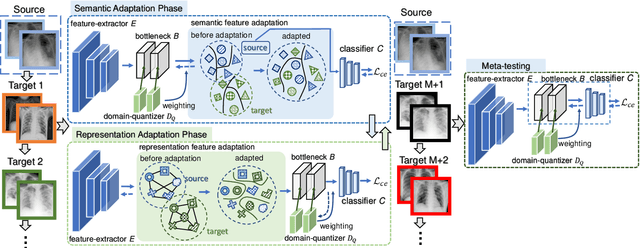
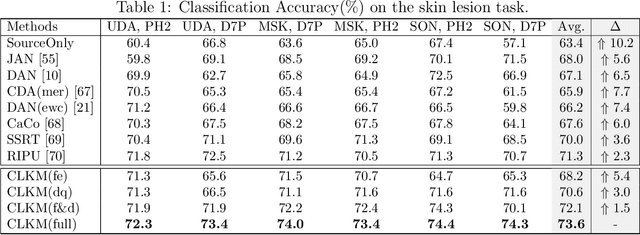
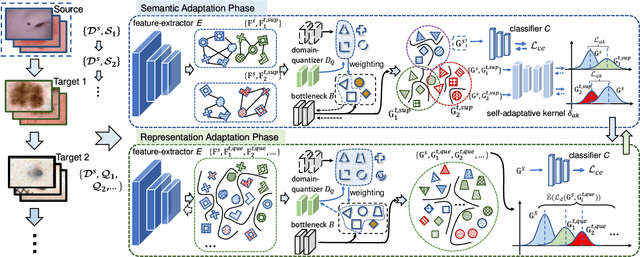
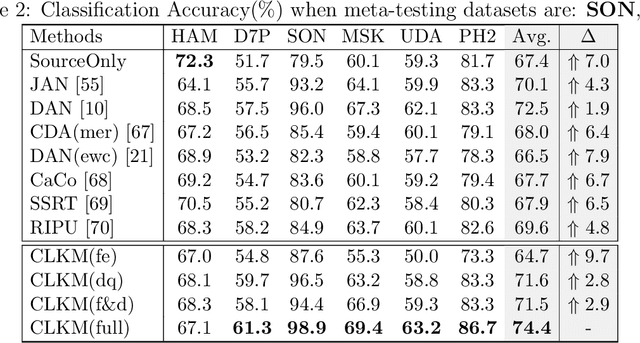
Deep learning-based Computer-Aided Diagnosis (CAD) has attracted appealing attention in academic researches and clinical applications. Nevertheless, the Convolutional Neural Networks (CNNs) diagnosis system heavily relies on the well-labeled lesion dataset, and the sensitivity to the variation of data distribution also restricts the potential application of CNNs in CAD. Unsupervised Domain Adaptation (UDA) methods are developed to solve the expensive annotation and domain gaps problem and have achieved remarkable success in medical image analysis. Yet existing UDA approaches only adapt knowledge learned from the source lesion domain to a single target lesion domain, which is against the clinical scenario: the new unlabeled target domains to be diagnosed always arrive in an online and continual manner. Moreover, the performance of existing approaches degrades dramatically on previously learned target lesion domains, due to the newly learned knowledge overwriting the previously learned knowledge (i.e., catastrophic forgetting). To deal with the above issues, we develop a meta-adaptation framework named Consecutive Lesion Knowledge Meta-Adaptation (CLKM), which mainly consists of Semantic Adaptation Phase (SAP) and Representation Adaptation Phase (RAP) to learn the diagnosis model in an online and continual manner. In the SAP, the semantic knowledge learned from the source lesion domain is transferred to consecutive target lesion domains. In the RAP, the feature-extractor is optimized to align the transferable representation knowledge across the source and multiple target lesion domains.
HiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
May 31, 2022

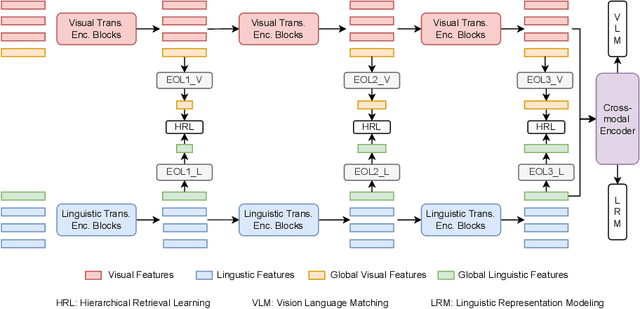
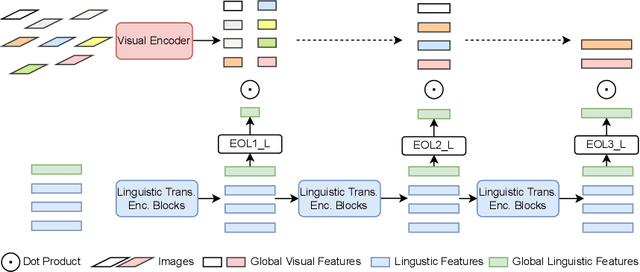
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.