 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype Correlation Matching and Class-Relation Reasoning for Few-Shot Medical Image Segmentation
Jun 07, 2024Few-shot medical image segmentation has achieved great progress in improving accuracy and efficiency of medical analysis in the biomedical imaging field. However, most existing methods cannot explore inter-class relations among base and novel medical classes to reason unseen novel classes. Moreover, the same kind of medical class has large intra-class variations brought by diverse appearances, shapes and scales, thus causing ambiguous visual characterization to degrade generalization performance of these existing methods on unseen novel classes. To address the above challenges, in this paper, we propose a \underline{\textbf{P}}rototype correlation \underline{\textbf{M}}atching and \underline{\textbf{C}}lass-relation \underline{\textbf{R}}easoning (i.e., \textbf{PMCR}) model. The proposed model can effectively mitigate false pixel correlation matches caused by large intra-class variations while reasoning inter-class relations among different medical classes. Specifically, in order to address false pixel correlation match brought by large intra-class variations, we propose a prototype correlation matching module to mine representative prototypes that can characterize diverse visual information of different appearances well. We aim to explore prototype-level rather than pixel-level correlation matching between support and query features via optimal transport algorithm to tackle false matches caused by intra-class variations. Meanwhile, in order to explore inter-class relations, we design a class-relation reasoning module to segment unseen novel medical objects via reasoning inter-class relations between base and novel classes. Such inter-class relations can be well propagated to semantic encoding of local query features to improve few-shot segmentation performance. Quantitative comparisons illustrates the large performance improvement of our model over other baseline methods.
Crucial Semantic Classifier-based Adversarial Learning for Unsupervised Domain Adaptation
Feb 03, 2023



Unsupervised Domain Adaptation (UDA), which aims to explore the transferrable features from a well-labeled source domain to a related unlabeled target domain, has been widely progressed. Nevertheless, as one of the mainstream, existing adversarial-based methods neglect to filter the irrelevant semantic knowledge, hindering adaptation performance improvement. Besides, they require an additional domain discriminator that strives extractor to generate confused representations, but discrete designing may cause model collapse. To tackle the above issues, we propose Crucial Semantic Classifier-based Adversarial Learning (CSCAL), which pays more attention to crucial semantic knowledge transferring and leverages the classifier to implicitly play the role of domain discriminator without extra network designing. Specifically, in intra-class-wise alignment, a Paired-Level Discrepancy (PLD) is designed to transfer crucial semantic knowledge. Additionally, based on classifier predictions, a Nuclear Norm-based Discrepancy (NND) is formed that considers inter-class-wise information and improves the adaptation performance. Moreover, CSCAL can be effortlessly merged into different UDA methods as a regularizer and dramatically promote their performance.
MSO: Multi-Feature Space Joint Optimization Network for RGB-Infrared Person Re-Identification
Oct 21, 2021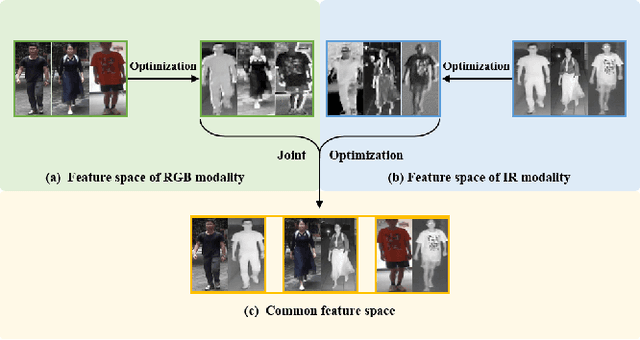
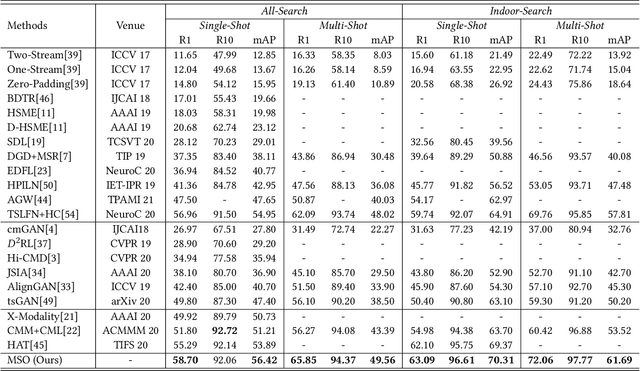
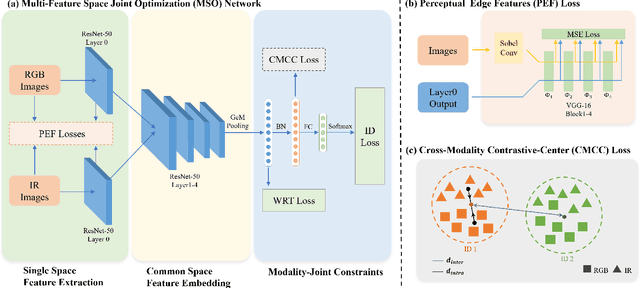
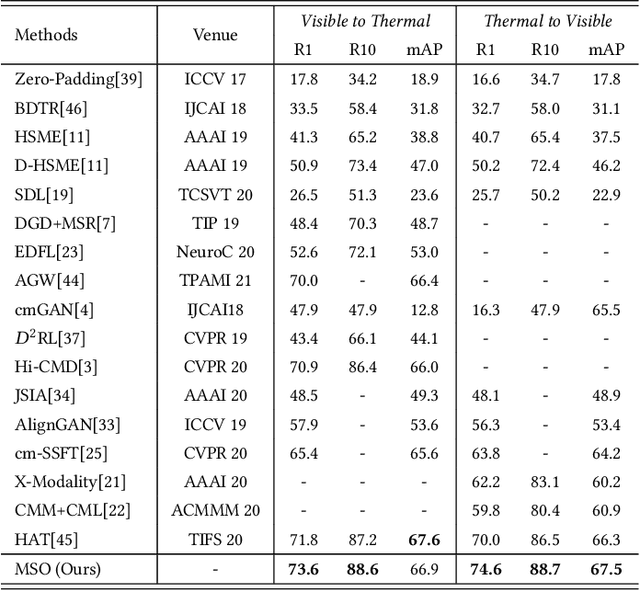
The RGB-infrared cross-modality person re-identification (ReID) task aims to recognize the images of the same identity between the visible modality and the infrared modality. Existing methods mainly use a two-stream architecture to eliminate the discrepancy between the two modalities in the final common feature space, which ignore the single space of each modality in the shallow layers. To solve it, in this paper, we present a novel multi-feature space joint optimization (MSO) network, which can learn modality-sharable features in both the single-modality space and the common space. Firstly, based on the observation that edge information is modality-invariant, we propose an edge features enhancement module to enhance the modality-sharable features in each single-modality space. Specifically, we design a perceptual edge features (PEF) loss after the edge fusion strategy analysis. According to our knowledge, this is the first work that proposes explicit optimization in the single-modality feature space on cross-modality ReID task. Moreover, to increase the difference between cross-modality distance and class distance, we introduce a novel cross-modality contrastive-center (CMCC) loss into the modality-joint constraints in the common feature space. The PEF loss and CMCC loss jointly optimize the model in an end-to-end manner, which markedly improves the network's performance. Extensive experiments demonstrate that the proposed model significantly outperforms state-of-the-art methods on both the SYSU-MM01 and RegDB datasets.
CMTR: Cross-modality Transformer for Visible-infrared Person Re-identification
Oct 18, 2021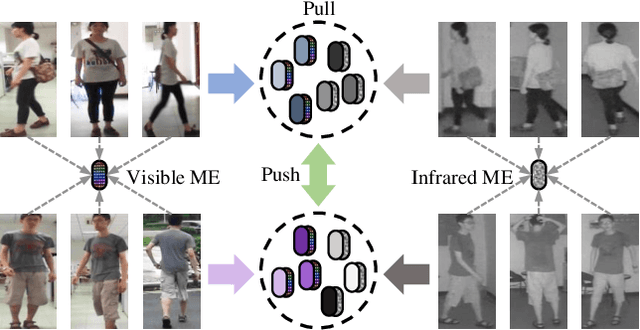
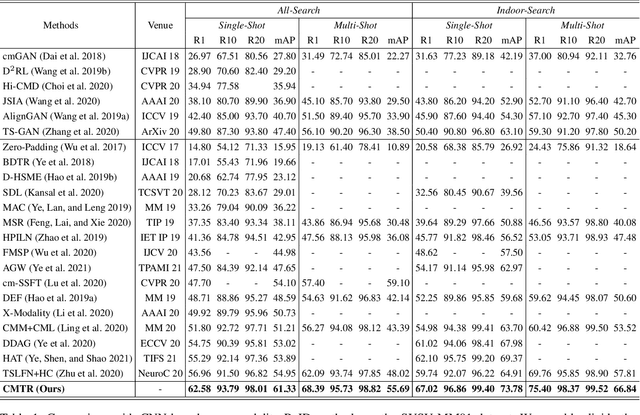
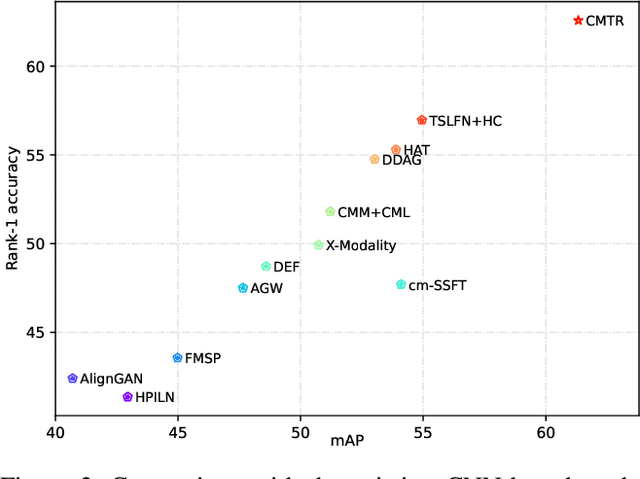
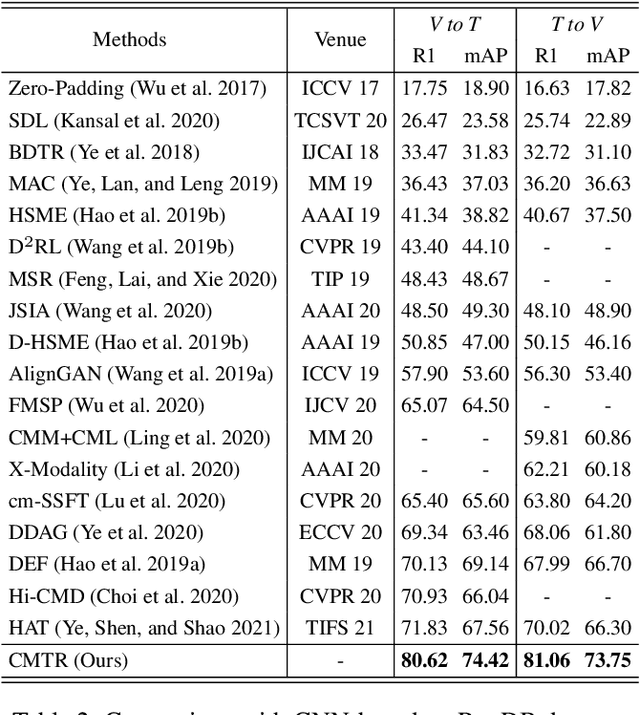
Visible-infrared cross-modality person re-identification is a challenging ReID task, which aims to retrieve and match the same identity's images between the heterogeneous visible and infrared modalities. Thus, the core of this task is to bridge the huge gap between these two modalities. The existing convolutional neural network-based methods mainly face the problem of insufficient perception of modalities' information, and can not learn good discriminative modality-invariant embeddings for identities, which limits their performance. To solve these problems, we propose a cross-modality transformer-based method (CMTR) for the visible-infrared person re-identification task, which can explicitly mine the information of each modality and generate better discriminative features based on it. Specifically, to capture modalities' characteristics, we design the novel modality embeddings, which are fused with token embeddings to encode modalities' information. Furthermore, to enhance representation of modality embeddings and adjust matching embeddings' distribution, we propose a modality-aware enhancement loss based on the learned modalities' information, reducing intra-class distance and enlarging inter-class distance. To our knowledge, this is the first work of applying transformer network to the cross-modality re-identification task. We implement extensive experiments on the public SYSU-MM01 and RegDB datasets, and our proposed CMTR model's performance significantly surpasses existing outstanding CNN-based methods.