 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMTR: Cross-modality Transformer for Visible-infrared Person Re-identification
Paper and Code
Oct 18, 2021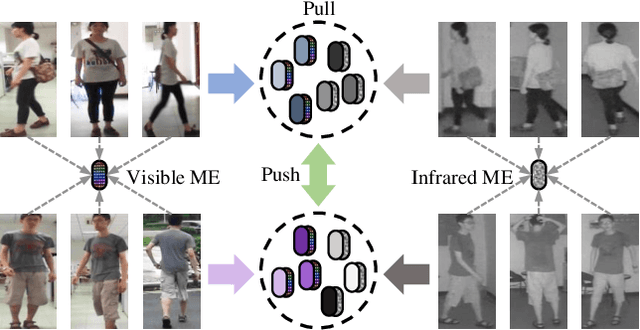
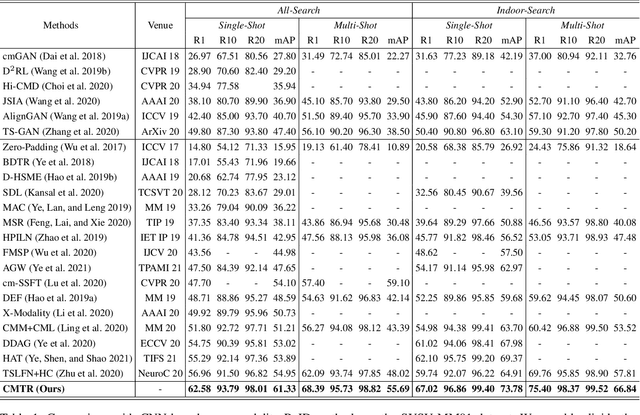
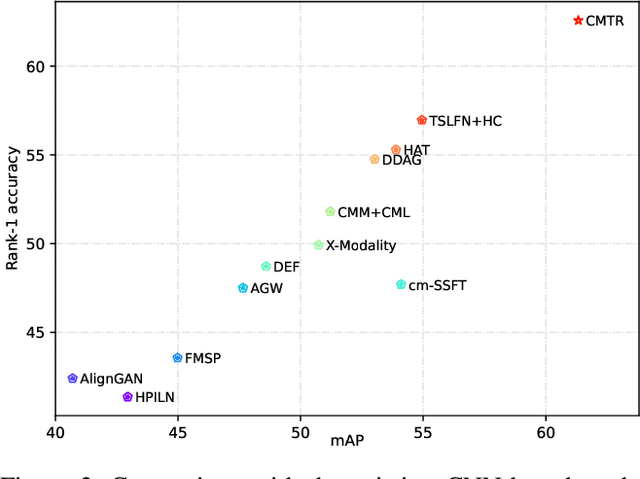
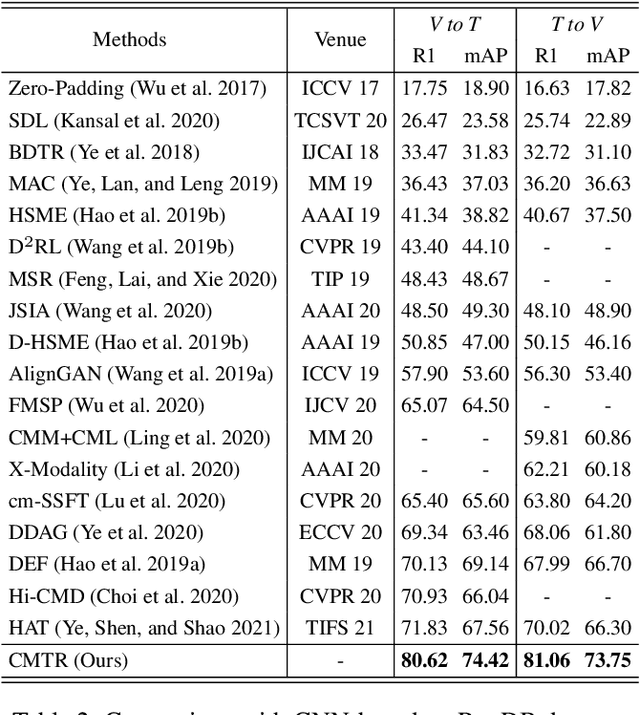
Visible-infrared cross-modality person re-identification is a challenging ReID task, which aims to retrieve and match the same identity's images between the heterogeneous visible and infrared modalities. Thus, the core of this task is to bridge the huge gap between these two modalities. The existing convolutional neural network-based methods mainly face the problem of insufficient perception of modalities' information, and can not learn good discriminative modality-invariant embeddings for identities, which limits their performance. To solve these problems, we propose a cross-modality transformer-based method (CMTR) for the visible-infrared person re-identification task, which can explicitly mine the information of each modality and generate better discriminative features based on it. Specifically, to capture modalities' characteristics, we design the novel modality embeddings, which are fused with token embeddings to encode modalities' information. Furthermore, to enhance representation of modality embeddings and adjust matching embeddings' distribution, we propose a modality-aware enhancement loss based on the learned modalities' information, reducing intra-class distance and enlarging inter-class distance. To our knowledge, this is the first work of applying transformer network to the cross-modality re-identification task. We implement extensive experiments on the public SYSU-MM01 and RegDB datasets, and our proposed CMTR model's performance significantly surpasses existing outstanding CNN-based methods.