 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWARM-CAT: : Warm-Started Test-Time Comprehensive Knowledge Accumulation for Compositional Zero-Shot Learning
Feb 26, 2026Compositional Zero-Shot Learning (CZSL) aims to recognize novel attribute-object compositions based on the knowledge learned from seen ones. Existing methods suffer from performance degradation caused by the distribution shift of label space at test time, which stems from the inclusion of unseen compositions recombined from attributes and objects. To overcome the challenge, we propose a novel approach that accumulates comprehensive knowledge in both textual and visual modalities from unsupervised data to update multimodal prototypes at test time. Building on this, we further design an adaptive update weight to control the degree of prototype adjustment, enabling the model to flexibly adapt to distribution shift during testing. Moreover, a dynamic priority queue is introduced that stores high-confidence images to acquire visual prototypes from historical images for inference. Since the model tends to favor compositions already stored in the queue during testing, we warm-start the queue by initializing it with training images for visual prototypes of seen compositions and generating unseen visual prototypes using the mapping learned between seen and unseen textual prototypes. Considering the semantic consistency of multimodal knowledge, we align textual and visual prototypes by multimodal collaborative representation learning. To provide a more reliable evaluation for CZSL, we introduce a new benchmark dataset, C-Fashion, and refine the widely used but noisy MIT-States dataset. Extensive experiments indicate that our approach achieves state-of-the-art performance on four benchmark datasets under both closed-world and open-world settings. The source code and datasets are available at https://github.com/xud-yan/WARM-CAT .
Leveraging MLLM Embeddings and Attribute Smoothing for Compositional Zero-Shot Learning
Nov 18, 2024Compositional zero-shot learning (CZSL) aims to recognize novel compositions of attributes and objects learned from seen compositions. Previous works disentangle attribute and object by extracting shared and exclusive parts between image pairs sharing the same attribute (object), as well as aligning them with pretrained word embeddings to improve unseen attribute-object recognition. Despite the significant achievements of existing efforts, they are hampered by three limitations: (1) the efficacy of disentanglement is compromised due to the influence of the background and the intricate entanglement of attribute with object in the same parts. (2) existing word embeddings fail to capture complex multimodal semantic information. (3) overconfidence exhibited by existing models in seen compositions hinders their generalization to novel compositions. Being aware of these, we propose a novel framework named Multimodal Large Language Model (MLLM) embeddings and attribute smoothing guided disentanglement (TRIDENT) for CZSL. First, we leverage feature adaptive aggregation modules to mitigate the impact of background, and utilize learnable condition masks to capture multigranularity features for disentanglement. Then, the last hidden states of MLLM are employed as word embeddings for their superior representation capabilities. Moreover, we propose attribute smoothing with auxiliary attributes generated by Large Language Model (LLM) for seen compositions, addressing the issue of overconfidence by encouraging the model to learn more attributes in one given composition. Extensive experiments demonstrate that TRIDENT achieves state-of-the-art performance on three benchmarks.
Test-Time Domain Adaptation by Learning Domain-Aware Batch Normalization
Dec 15, 2023Test-time domain adaptation aims to adapt the model trained on source domains to unseen target domains using a few unlabeled images. Emerging research has shown that the label and domain information is separately embedded in the weight matrix and batch normalization (BN) layer. Previous works normally update the whole network naively without explicitly decoupling the knowledge between label and domain. As a result, it leads to knowledge interference and defective distribution adaptation. In this work, we propose to reduce such learning interference and elevate the domain knowledge learning by only manipulating the BN layer. However, the normalization step in BN is intrinsically unstable when the statistics are re-estimated from a few samples. We find that ambiguities can be greatly reduced when only updating the two affine parameters in BN while keeping the source domain statistics. To further enhance the domain knowledge extraction from unlabeled data, we construct an auxiliary branch with label-independent self-supervised learning (SSL) to provide supervision. Moreover, we propose a bi-level optimization based on meta-learning to enforce the alignment of two learning objectives of auxiliary and main branches. The goal is to use the auxiliary branch to adapt the domain and benefit main task for subsequent inference. Our method keeps the same computational cost at inference as the auxiliary branch can be thoroughly discarded after adaptation. Extensive experiments show that our method outperforms the prior works on five WILDS real-world domain shift datasets. Our method can also be integrated with methods with label-dependent optimization to further push the performance boundary. Our code is available at https://github.com/ynanwu/MABN.
MetaGCD: Learning to Continually Learn in Generalized Category Discovery
Aug 21, 2023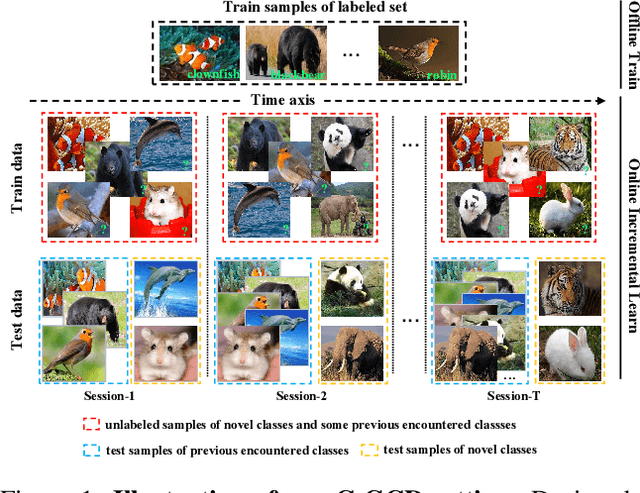

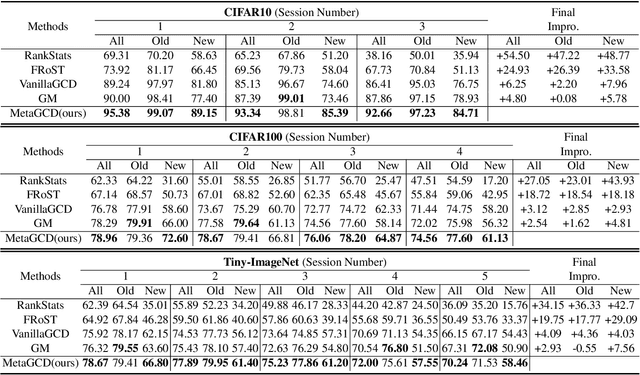
In this paper, we consider a real-world scenario where a model that is trained on pre-defined classes continually encounters unlabeled data that contains both known and novel classes. The goal is to continually discover novel classes while maintaining the performance in known classes. We name the setting Continual Generalized Category Discovery (C-GCD). Existing methods for novel class discovery cannot directly handle the C-GCD setting due to some unrealistic assumptions, such as the unlabeled data only containing novel classes. Furthermore, they fail to discover novel classes in a continual fashion. In this work, we lift all these assumptions and propose an approach, called MetaGCD, to learn how to incrementally discover with less forgetting. Our proposed method uses a meta-learning framework and leverages the offline labeled data to simulate the testing incremental learning process. A meta-objective is defined to revolve around two conflicting learning objectives to achieve novel class discovery without forgetting. Furthermore, a soft neighborhood-based contrastive network is proposed to discriminate uncorrelated images while attracting correlated images. We build strong baselines and conduct extensive experiments on three widely used benchmarks to demonstrate the superiority of our method.
Bridging the Gap: Multi-Level Cross-Modality Joint Alignment for Visible-Infrared Person Re-Identification
Jul 17, 2023Visible-Infrared person Re-IDentification (VI-ReID) is a challenging cross-modality image retrieval task that aims to match pedestrians' images across visible and infrared cameras. To solve the modality gap, existing mainstream methods adopt a learning paradigm converting the image retrieval task into an image classification task with cross-entropy loss and auxiliary metric learning losses. These losses follow the strategy of adjusting the distribution of extracted embeddings to reduce the intra-class distance and increase the inter-class distance. However, such objectives do not precisely correspond to the final test setting of the retrieval task, resulting in a new gap at the optimization level. By rethinking these keys of VI-ReID, we propose a simple and effective method, the Multi-level Cross-modality Joint Alignment (MCJA), bridging both modality and objective-level gap. For the former, we design the Modality Alignment Augmentation, which consists of three novel strategies, the weighted grayscale, cross-channel cutmix, and spectrum jitter augmentation, effectively reducing modality discrepancy in the image space. For the latter, we introduce a new Cross-Modality Retrieval loss. It is the first work to constrain from the perspective of the ranking list, aligning with the goal of the testing stage. Moreover, based on the global feature only, our method exhibits good performance and can serve as a strong baseline method for the VI-ReID community.
Deep Partial Multi-Label Learning with Graph Disambiguation
May 10, 2023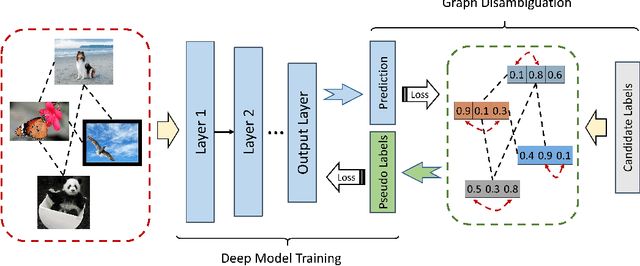
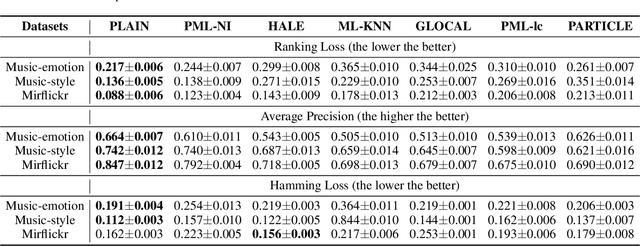

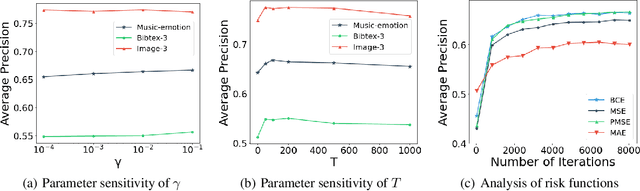
In partial multi-label learning (PML), each data example is equipped with a candidate label set, which consists of multiple ground-truth labels and other false-positive labels. Recently, graph-based methods, which demonstrate a good ability to estimate accurate confidence scores from candidate labels, have been prevalent to deal with PML problems. However, we observe that existing graph-based PML methods typically adopt linear multi-label classifiers and thus fail to achieve superior performance. In this work, we attempt to remove several obstacles for extending them to deep models and propose a novel deep Partial multi-Label model with grAph-disambIguatioN (PLAIN). Specifically, we introduce the instance-level and label-level similarities to recover label confidences as well as exploit label dependencies. At each training epoch, labels are propagated on the instance and label graphs to produce relatively accurate pseudo-labels; then, we train the deep model to fit the numerical labels. Moreover, we provide a careful analysis of the risk functions to guarantee the robustness of the proposed model. Extensive experiments on various synthetic datasets and three real-world PML datasets demonstrate that PLAIN achieves significantly superior results to state-of-the-art methods.
Semantic-Aware Graph Matching Mechanism for Multi-Label Image Recognition
Apr 21, 2023Multi-label image recognition aims to predict a set of labels that present in an image. The key to deal with such problem is to mine the associations between image contents and labels, and further obtain the correct assignments between images and their labels. In this paper, we treat each image as a bag of instances, and formulate the task of multi-label image recognition as an instance-label matching selection problem. To model such problem, we propose an innovative Semantic-aware Graph Matching framework for Multi-Label image recognition (ML-SGM), in which Graph Matching mechanism is introduced owing to its good performance of excavating the instance and label relationship. The framework explicitly establishes category correlations and instance-label correspondences by modeling the relation among content-aware (instance) and semantic-aware (label) category representations, to facilitate multi-label image understanding and reduce the dependency of large amounts of training samples for each category. Specifically, we first construct an instance spatial graph and a label semantic graph respectively and then incorporate them into a constructed assignment graph by connecting each instance to all labels. Subsequently, the graph network block is adopted to aggregate and update all nodes and edges state on the assignment graph to form structured representations for each instance and label. Our network finally derives a prediction score for each instance-label correspondence and optimizes such correspondence with a weighted cross-entropy loss. Empirical results conducted on generic multi-label image recognition demonstrate the superiority of our proposed method. Moreover, the proposed method also shows advantages in multi-label recognition with partial labels and multi-label few-shot learning, as well as outperforms current state-of-the-art methods with a clear margin.
Deep Probabilistic Graph Matching
Jan 05, 2022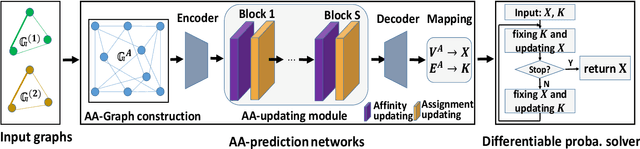
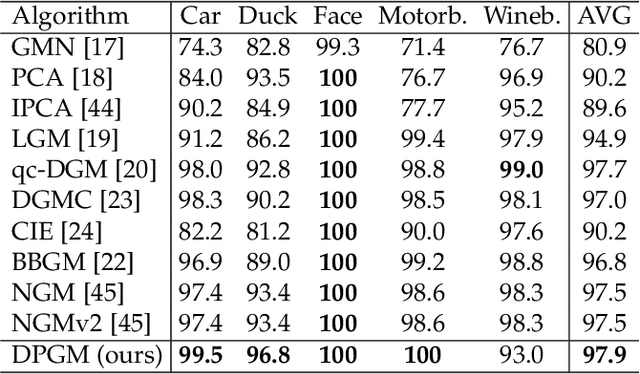
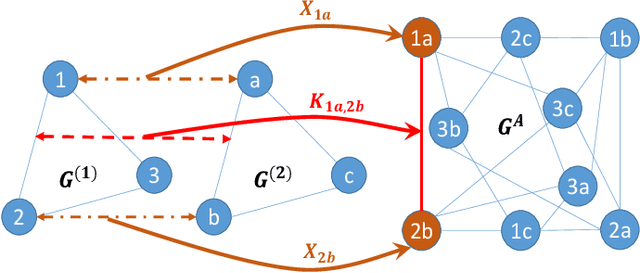
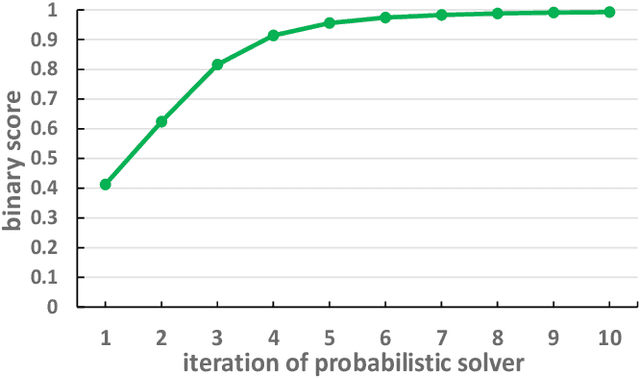
Most previous learning-based graph matching algorithms solve the \textit{quadratic assignment problem} (QAP) by dropping one or more of the matching constraints and adopting a relaxed assignment solver to obtain sub-optimal correspondences. Such relaxation may actually weaken the original graph matching problem, and in turn hurt the matching performance. In this paper we propose a deep learning-based graph matching framework that works for the original QAP without compromising on the matching constraints. In particular, we design an affinity-assignment prediction network to jointly learn the pairwise affinity and estimate the node assignments, and we then develop a differentiable solver inspired by the probabilistic perspective of the pairwise affinities. Aiming to obtain better matching results, the probabilistic solver refines the estimated assignments in an iterative manner to impose both discrete and one-to-one matching constraints. The proposed method is evaluated on three popularly tested benchmarks (Pascal VOC, Willow Object and SPair-71k), and it outperforms all previous state-of-the-arts on all benchmarks.
GLAN: A Graph-based Linear Assignment Network
Jan 05, 2022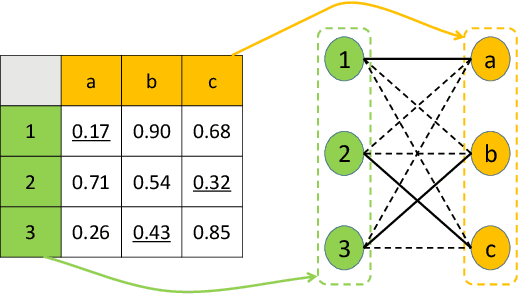
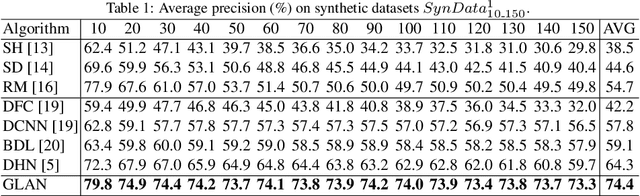
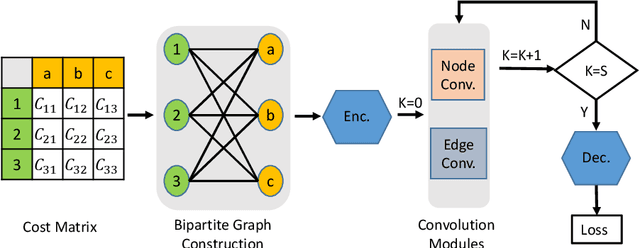

Differentiable solvers for the linear assignment problem (LAP) have attracted much research attention in recent years, which are usually embedded into learning frameworks as components. However, previous algorithms, with or without learning strategies, usually suffer from the degradation of the optimality with the increment of the problem size. In this paper, we propose a learnable linear assignment solver based on deep graph networks. Specifically, we first transform the cost matrix to a bipartite graph and convert the assignment task to the problem of selecting reliable edges from the constructed graph. Subsequently, a deep graph network is developed to aggregate and update the features of nodes and edges. Finally, the network predicts a label for each edge that indicates the assignment relationship. The experimental results on a synthetic dataset reveal that our method outperforms state-of-the-art baselines and achieves consistently high accuracy with the increment of the problem size. Furthermore, we also embed the proposed solver, in comparison with state-of-the-art baseline solvers, into a popular multi-object tracking (MOT) framework to train the tracker in an end-to-end manner. The experimental results on MOT benchmarks illustrate that the proposed LAP solver improves the tracker by the largest margin.
Clicking Matters:Towards Interactive Human Parsing
Nov 11, 2021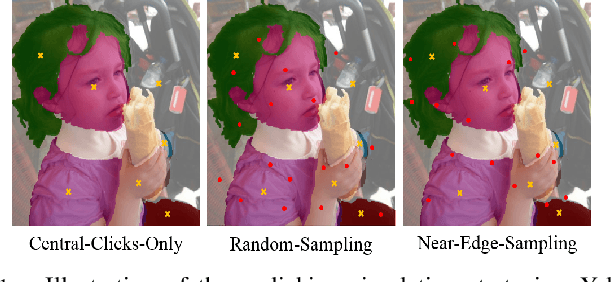
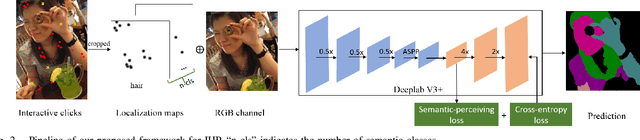
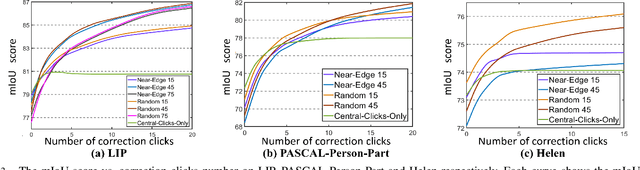
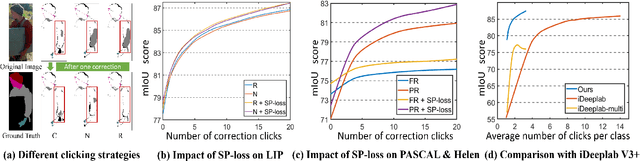
In this work, we focus on Interactive Human Parsing (IHP), which aims to segment a human image into multiple human body parts with guidance from users' interactions. This new task inherits the class-aware property of human parsing, which cannot be well solved by traditional interactive image segmentation approaches that are generally class-agnostic. To tackle this new task, we first exploit user clicks to identify different human parts in the given image. These clicks are subsequently transformed into semantic-aware localization maps, which are concatenated with the RGB image to form the input of the segmentation network and generate the initial parsing result. To enable the network to better perceive user's purpose during the correction process, we investigate several principal ways for the refinement, and reveal that random-sampling-based click augmentation is the best way for promoting the correction effectiveness. Furthermore, we also propose a semantic-perceiving loss (SP-loss) to augment the training, which can effectively exploit the semantic relationships of clicks for better optimization. To the best knowledge, this work is the first attempt to tackle the human parsing task under the interactive setting. Our IHP solution achieves 85\% mIoU on the benchmark LIP, 80\% mIoU on PASCAL-Person-Part and CIHP, 75\% mIoU on Helen with only 1.95, 3.02, 2.84 and 1.09 clicks per class respectively. These results demonstrate that we can simply acquire high-quality human parsing masks with only a few human effort. We hope this work can motivate more researchers to develop data-efficient solutions to IHP in the future.