 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Behavior and Semantics for Time-aware Cross-Domain Sequential Recommendation
May 04, 2026Cross-domain sequential recommendation (CDSR) alleviates interaction sparsity by jointly modeling user behaviors across multiple domains. While current studies have made some progresses, they still neglect two issues that severely impact recommendation performance: (i) ignoring domain-specific interaction frequencies and interest decay rates at identical time intervals; (ii) treating semantic preferences as time-invariant during cross-domain transfer. To address these, we propose a novel framework that bridges Behavior and Semantics for Time-aware Cross-Domain Sequential Recommendation (BST-CDSR). Specifically, we design a behavioral preference evolution module that decouples long-term interests and short-term intentions, and models continuous-time preference via a neural ordinary differential equation (ODE) with event-driven updates. Additionally, to capture time-aware semantic preferences, we introduce a temporal counterfactual-enhanced semantic generator that discretizes temporal interval tokens and leverages large language models (LLMs) to extract robust temporal semantics, where counterfactual perturbations enhance the time sensitivity of semantic preferences. Furthermore, we propose a time-preference guided domain transfer module to adaptively control transfer weights and mitigate negative transfer. Extensive experiments on real-world datasets demonstrate that BST-CDSR consistently outperforms baselines.
NG-GS: NeRF-Guided 3D Gaussian Splatting Segmentation
Apr 16, 2026Recent advances in 3D Gaussian Splatting (3DGS) have enabled highly efficient and photorealistic novel view synthesis. However, segmenting objects accurately in 3DGS remains challenging due to the discrete nature of Gaussian representations, which often leads to aliasing and artifacts at object boundaries. In this paper, we introduce NG-GS, a novel framework for high-quality object segmentation in 3DGS that explicitly addresses boundary discretization. Our approach begins by automatically identifying ambiguous Gaussians at object boundaries using mask variance analysis. We then apply radial basis function (RBF) interpolation to construct a spatially continuous feature field, enhanced by multi-resolution hash encoding for efficient multi-scale representation. A joint optimization strategy aligns 3DGS with a lightweight NeRF module through alignment and spatial continuity losses, ensuring smooth and consistent segmentation boundaries. Extensive experiments on NVOS, LERF-OVS, and ScanNet benchmarks demonstrate that our method achieves state-of-the-art performance, with significant gains in boundary mIoU. Code is available at https://github.com/BJTU-KD3D/NG-GS.
From Transfer to Collaboration: A Federated Framework for Cross-Market Sequential Recommendation
Apr 15, 2026Cross-market recommendation (CMR) aims to enhance recommendation performance across multiple markets. Due to its inherent characteristics, i.e., data isolation, non-overlapping users, and market heterogeneity, CMR introduces unique challenges and fundamentally differs from cross-domain recommendation (CDR). Existing CMR approaches largely inherit CDR by adopting the one-to-one transfer paradigm, where a model is pretrained on a source market and then fine-tuned on a target market. However, such a paradigm suffers from CH1. source degradation, where the source market sacrifices its own performance for the target markets, and CH2. negative transfer, where market heterogeneity leads to suboptimal performance in target markets. To address these challenges, we propose FeCoSR, a novel federated collaboration framework for cross-market sequential recommendation. Specifically, to tackle CH1, we introduce a many-to-many collaboration paradigm that enables all markets to jointly participate in and benefit from training. It consists of a federated pretraining stage for capturing shared behavior-level patterns, followed by local fine-tuning for market-specific item-level preferences. For CH2, we theoretically and empirically show that vanilla Cross-Entropy (CE) exacerbates market heterogeneity, undermining federated optimization. To address this, we propose a Semantic Soft Cross-Entropy (S^2CE) that leverages shared semantic information to facilitate collaborative behavioral learning across markets. Then, we design a market-specific adaptation module during fine-tuning to capture local item preferences. Extensive experiments on the real-world datasets demonstrate the advantages of FeCoSR over other methods.
CoLC: Communication-Efficient Collaborative Perception with LiDAR Completion
Feb 28, 2026Collaborative perception empowers autonomous agents to share complementary information and overcome perception limitations. While early fusion offers more perceptual complementarity and is inherently robust to model heterogeneity, its high communication cost has limited its practical deployment, prompting most existing works to favor intermediate or late fusion. To address this, we propose a communication-efficient early Collaborative perception framework that incorporates LiDAR Completion to restore scene completeness under sparse transmission, dubbed as CoLC. Specifically, the CoLC integrates three complementary designs. First, each neighbor agent applies Foreground-Aware Point Sampling (FAPS) to selectively transmit informative points that retain essential structural and contextual cues under bandwidth constraints. The ego agent then employs Completion-Enhanced Early Fusion (CEEF) to reconstruct dense pillars from the received sparse inputs and adaptively fuse them with its own observations, thereby restoring spatial completeness. Finally, the Dense-Guided Dual Alignment (DGDA) strategy enforces semantic and geometric consistency between the enhanced and dense pillars during training, ensuring consistent and robust feature learning. Experiments on both simulated and real-world datasets demonstrate that CoLC achieves superior perception-communication trade-offs and remains robust under heterogeneous model settings. The code is available at https://github.com/CatOneTwo/CoLC.
MDiffFR: Modality-Guided Diffusion Generation for Cold-start Items in Federated Recommendation
Dec 31, 2025Federated recommendations (FRs) provide personalized services while preserving user privacy by keeping user data on local clients, which has attracted significant attention in recent years. However, due to the strict privacy constraints inherent in FRs, access to user-item interaction data and user profiles across clients is highly restricted, making it difficult to learn globally effective representations for new (cold-start) items. Consequently, the item cold-start problem becomes even more challenging in FRs. Existing solutions typically predict embeddings for new items through the attribute-to-embedding mapping paradigm, which establishes a fixed one-to-one correspondence between item attributes and their embeddings. However, this one-to-one mapping paradigm often fails to model varying data distributions and tends to cause embedding misalignment, as verified by our empirical studies. To this end, we propose MDiffFR, a novel generation-based modality-guided diffusion method for cold-start items in FRs. In this framework, we employ a tailored diffusion model on the server to generate embeddings for new items, which are then distributed to clients for cold-start inference. To align item semantics, we deploy a pre-trained modality encoder to extract modality features as conditional signals to guide the reverse denoising process. Furthermore, our theoretical analysis verifies that the proposed method achieves stronger privacy guarantees compared to existing mapping-based approaches. Extensive experiments on four real datasets demonstrate that our method consistently outperforms all baselines in FRs.
Neural Variable-Order Fractional Differential Equation Networks
Mar 20, 2025


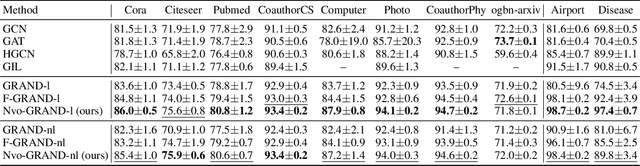
Neural differential equation models have garnered significant attention in recent years for their effectiveness in machine learning applications.Among these, fractional differential equations (FDEs) have emerged as a promising tool due to their ability to capture memory-dependent dynamics, which are often challenging to model with traditional integer-order approaches.While existing models have primarily focused on constant-order fractional derivatives, variable-order fractional operators offer a more flexible and expressive framework for modeling complex memory patterns. In this work, we introduce the Neural Variable-Order Fractional Differential Equation network (NvoFDE), a novel neural network framework that integrates variable-order fractional derivatives with learnable neural networks.Our framework allows for the modeling of adaptive derivative orders dependent on hidden features, capturing more complex feature-updating dynamics and providing enhanced flexibility. We conduct extensive experiments across multiple graph datasets to validate the effectiveness of our approach.Our results demonstrate that NvoFDE outperforms traditional constant-order fractional and integer models across a range of tasks, showcasing its superior adaptability and performance.
CoDTS: Enhancing Sparsely Supervised Collaborative Perception with a Dual Teacher-Student Framework
Dec 12, 2024



Current collaborative perception methods often rely on fully annotated datasets, which can be expensive to obtain in practical situations. To reduce annotation costs, some works adopt sparsely supervised learning techniques and generate pseudo labels for the missing instances. However, these methods fail to achieve an optimal confidence threshold that harmonizes the quality and quantity of pseudo labels. To address this issue, we propose an end-to-end Collaborative perception Dual Teacher-Student framework (CoDTS), which employs adaptive complementary learning to produce both high-quality and high-quantity pseudo labels. Specifically, the Main Foreground Mining (MFM) module generates high-quality pseudo labels based on the prediction of the static teacher. Subsequently, the Supplement Foreground Mining (SFM) module ensures a balance between the quality and quantity of pseudo labels by adaptively identifying missing instances based on the prediction of the dynamic teacher. Additionally, the Neighbor Anchor Sampling (NAS) module is incorporated to enhance the representation of pseudo labels. To promote the adaptive complementary learning, we implement a staged training strategy that trains the student and dynamic teacher in a mutually beneficial manner. Extensive experiments demonstrate that the CoDTS effectively ensures an optimal balance of pseudo labels in both quality and quantity, establishing a new state-of-the-art in sparsely supervised collaborative perception.
A Tutorial of Personalized Federated Recommender Systems: Recent Advances and Future Directions
Dec 11, 2024Personalization stands as the cornerstone of recommender systems (RecSys), striving to sift out redundant information and offer tailor-made services for users. However, the conventional cloud-based RecSys necessitates centralized data collection, posing significant risks of user privacy breaches. In response to this challenge, federated recommender systems (FedRecSys) have emerged, garnering considerable attention. FedRecSys enable users to retain personal data locally and solely share model parameters with low privacy sensitivity for global model training, significantly bolstering the system's privacy protection capabilities. Within the distributed learning framework, the pronounced non-iid nature of user behavior data introduces fresh hurdles to federated optimization. Meanwhile, the ability of federated learning to concurrently learn multiple models presents an opportunity for personalized user modeling. Consequently, the development of personalized FedRecSys (PFedRecSys) is crucial and holds substantial significance. This tutorial seeks to provide an introduction to PFedRecSys, encompassing (1) an overview of existing studies on PFedRecSys, (2) a comprehensive taxonomy of PFedRecSys spanning four pivotal research directions-client-side adaptation, server-side aggregation, communication efficiency, privacy and protection, and (3) exploration of open challenges and promising future directions in PFedRecSys. This tutorial aims to establish a robust foundation and spark new perspectives for subsequent exploration and practical implementations in the evolving realm of RecSys.
GrassNet: State Space Model Meets Graph Neural Network
Aug 16, 2024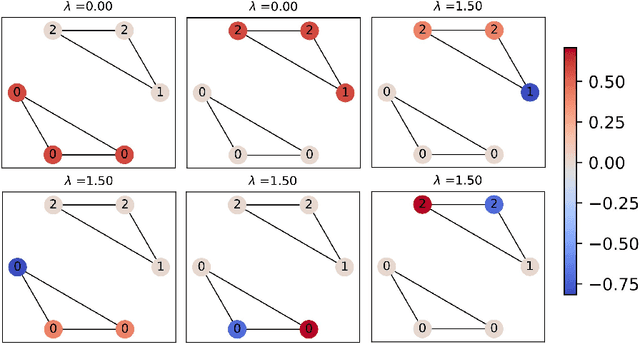


Designing spectral convolutional networks is a formidable task in graph learning. In traditional spectral graph neural networks (GNNs), polynomial-based methods are commonly used to design filters via the Laplacian matrix. In practical applications, however, these polynomial methods encounter inherent limitations, which primarily arise from the the low-order truncation of polynomial filters and the lack of overall modeling of the graph spectrum. This leads to poor performance of existing spectral approaches on real-world graph data, especially when the spectrum is highly concentrated or contains many numerically identical values, as they tend to apply the exact same modulation to signals with the same frequencies. To overcome these issues, in this paper, we propose Graph State Space Network (GrassNet), a novel graph neural network with theoretical support that provides a simple yet effective scheme for designing and learning arbitrary graph spectral filters. In particular, our GrassNet introduces structured state space models (SSMs) to model the correlations of graph signals at different frequencies and derives a unique rectification for each frequency in the graph spectrum. To the best of our knowledge, our work is the first to employ SSMs for the design of GNN spectral filters, and it theoretically offers greater expressive power compared with polynomial filters. Extensive experiments on nine public benchmarks reveal that GrassNet achieves superior performance in real-world graph modeling tasks.
Beyond Similarity: Personalized Federated Recommendation with Composite Aggregation
Jun 06, 2024Federated recommendation aims to collect global knowledge by aggregating local models from massive devices, to provide recommendations while ensuring privacy. Current methods mainly leverage aggregation functions invented by federated vision community to aggregate parameters from similar clients, e.g., clustering aggregation. Despite considerable performance, we argue that it is suboptimal to apply them to federated recommendation directly. This is mainly reflected in the disparate model architectures. Different from structured parameters like convolutional neural networks in federated vision, federated recommender models usually distinguish itself by employing one-to-one item embedding table. Such a discrepancy induces the challenging embedding skew issue, which continually updates the trained embeddings but ignores the non-trained ones during aggregation, thus failing to predict future items accurately. To this end, we propose a personalized Federated recommendation model with Composite Aggregation (FedCA), which not only aggregates similar clients to enhance trained embeddings, but also aggregates complementary clients to update non-trained embeddings. Besides, we formulate the overall learning process into a unified optimization algorithm to jointly learn the similarity and complementarity. Extensive experiments on several real-world datasets substantiate the effectiveness of our proposed model. The source codes are available at https://github.com/hongleizhang/FedCA.