 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrassNet: State Space Model Meets Graph Neural Network
Aug 16, 2024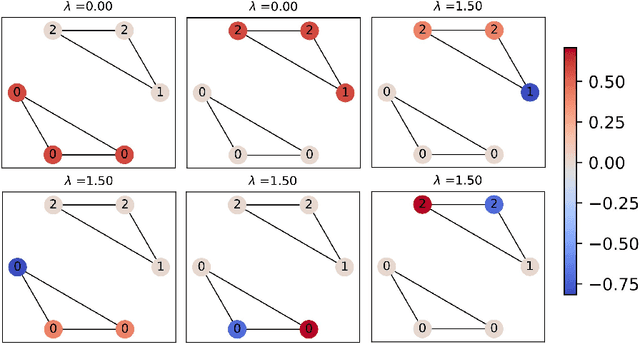


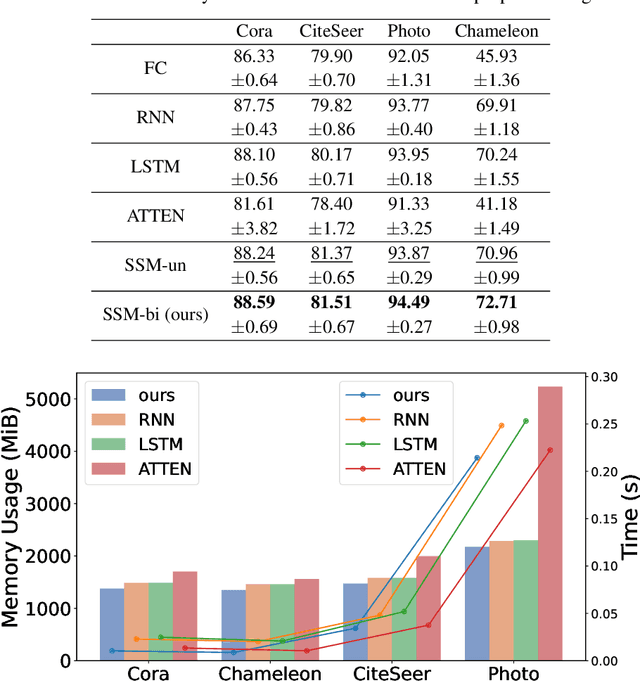
Designing spectral convolutional networks is a formidable task in graph learning. In traditional spectral graph neural networks (GNNs), polynomial-based methods are commonly used to design filters via the Laplacian matrix. In practical applications, however, these polynomial methods encounter inherent limitations, which primarily arise from the the low-order truncation of polynomial filters and the lack of overall modeling of the graph spectrum. This leads to poor performance of existing spectral approaches on real-world graph data, especially when the spectrum is highly concentrated or contains many numerically identical values, as they tend to apply the exact same modulation to signals with the same frequencies. To overcome these issues, in this paper, we propose Graph State Space Network (GrassNet), a novel graph neural network with theoretical support that provides a simple yet effective scheme for designing and learning arbitrary graph spectral filters. In particular, our GrassNet introduces structured state space models (SSMs) to model the correlations of graph signals at different frequencies and derives a unique rectification for each frequency in the graph spectrum. To the best of our knowledge, our work is the first to employ SSMs for the design of GNN spectral filters, and it theoretically offers greater expressive power compared with polynomial filters. Extensive experiments on nine public benchmarks reveal that GrassNet achieves superior performance in real-world graph modeling tasks.
DFA-GNN: Forward Learning of Graph Neural Networks by Direct Feedback Alignment
Jun 04, 2024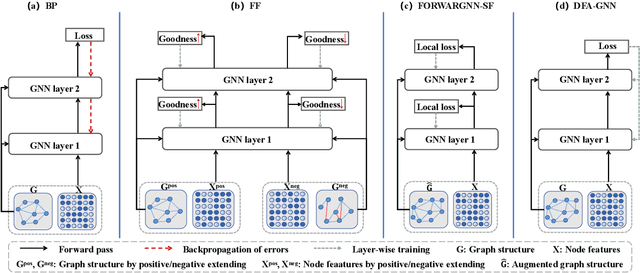
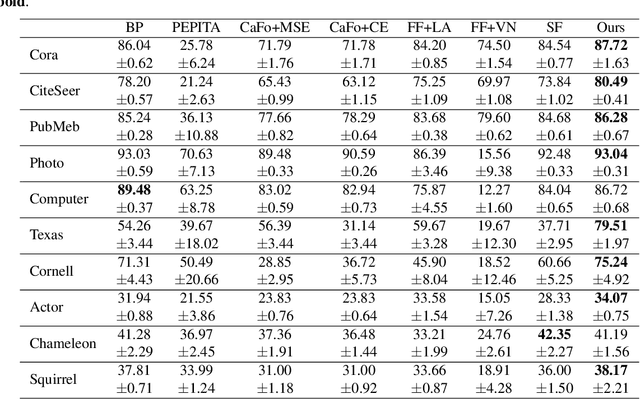
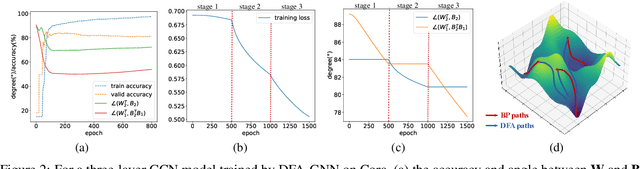
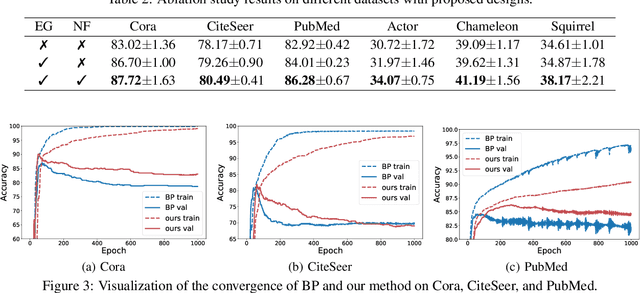
Graph neural networks are recognized for their strong performance across various applications, with the backpropagation algorithm playing a central role in the development of most GNN models. However, despite its effectiveness, BP has limitations that challenge its biological plausibility and affect the efficiency, scalability and parallelism of training neural networks for graph-based tasks. While several non-BP training algorithms, such as the direct feedback alignment, have been successfully applied to fully-connected and convolutional network components for handling Euclidean data, directly adapting these non-BP frameworks to manage non-Euclidean graph data in GNN models presents significant challenges. These challenges primarily arise from the violation of the i.i.d. assumption in graph data and the difficulty in accessing prediction errors for all samples (nodes) within the graph. To overcome these obstacles, in this paper we propose DFA-GNN, a novel forward learning framework tailored for GNNs with a case study of semi-supervised learning. The proposed method breaks the limitations of BP by using a dedicated forward training mechanism. Specifically, DFA-GNN extends the principles of DFA to adapt to graph data and unique architecture of GNNs, which incorporates the information of graph topology into the feedback links to accommodate the non-Euclidean characteristics of graph data. Additionally, for semi-supervised graph learning tasks, we developed a pseudo error generator that spreads residual errors from training data to create a pseudo error for each unlabeled node. These pseudo errors are then utilized to train GNNs using DFA. Extensive experiments on 10 public benchmarks reveal that our learning framework outperforms not only previous non-BP methods but also the standard BP methods, and it exhibits excellent robustness against various types of noise and attacks.
The Cascaded Forward Algorithm for Neural Network Training
Mar 24, 2023



Backpropagation algorithm has been widely used as a mainstream learning procedure for neural networks in the past decade, and has played a significant role in the development of deep learning. However, there exist some limitations associated with this algorithm, such as getting stuck in local minima and experiencing vanishing/exploding gradients, which have led to questions about its biological plausibility. To address these limitations, alternative algorithms to backpropagation have been preliminarily explored, with the Forward-Forward (FF) algorithm being one of the most well-known. In this paper we propose a new learning framework for neural networks, namely Cascaded Forward (CaFo) algorithm, which does not rely on BP optimization as that in FF. Unlike FF, our framework directly outputs label distributions at each cascaded block, which does not require generation of additional negative samples and thus leads to a more efficient process at both training and testing. Moreover, in our framework each block can be trained independently, so it can be easily deployed into parallel acceleration systems. The proposed method is evaluated on four public image classification benchmarks, and the experimental results illustrate significant improvement in prediction accuracy in comparison with the baseline.