 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUV-M3TL: A Unified and Versatile Multimodal Multi-Task Learning Framework for Assistive Driving Perception
Feb 02, 2026Advanced Driver Assistance Systems (ADAS) need to understand human driver behavior while perceiving their navigation context, but jointly learning these heterogeneous tasks would cause inter-task negative transfer and impair system performance. Here, we propose a Unified and Versatile Multimodal Multi-Task Learning (UV-M3TL) framework to simultaneously recognize driver behavior, driver emotion, vehicle behavior, and traffic context, while mitigating inter-task negative transfer. Our framework incorporates two core components: dual-branch spatial channel multimodal embedding (DB-SCME) and adaptive feature-decoupled multi-task loss (AFD-Loss). DB-SCME enhances cross-task knowledge transfer while mitigating task conflicts by employing a dual-branch structure to explicitly model salient task-shared and task-specific features. AFD-Loss improves the stability of joint optimization while guiding the model to learn diverse multi-task representations by introducing an adaptive weighting mechanism based on learning dynamics and feature decoupling constraints. We evaluate our method on the AIDE dataset, and the experimental results demonstrate that UV-M3TL achieves state-of-the-art performance across all four tasks. To further prove the versatility, we evaluate UV-M3TL on additional public multi-task perception benchmarks (BDD100K, CityScapes, NYUD-v2, and PASCAL-Context), where it consistently delivers strong performance across diverse task combinations, attaining state-of-the-art results on most tasks.
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory
Dec 22, 2025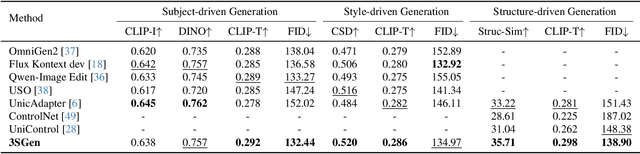
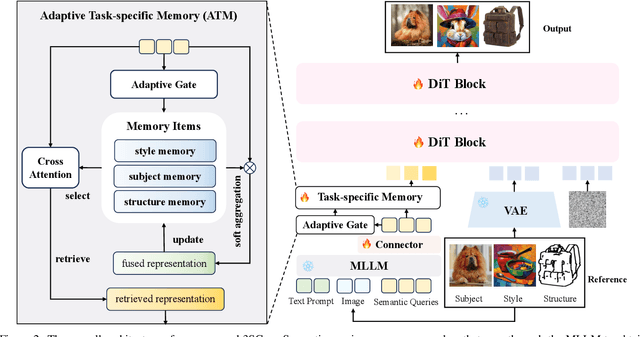
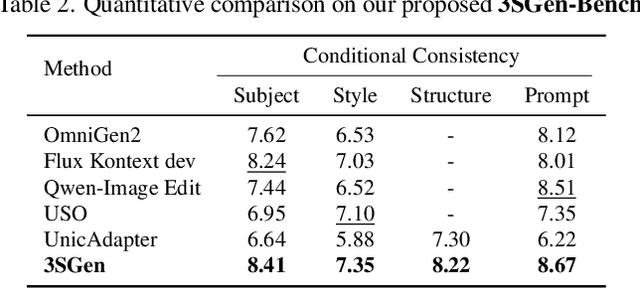
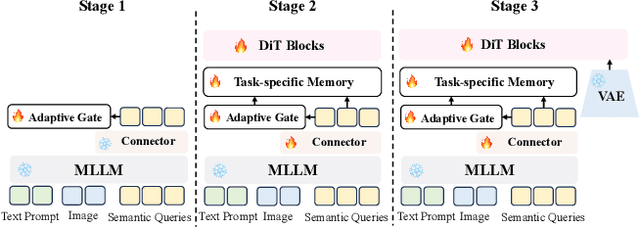
Recent image generation approaches often address subject, style, and structure-driven conditioning in isolation, leading to feature entanglement and limited task transferability. In this paper, we introduce 3SGen, a task-aware unified framework that performs all three conditioning modes within a single model. 3SGen employs an MLLM equipped with learnable semantic queries to align text-image semantics, complemented by a VAE branch that preserves fine-grained visual details. At its core, an Adaptive Task-specific Memory (ATM) module dynamically disentangles, stores, and retrieves condition-specific priors, such as identity for subjects, textures for styles, and spatial layouts for structures, via a lightweight gating mechanism along with several scalable memory items. This design mitigates inter-task interference and naturally scales to compositional inputs. In addition, we propose 3SGen-Bench, a unified image-driven generation benchmark with standardized metrics for evaluating cross-task fidelity and controllability. Extensive experiments on our proposed 3SGen-Bench and other public benchmarks demonstrate our superior performance across diverse image-driven generation tasks.
TTP: Test-Time Padding for Adversarial Detection and Robust Adaptation on Vision-Language Models
Dec 18, 2025



Vision-Language Models (VLMs), such as CLIP, have achieved impressive zero-shot recognition performance but remain highly susceptible to adversarial perturbations, posing significant risks in safety-critical scenarios. Previous training-time defenses rely on adversarial fine-tuning, which requires labeled data and costly retraining, while existing test-time strategies fail to reliably distinguish between clean and adversarial inputs, thereby preventing both adversarial robustness and clean accuracy from reaching their optimum. To address these limitations, we propose Test-Time Padding (TTP), a lightweight defense framework that performs adversarial detection followed by targeted adaptation at inference. TTP identifies adversarial inputs via the cosine similarity shift between CLIP feature embeddings computed before and after spatial padding, yielding a universal threshold for reliable detection across architectures and datasets. For detected adversarial cases, TTP employs trainable padding to restore disrupted attention patterns, coupled with a similarity-aware ensemble strategy for a more robust final prediction. For clean inputs, TTP leaves them unchanged by default or optionally integrates existing test-time adaptation techniques for further accuracy gains. Comprehensive experiments on diverse CLIP backbones and fine-grained benchmarks show that TTP consistently surpasses state-of-the-art test-time defenses, delivering substantial improvements in adversarial robustness without compromising clean accuracy. The code for this paper will be released soon.
On-the-fly Large-scale 3D Reconstruction from Multi-Camera Rigs
Dec 09, 2025Recent advances in 3D Gaussian Splatting (3DGS) have enabled efficient free-viewpoint rendering and photorealistic scene reconstruction. While on-the-fly extensions of 3DGS have shown promise for real-time reconstruction from monocular RGB streams, they often fail to achieve complete 3D coverage due to the limited field of view (FOV). Employing a multi-camera rig fundamentally addresses this limitation. In this paper, we present the first on-the-fly 3D reconstruction framework for multi-camera rigs. Our method incrementally fuses dense RGB streams from multiple overlapping cameras into a unified Gaussian representation, achieving drift-free trajectory estimation and efficient online reconstruction. We propose a hierarchical camera initialization scheme that enables coarse inter-camera alignment without calibration, followed by a lightweight multi-camera bundle adjustment that stabilizes trajectories while maintaining real-time performance. Furthermore, we introduce a redundancy-free Gaussian sampling strategy and a frequency-aware optimization scheduler to reduce the number of Gaussian primitives and the required optimization iterations, thereby maintaining both efficiency and reconstruction fidelity. Our method reconstructs hundreds of meters of 3D scenes within just 2 minutes using only raw multi-camera video streams, demonstrating unprecedented speed, robustness, and Fidelity for on-the-fly 3D scene reconstruction.
Weakly Supervised Cloud Detection Combining Spectral Features and Multi-Scale Deep Network
Oct 01, 2025Clouds significantly affect the quality of optical satellite images, which seriously limits their precise application. Recently, deep learning has been widely applied to cloud detection and has achieved satisfactory results. However, the lack of distinctive features in thin clouds and the low quality of training samples limit the cloud detection accuracy of deep learning methods, leaving space for further improvements. In this paper, we propose a weakly supervised cloud detection method that combines spectral features and multi-scale scene-level deep network (SpecMCD) to obtain highly accurate pixel-level cloud masks. The method first utilizes a progressive training framework with a multi-scale scene-level dataset to train the multi-scale scene-level cloud detection network. Pixel-level cloud probability maps are then obtained by combining the multi-scale probability maps and cloud thickness map based on the characteristics of clouds in dense cloud coverage and large cloud-area coverage images. Finally, adaptive thresholds are generated based on the differentiated regions of the scene-level cloud masks at different scales and combined with distance-weighted optimization to obtain binary cloud masks. Two datasets, WDCD and GF1MS-WHU, comprising a total of 60 Gaofen-1 multispectral (GF1-MS) images, were used to verify the effectiveness of the proposed method. Compared to the other weakly supervised cloud detection methods such as WDCD and WSFNet, the F1-score of the proposed SpecMCD method shows an improvement of over 7.82%, highlighting the superiority and potential of the SpecMCD method for cloud detection under different cloud coverage conditions.
Encouraging Good Processes Without the Need for Good Answers: Reinforcement Learning for LLM Agent Planning
Aug 27, 2025The functionality of Large Language Model (LLM) agents is primarily determined by two capabilities: action planning and answer summarization. The former, action planning, is the core capability that dictates an agent's performance. However, prevailing training paradigms employ end-to-end, multi-objective optimization that jointly trains both capabilities. This paradigm faces two critical challenges: imbalanced optimization objective allocation and scarcity of verifiable data, making it difficult to enhance the agent's planning capability. To address these challenges, we propose Reinforcement Learning with Tool-use Rewards (RLTR), a novel framework that decouples the training process to enable a focused, single-objective optimization of the planning module. Crucially, RLTR introduces a reward signal based on tool-use completeness to directly evaluate the quality of tool invocation sequences. This method offers a more direct and reliable training signal than assessing the final response content, thereby obviating the need for verifiable data. Our experiments demonstrate that RLTR achieves an 8%-12% improvement in planning performance compared to end-to-end baselines. Moreover, this enhanced planning capability, in turn, translates to a 5%-6% increase in the final response quality of the overall agent system.
Learn to Preserve Personality: Federated Foundation Models in Recommendations
Jun 13, 2025A core learning challenge for existed Foundation Models (FM) is striking the tradeoff between generalization with personalization, which is a dilemma that has been highlighted by various parameter-efficient adaptation techniques. Federated foundation models (FFM) provide a structural means to decouple shared knowledge from individual specific adaptations via decentralized processes. Recommendation systems offer a perfect testbed for FFMs, given their reliance on rich implicit feedback reflecting unique user characteristics. This position paper discusses a novel learning paradigm where FFMs not only harness their generalization capabilities but are specifically designed to preserve the integrity of user personality, illustrated thoroughly within the recommendation contexts. We envision future personal agents, powered by personalized adaptive FMs, guiding user decisions on content. Such an architecture promises a user centric, decentralized system where individuals maintain control over their personalized agents.
Scientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
Jun 12, 2025Scientific discoveries increasingly rely on complex multimodal reasoning based on information-intensive scientific data and domain-specific expertise. Empowered by expert-level scientific benchmarks, scientific Multimodal Large Language Models (MLLMs) hold the potential to significantly enhance this discovery process in realistic workflows. However, current scientific benchmarks mostly focus on evaluating the knowledge understanding capabilities of MLLMs, leading to an inadequate assessment of their perception and reasoning abilities. To address this gap, we present the Scientists' First Exam (SFE) benchmark, designed to evaluate the scientific cognitive capacities of MLLMs through three interconnected levels: scientific signal perception, scientific attribute understanding, scientific comparative reasoning. Specifically, SFE comprises 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines. Extensive experiments reveal that current state-of-the-art GPT-o3 and InternVL-3 achieve only 34.08% and 26.52% on SFE, highlighting significant room for MLLMs to improve in scientific realms. We hope the insights obtained in SFE will facilitate further developments in AI-enhanced scientific discoveries.
S2R-Bench: A Sim-to-Real Evaluation Benchmark for Autonomous Driving
May 24, 2025



Safety is a long-standing and the final pursuit in the development of autonomous driving systems, with a significant portion of safety challenge arising from perception. How to effectively evaluate the safety as well as the reliability of perception algorithms is becoming an emerging issue. Despite its critical importance, existing perception methods exhibit a limitation in their robustness, primarily due to the use of benchmarks are entierly simulated, which fail to align predicted results with actual outcomes, particularly under extreme weather conditions and sensor anomalies that are prevalent in real-world scenarios. To fill this gap, in this study, we propose a Sim-to-Real Evaluation Benchmark for Autonomous Driving (S2R-Bench). We collect diverse sensor anomaly data under various road conditions to evaluate the robustness of autonomous driving perception methods in a comprehensive and realistic manner. This is the first corruption robustness benchmark based on real-world scenarios, encompassing various road conditions, weather conditions, lighting intensities, and time periods. By comparing real-world data with simulated data, we demonstrate the reliability and practical significance of the collected data for real-world applications. We hope that this dataset will advance future research and contribute to the development of more robust perception models for autonomous driving. This dataset is released on https://github.com/adept-thu/S2R-Bench.
MMTL-UniAD: A Unified Framework for Multimodal and Multi-Task Learning in Assistive Driving Perception
Apr 03, 2025Advanced driver assistance systems require a comprehensive understanding of the driver's mental/physical state and traffic context but existing works often neglect the potential benefits of joint learning between these tasks. This paper proposes MMTL-UniAD, a unified multi-modal multi-task learning framework that simultaneously recognizes driver behavior (e.g., looking around, talking), driver emotion (e.g., anxiety, happiness), vehicle behavior (e.g., parking, turning), and traffic context (e.g., traffic jam, traffic smooth). A key challenge is avoiding negative transfer between tasks, which can impair learning performance. To address this, we introduce two key components into the framework: one is the multi-axis region attention network to extract global context-sensitive features, and the other is the dual-branch multimodal embedding to learn multimodal embeddings from both task-shared and task-specific features. The former uses a multi-attention mechanism to extract task-relevant features, mitigating negative transfer caused by task-unrelated features. The latter employs a dual-branch structure to adaptively adjust task-shared and task-specific parameters, enhancing cross-task knowledge transfer while reducing task conflicts. We assess MMTL-UniAD on the AIDE dataset, using a series of ablation studies, and show that it outperforms state-of-the-art methods across all four tasks. The code is available on https://github.com/Wenzhuo-Liu/MMTL-UniAD.