 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\mathcal{B}^{3}$-Net: Controlled Posterior Bridge Learning for Multi-Task Dense Prediction
May 07, 2026Multi-task dense prediction solves complementary pixel-level tasks in a unified model, such as semantic segmentation, depth estimation, surface normal estimation, and edge detection. Existing decoder-side interactions use attention, prompts, routing, diffusion, Mamba, or bridge features to exchange task evidence, but most of them organize this evidence implicitly. They usually fuse task features by similarity or affinity, without explicitly modeling that evidence reliability varies across tasks and spatial locations. As a result, unreliable evidence may contaminate the shared representation and intensify negative transfer. We propose $\mathcal{B}^{3}$-Net, a controlled posterior bridge learning framework for multi-task dense prediction. Our method decomposes decoder-side interaction into reliability estimation, posterior bridge construction, and bounded redistribution. The Precision Field Estimator estimates patch-wise evidence precision from task-reference alignment and local variation. The Posterior Bridge Operator builds a precision-weighted posterior bridge through heteroscedastic evidence fusion, yielding a shared state more reliable than uniform or heuristic mixtures. The Contractive Dispatch Operator redistributes the bridge to each task branch through a bounded update, reducing uncontrolled feature injection. Experiments on NYUD-v2, PASCAL-Context, and Cityscapes show that $\mathcal{B}^{3}$-Net achieves competitive or superior trade-offs over representative CNN-, Transformer-, diffusion-, Mamba-, and bridge-feature-based methods. Backbone-matched comparisons and extensive analyses further verify that the gains arise from controlled posterior bridge learning rather than backbone capacity or decoder scale.
M\textsuperscript{4}Fuse: Lightweight State-Space MoE with a Cross-Scale Gating Bridge for Brain Tumor Segmentation
May 04, 2026Encoder-decoder imbalance and the reliance on large input volumes make many 3D brain tumor segmentation models both compute-heavy and brittle. We present M\textsuperscript{4}Fuse, a lightweight network that prioritizes discriminative brain tumor cues over exhaustive appearance reconstruction. Our method balances encoder and decoder capacity and replaces depth expansion with a synergistic design: it propagates long-range context with linear complexity via a grouped state space mixer, denoises and aligns skip features using a cross-scale dual-stage gating bridge, and absorbs cross-site acquisition shifts with a sample-level mixture-of-experts. On the BraTS2019 and BraTS2021 benchmarks, M\textsuperscript{4}Fuse outperforms other lightweight excellent methods in both parameter count and performance. Even at a challenging input resolution of \(64\times128\times128\) (half that of existing excellent models), M\textsuperscript{4}Fuse reduces parameters by 62.63\% and improves average performance by 0.09\%. Ablations of key components validate the method's exceptional parameter-to-accuracy efficiency and robustness across diverse data centers.
* 10 pages,3 figures,CVPR 2026 findings
CLoE: Expert Consistency Learning for Missing Modality Segmentation
Mar 10, 2026Multimodal medical image segmentation often faces missing modalities at inference, which induces disagreement among modality experts and makes fusion unstable, particularly on small foreground structures. We propose Consistency Learning of Experts (CLoE), a consistency-driven framework for missing-modality segmentation that preserves strong performance when all modalities are available. CLoE formulates robustness as decision-level expert consistency control and introduces a dual-branch Expert Consistency Learning objective. Modality Expert Consistency enforces global agreement among expert predictions to reduce case-wise drift under partial inputs, while Region Expert Consistency emphasizes agreement on clinically critical foreground regions to avoid background-dominated regularization. We further map consistency scores to modality reliability weights using a lightweight gating network, enabling reliability-aware feature recalibration before fusion. Extensive experiments on BraTS 2020 and MSD Prostate demonstrate that CLoE outperforms state-of-the-art methods in incomplete multimodal segmentation, while exhibiting strong cross-dataset generalization and improving robustness on clinically critical structures.
DCL-SE: Dynamic Curriculum Learning for Spatiotemporal Encoding of Brain Imaging
Nov 19, 2025



High-dimensional neuroimaging analyses for clinical diagnosis are often constrained by compromises in spatiotemporal fidelity and by the limited adaptability of large-scale, general-purpose models. To address these challenges, we introduce Dynamic Curriculum Learning for Spatiotemporal Encoding (DCL-SE), an end-to-end framework centered on data-driven spatiotemporal encoding (DaSE). We leverage Approximate Rank Pooling (ARP) to efficiently encode three-dimensional volumetric brain data into information-rich, two-dimensional dynamic representations, and then employ a dynamic curriculum learning strategy, guided by a Dynamic Group Mechanism (DGM), to progressively train the decoder, refining feature extraction from global anatomical structures to fine pathological details. Evaluated across six publicly available datasets, including Alzheimer's disease and brain tumor classification, cerebral artery segmentation, and brain age prediction, DCL-SE consistently outperforms existing methods in accuracy, robustness, and interpretability. These findings underscore the critical importance of compact, task-specific architectures in the era of large-scale pretrained networks.
MIPD: A Multi-sensory Interactive Perception Dataset for Embodied Intelligent Driving
Nov 08, 2024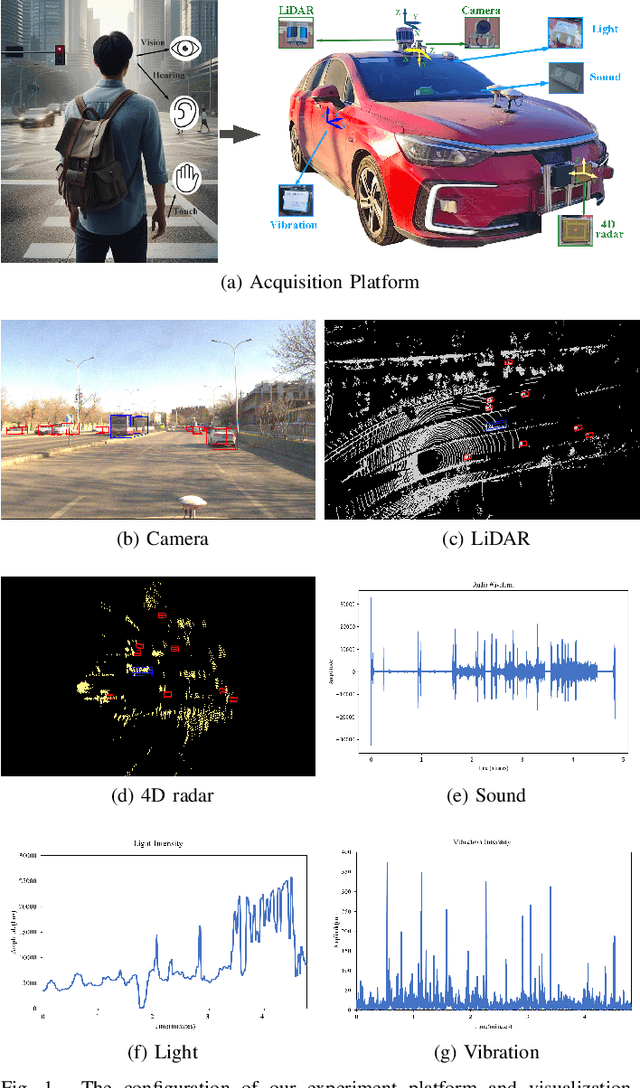
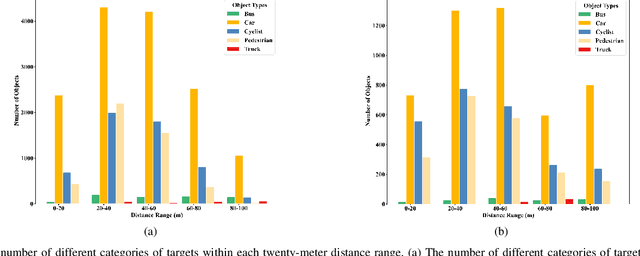
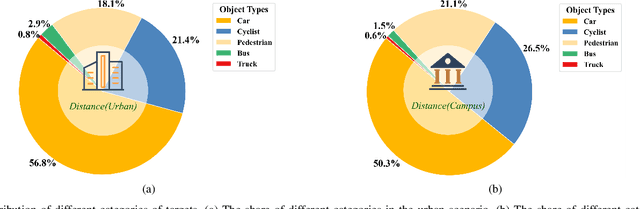
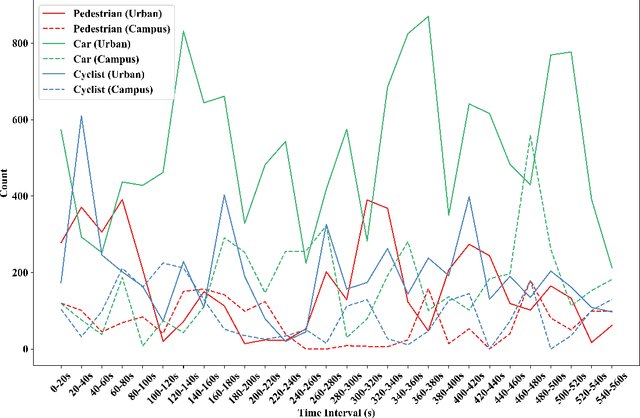
During the process of driving, humans usually rely on multiple senses to gather information and make decisions. Analogously, in order to achieve embodied intelligence in autonomous driving, it is essential to integrate multidimensional sensory information in order to facilitate interaction with the environment. However, the current multi-modal fusion sensing schemes often neglect these additional sensory inputs, hindering the realization of fully autonomous driving. This paper considers multi-sensory information and proposes a multi-modal interactive perception dataset named MIPD, enabling expanding the current autonomous driving algorithm framework, for supporting the research on embodied intelligent driving. In addition to the conventional camera, lidar, and 4D radar data, our dataset incorporates multiple sensor inputs including sound, light intensity, vibration intensity and vehicle speed to enrich the dataset comprehensiveness. Comprising 126 consecutive sequences, many exceeding twenty seconds, MIPD features over 8,500 meticulously synchronized and annotated frames. Moreover, it encompasses many challenging scenarios, covering various road and lighting conditions. The dataset has undergone thorough experimental validation, producing valuable insights for the exploration of next-generation autonomous driving frameworks.
LostNet: A smart way for lost and find
Jan 05, 2023Due to the enormous population growth of cities in recent years, objects are frequently lost and unclaimed on public transportation, in restaurants, or any other public areas. While services like Find My iPhone can easily identify lost electronic devices, more valuable objects cannot be tracked in an intelligent manner, making it impossible for administrators to reclaim a large number of lost and found items in a timely manner. We present a method that significantly reduces the complexity of searching by comparing previous images of lost and recovered things provided by the owner with photos taken when registered lost and found items are received. In this research, we will primarily design a photo matching network by combining the fine-tuning method of MobileNetv2 with CBAM Attention and using the Internet framework to develop an online lost and found image identification system. Our implementation gets a testing accuracy of 96.8% using only 665.12M GLFOPs and 3.5M training parameters. It can recognize practice images and can be run on a regular laptop.