 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchThinker: Scaling Tactile Commonsense Reasoning to the Open World with Large-scale Data and Action-aware Representation
Jun 10, 2026Touch is a key modality for embodied agents to understand the physical world. Although recent work has incorporated tactile signals into language systems for tactile commonsense reasoning, scaling such systems to realistic open-world settings remains challenging due to two key bottlenecks: (1) current tactile reasoning datasets remain limited in format and scale, providing insufficient supervision for reasoning from tactile observations to physical commonsense and hindering the learning of transferable tactile commonsense; (2) Tactile signals are inherently redundant and action-specific, yet existing methods often overlook these properties, resulting in inefficient representations with limited semantic expressiveness. To address these limitations, we propose TouchThinker, a tactile-language framework that scales tactile commonsense reasoning to the open world from both data and representation perspectives. First, we construct TouchThinker-1M, a million-scale, multi-source tactile reasoning dataset covering \textbf{415} objects, \textbf{8} scenarios, and \textbf{7} sensor types, providing a solid data foundation for open-world generalization. We further introduce TouchThinker-Bench, an open-world benchmark with more realistic and diverse tasks. Then, we propose action-aware modeling mechanism to improve tactile representation efficiency and enable efficient reasoning. Experimental results demonstrate that TouchThinker achieves competitive performance against state-of-the-art models across multiple datasets. Our code and dataset will be made available at: https://github.com/lvkailin0118/TouchThinker.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
HS-SLAM: A Fast and Hybrid Strategy-Based SLAM Approach for Low-Speed Autonomous Driving
May 27, 2025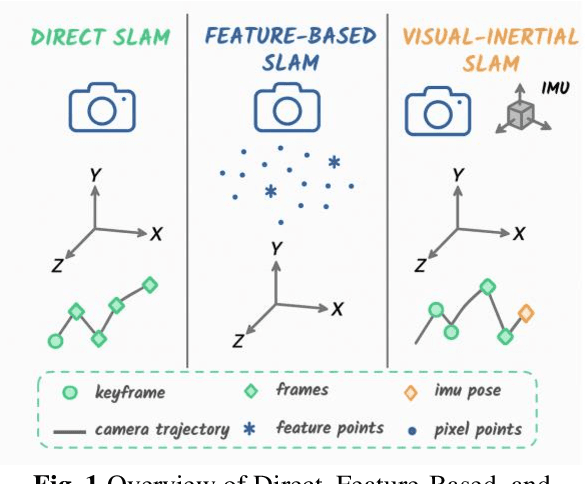


Visual-inertial simultaneous localization and mapping (SLAM) is a key module of robotics and low-speed autonomous vehicles, which is usually limited by the high computation burden for practical applications. To this end, an innovative strategy-based hybrid framework HS-SLAM is proposed to integrate the advantages of direct and feature-based methods for fast computation without decreasing the performance. It first estimates the relative positions of consecutive frames using IMU pose estimation within the tracking thread. Then, it refines these estimates through a multi-layer direct method, which progressively corrects the relative pose from coarse to fine, ultimately achieving accurate corner-based feature matching. This approach serves as an alternative to the conventional constant-velocity tracking model. By selectively bypassing descriptor extraction for non-critical frames, HS-SLAM significantly improves the tracking speed. Experimental evaluations on the EuRoC MAV dataset demonstrate that HS-SLAM achieves higher localization accuracies than ORB-SLAM3 while improving the average tracking efficiency by 15%.
MIPD: A Multi-sensory Interactive Perception Dataset for Embodied Intelligent Driving
Nov 08, 2024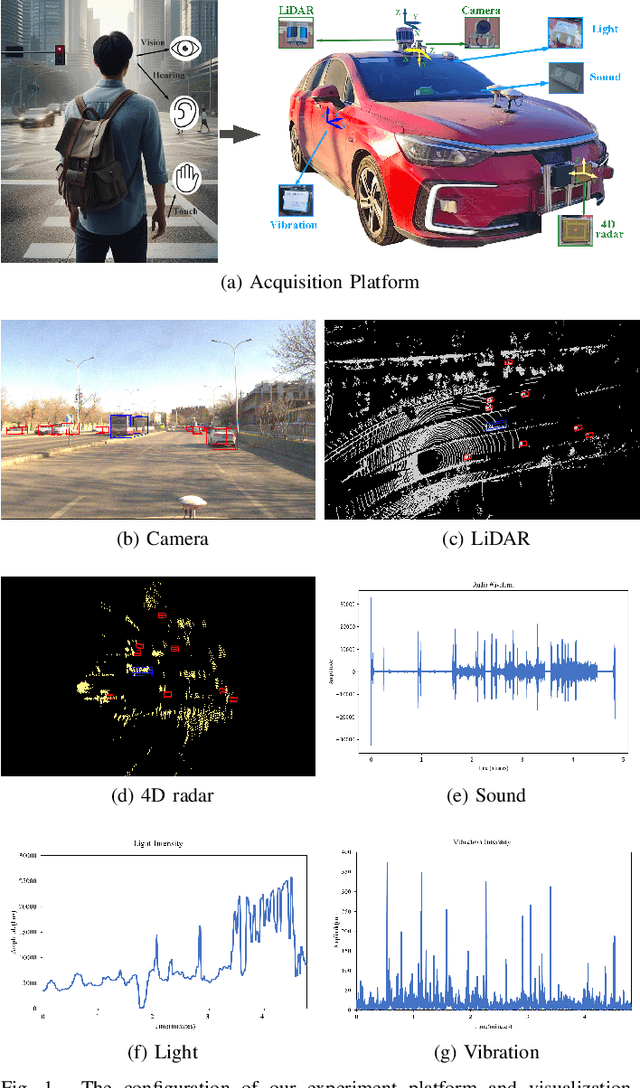
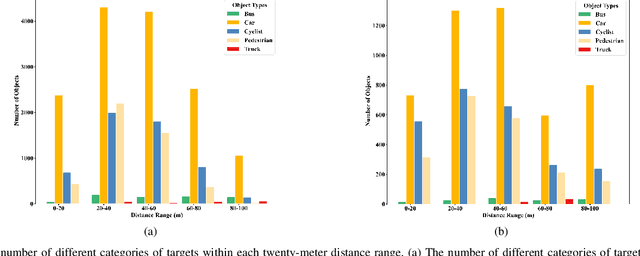
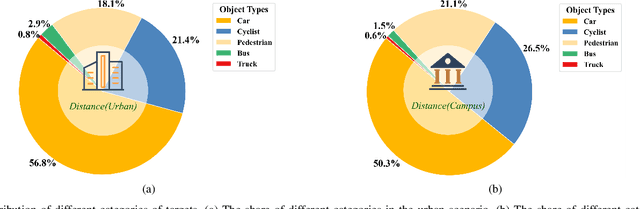
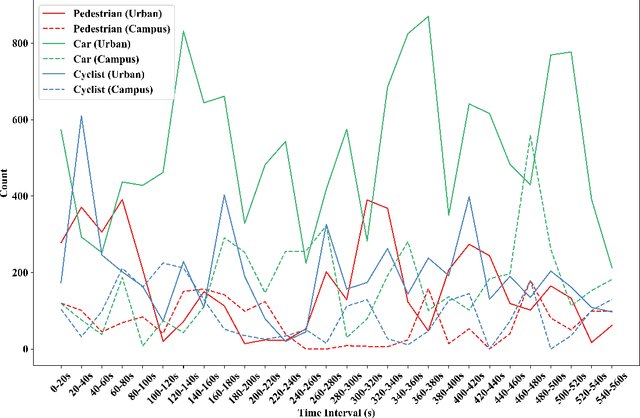
During the process of driving, humans usually rely on multiple senses to gather information and make decisions. Analogously, in order to achieve embodied intelligence in autonomous driving, it is essential to integrate multidimensional sensory information in order to facilitate interaction with the environment. However, the current multi-modal fusion sensing schemes often neglect these additional sensory inputs, hindering the realization of fully autonomous driving. This paper considers multi-sensory information and proposes a multi-modal interactive perception dataset named MIPD, enabling expanding the current autonomous driving algorithm framework, for supporting the research on embodied intelligent driving. In addition to the conventional camera, lidar, and 4D radar data, our dataset incorporates multiple sensor inputs including sound, light intensity, vibration intensity and vehicle speed to enrich the dataset comprehensiveness. Comprising 126 consecutive sequences, many exceeding twenty seconds, MIPD features over 8,500 meticulously synchronized and annotated frames. Moreover, it encompasses many challenging scenarios, covering various road and lighting conditions. The dataset has undergone thorough experimental validation, producing valuable insights for the exploration of next-generation autonomous driving frameworks.
Rate-Perception Optimized Preprocessing for Video Coding
Jan 25, 2023In the past decades, lots of progress have been done in the video compression field including traditional video codec and learning-based video codec. However, few studies focus on using preprocessing techniques to improve the rate-distortion performance. In this paper, we propose a rate-perception optimized preprocessing (RPP) method. We first introduce an adaptive Discrete Cosine Transform loss function which can save the bitrate and keep essential high frequency components as well. Furthermore, we also combine several state-of-the-art techniques from low-level vision fields into our approach, such as the high-order degradation model, efficient lightweight network design, and Image Quality Assessment model. By jointly using these powerful techniques, our RPP approach can achieve on average, 16.27% bitrate saving with different video encoders like AVC, HEVC, and VVC under multiple quality metrics. In the deployment stage, our RPP method is very simple and efficient which is not required any changes in the setting of video encoding, streaming, and decoding. Each input frame only needs to make a single pass through RPP before sending into video encoders. In addition, in our subjective visual quality test, 87% of users think videos with RPP are better or equal to videos by only using the codec to compress, while these videos with RPP save about 12% bitrate on average. Our RPP framework has been integrated into the production environment of our video transcoding services which serve millions of users every day.